- Phonetic symbols in Unicode
-
Unicode supports several phonetic scripts and notations through the existing writing systems and the addition of extra blocks with phonetic characters. These phonetic extras are derived of an existing script, usually Latin, Greek or Cyrillic. In Unicode there is no "IPA script". Apart from IPA, these blocks also contain Uralic Phonetic Alphabet characters.
Apart from regular Latin and Greek characters like m and ɛ, these symbols are in special phonetics blocks:
- IPA Extensions (0250–02AF)
- Spacing Modifier Letters (02B0–02FF)
- Phonetic Extensions (1D00–1D7F)
- Phonetic Extensions Supplement (1D80–1DBF)
- Modifier Tone Letters (A700–A71F)
- Superscripts and Subscripts (2070–209F)
Contents
Phonetic scripts
Phonetic scripts, such as the International Phonetic Alphabet (IPA) make use of letters from other writing systems: most notably Latin, Greek and Cyrillic. Combining diacritics also adds meaning to the phonetic text. Finally, these phonetic alphabets make use of modifier letters. A "modifier letter" is strictly intended not as an independent grapheme but as a modification of the preceding character[1] resulting in a distinct grapheme, notably in the context of the International Phonetic Alphabet. For example, ʰ should not occur on its own but modifies the preceding or following symbol. Thus, tʰ is a single IPA symbol, distinct from t. In practice, however, several of these "modifier letters" are also used as full graphemes, e.g. ʿ as transliterating Semitic ayin or Hawaiian okina, or ˚ transliterating Abkhaz ә.
From Unicode blocks to scripts
Phonetical scripts are encoded in six Unicode blocks.
IPA Extensions (U+0250–02AF)
Not to be confused with Extensions to the IPA.Main article: IPA Extensions (Unicode block)IPA Extensions[1]
Unicode.org chart (PDF)0 1 2 3 4 5 6 7 8 9 A B C D E F U+025x ɐ ɑ ɒ ɓ ɔ ɕ ɖ ɗ ɘ ə ɚ ɛ ɜ ɝ ɞ ɟ U+026x ɠ ɡ ɢ ɣ ɤ ɥ ɦ ɧ ɨ ɩ ɪ ɫ ɬ ɭ ɮ ɯ U+027x ɰ ɱ ɲ ɳ ɴ ɵ ɶ ɷ ɸ ɹ ɺ ɻ ɼ ɽ ɾ ɿ U+028x ʀ ʁ ʂ ʃ ʄ ʅ ʆ ʇ ʈ ʉ ʊ ʋ ʌ ʍ ʎ ʏ U+029x ʐ ʑ ʒ ʓ ʔ ʕ ʖ ʗ ʘ ʙ ʚ ʛ ʜ ʝ ʞ ʟ U+02Ax ʠ ʡ ʢ ʣ ʤ ʥ ʦ ʧ ʨ ʩ ʪ ʫ ʬ ʭ ʮ ʯ Notes - 1.^ As of Unicode version 6.0
Spacing Modifier Letters (U+02B0–02FF)
The characters in the "Spacing Modifier Letters" block are intended as forming a unity with the preceding letter (which they "modify"). E.g. the character U+02B0 ʰ modifier letter small h isn't intended simply as a superscript h (h), but as the mark of aspiration placed after the letter being aspirated, as in pʰ "aspirated voiceless bilabial plosive". The block contains:
- Latin superscript modifier letters: (U+02B0–U+02B8): ʰ aspiration; ʱ breathy voice, murmured; ʲ palatalization; ʳ , ʴ , ʵ , ʶ r-coloring or r-offglides; ʷ labialization; ʸ palatalization, Americanist usage for U+02B2
- Miscellaneous phonetic modifiers: (U+02B9–U+02D7): ʹ ʺ ʻ ʼ ʽ ʾ ʿ ˀ ˁ ˂ ˃ ˄ ˅ ˆ ˇ ˈ ˉ ˊ ˋ ˌ ˍ ˎ ˏ ː ˑ ˒ ˓ ˔ ˕ ˖ ˗
- Spacing clones of diacritics: (U+02D8–U+02DD): ˘ breve; ˙ dot above; ˚ ring above; ˛ ogonek; ˜ small tilde; ˝ double acute accent
- Additions based on 1989 IPA: (U+02DE–U+02E4): ˞ ˟ ˠ ˡ ˢ ˣ ˤ
- Tone letters: (U+02E5–U+02E9): ˥ ˦ ˧ ˨ ˩
- Extended Bopomofo tone marks: U+02E9 ˩ yin departing tone mark; U+02EB ˫ yang departing tone mark
- IPA modifiers: U+02EC ˬ modifier letter voicing, unaspirated
- Other modifier letters: U+02EE ˮ modifier letter double apostrophe for Nenets
- Uralic Phonetic Alphabet (UPA) modifiers: (U+02EF–U+02FF): ˯ ˰ ˱ ˲ ˳ ˴ ˵ ˶ ˷ ˸ ˹ ˺ ˻ ˼ ˽ ˾ ˿
Spacing Modifier Letters[1]
Unicode.org chart (PDF)0 1 2 3 4 5 6 7 8 9 A B C D E F U+02Bx ʰ ʱ ʲ ʳ ʴ ʵ ʶ ʷ ʸ ʹ ʺ ʻ ʼ ʽ ʾ ʿ U+02Cx ˀ ˁ ˂ ˃ ˄ ˅ ˆ ˇ ˈ ˉ ˊ ˋ ˌ ˍ ˎ ˏ U+02Dx ː ˑ ˒ ˓ ˔ ˕ ˖ ˗ ˘ ˙ ˚ ˛ ˜ ˝ ˞ ˟ U+02Ex ˠ ˡ ˢ ˣ ˤ ˥ ˦ ˧ ˨ ˩ ˪ ˫ ˬ ˭ ˮ ˯ U+02Fx ˰ ˱ ˲ ˳ ˴ ˵ ˶ ˷ ˸ ˹ ˺ ˻ ˼ ˽ ˾ ˿ Notes - 1.^ As of Unicode version 6.0
Phonetic Extensions (U+1D00–1D7F)
This block, together with Phonetic Extensions Supplement below, contains:
- Small capitals "ɢ ɪ ɴ ɶ ʀ ʏ ʙ ʜ ʟ"
- Turned small letters "ɐ ɥ ɯ ɹ ɺ ɻ ʇ ʌ ʍ ʎ ʞ ʮ ʯ"
- Extra small capitals "ʁ ʛ ᴀ ᴁ ᴃ ᴄ ᴅ ᴆ ᴇ ᴊ ᴋ ᴌ ᴍ ᴎ ᴏ ᴐ ᴘ ᴙ ᴚ ᴛ ᴜ ᴠ ᴡ ᴢ ᴣ ᴦ ᴧ ᴨ ᴩ ᴪ"
- Letters with palatal hooks "ƫ ᶀ ᶁ ᶂ ᶃ ᶄ ᶅ ᶆ ᶇ ᶈ ᶉ ᶊ ᶋ ᶌ ᶍ ᶎ ᶪ ᶵ"
- Letters with retroflex hooks "ᶏ ᶐ ᶒ ᶓ ᶔ ᶕ ᶖ ᶗ ᶘ ᶙ ᶚ ᶩ ᶯ ᶼ"
Phonetic Extensions[1]
Unicode.org chart (PDF)0 1 2 3 4 5 6 7 8 9 A B C D E F U+1D0x ᴀ ᴁ ᴂ ᴃ ᴄ ᴅ ᴆ ᴇ ᴈ ᴉ ᴊ ᴋ ᴌ ᴍ ᴎ ᴏ U+1D1x ᴐ ᴑ ᴒ ᴓ ᴔ ᴕ ᴖ ᴗ ᴘ ᴙ ᴚ ᴛ ᴜ ᴝ ᴞ ᴟ U+1D2x ᴠ ᴡ ᴢ ᴣ ᴤ ᴥ ᴦ ᴧ ᴨ ᴩ ᴪ ᴫ ᴬ ᴭ ᴮ ᴯ U+1D3x ᴰ ᴱ ᴲ ᴳ ᴴ ᴵ ᴶ ᴷ ᴸ ᴹ ᴺ ᴻ ᴼ ᴽ ᴾ ᴿ U+1D4x ᵀ ᵁ ᵂ ᵃ ᵄ ᵅ ᵆ ᵇ ᵈ ᵉ ᵊ ᵋ ᵌ ᵍ ᵎ ᵏ U+1D5x ᵐ ᵑ ᵒ ᵓ ᵔ ᵕ ᵖ ᵗ ᵘ ᵙ ᵚ ᵛ ᵜ ᵝ ᵞ ᵟ U+1D6x ᵠ ᵡ ᵢ ᵣ ᵤ ᵥ ᵦ ᵧ ᵨ ᵩ ᵪ ᵫ ᵬ ᵭ ᵮ ᵯ U+1D7x ᵰ ᵱ ᵲ ᵳ ᵴ ᵵ ᵶ ᵷ ᵸ ᵹ ᵺ ᵻ ᵼ ᵽ ᵾ ᵿ Notes - 1.^ As of Unicode version 6.0
Phonetic Extensions Supplement (U+1D80–1DBF)
Phonetic Extensions Supplement[1]
Unicode.org chart (PDF)0 1 2 3 4 5 6 7 8 9 A B C D E F U+1D8x ᶀ ᶁ ᶂ ᶃ ᶄ ᶅ ᶆ ᶇ ᶈ ᶉ ᶊ ᶋ ᶌ ᶍ ᶎ ᶏ U+1D9x ᶐ ᶑ ᶒ ᶓ ᶔ ᶕ ᶖ ᶗ ᶘ ᶙ ᶚ ᶛ ᶜ ᶝ ᶞ ᶟ U+1DAx ᶠ ᶡ ᶢ ᶣ ᶤ ᶥ ᶦ ᶧ ᶨ ᶩ ᶪ ᶫ ᶬ ᶭ ᶮ ᶯ U+1DBx ᶰ ᶱ ᶲ ᶳ ᶴ ᶵ ᶶ ᶷ ᶸ ᶹ ᶺ ᶻ ᶼ ᶽ ᶾ ᶿ Notes - 1.^ As of Unicode version 6.0
Modifier Tone Letters (U+A700–A71F)
Modifier Tone Letters[1]
Unicode.org chart (PDF)0 1 2 3 4 5 6 7 8 9 A B C D E F U+A70x ꜀ ꜁ ꜂ ꜃ ꜄ ꜅ ꜆ ꜇ ꜈ ꜉ ꜊ ꜋ ꜌ ꜍ ꜎ ꜏ U+A71x ꜐ ꜑ ꜒ ꜓ ꜔ ꜕ ꜖ ꜗ ꜘ ꜙ ꜚ ꜛ ꜜ ꜝ ꜞ ꜟ Notes - 1.^ As of Unicode version 6.0
Superscripts and Subscripts (U+2070–209F)
Superscripts and Subscripts[1]
Unicode.org chart (PDF)0 1 2 3 4 5 6 7 8 9 A B C D E F U+207x ⁰ ⁱ ⁴ ⁵ ⁶ ⁷ ⁸ ⁹ ⁺ ⁻ ⁼ ⁽ ⁾ ⁿ U+208x ₀ ₁ ₂ ₃ ₄ ₅ ₆ ₇ ₈ ₉ ₊ ₋ ₌ ₍ ₎ U+209x ₐ ₑ ₒ ₓ ₔ ₕ ₖ ₗ ₘ ₙ ₚ ₛ ₜ Notes - 1.^ As of Unicode version 6.0
Semantic phonemes and character names
Unicode includes letters and marks from the International Phonetic Alphabet (IPA) and those supporting other phonetic writing systems too. Essentially these characters are used as graphemes for phonemes. In terms of script or writing system, these phonetic alphabets are basically one writing system. What distinguishes the various phonetic alphabets are their glyphs. However, as with numerals, the UCS often focus more on the presentational forms or glyphs given to these phonemes by the various phonetic alphabets. This is in contrast to the alternate names of these characters provided by Unicode NamesList property which typically reflects the common phoneme semantics shared by those various writing systems regardless of the glyphs used. So these differences manifest in the alternate names given to these characters: the canonical UCS name and the NamesList property names. Similarly, Unicode assignees the value of “Latin” to the script property of many of these characters. However, the primary purpose for these characters inclusion in the character set is to support the various phonetic writing systems. These phonetic writing system, in many ways, constitute a single unified writing system on its own: despite borrowing glyphs from other Latin, Greek and Cyrillic scripts.
This possibly results in a larger than necessary allocation of characters, but it is likely due to the practice where the UCS often inherits character distinctions from other legacy character sets. However, this practice also raises other complications because the vast majority of changes in phonetic alphabets is in altering slightly or even completely changing glyphs. Seldom do these phonetic alphabets alter or change the underlying phonemes those glyphs represent. Such glyph changes would be better handled through font updates than through changes to the UCS and Unicode. The semantic phonemes have been fairly stable for decades: especially in the theoretically potential phonemes from our understanding of human aural anatomy. The phonemes have names like “labiodental flap” while the glyph character might be called “right-hook” in IPA informal usage (“v”). For example, the UCS name for character U+1D18, is a “Latin Letter Small Capital P” while the semantic phoneme name added by Unicode is a “semi-voiced [p]”.
The alternate names provided by UCS and Unicode provide an excellent example of the motivation and benefits of semantic unification like that used for Unihan characters. If the phonemes themselves were semantically encoded in Unicode rather than the glyphs used in one or several semantic alphabets, the text processing would occur independent of its visual presentation. One person could view phoneme writing using a font created with IPA glyphs while another could read the same text with a font created for Americanist phonetic notation glyphs. In performing searches, sorting text and the like, the glyphs representing the phonemes would be independent of the characters. When the various phonetic associations alter the glyphs for a phoneme grapheme, the updates can take place in the fonts used to display the text and not in the underling characters. Archived text would display with the new glyphs simply by selecting the updated font for display.
From IPA to Unicode
Main article: International Phonetic AlphabetConsonants
The following tables indicates the Unicode code point sequences for phonemes as used in the International Phonetic Alphabet. A bold code point indicates that the Unicode chart provides an application note such as "voiced retroflex lateral" for U+026D ɭ latin small letter l with retroflex hook (HTML:
ɭ). An entry in bold italics indicates the character name itself refers to a phoneme such as U+0298 ʘ latin letter bilabial click (HTML:ʘ)Bilabial Labiodental Dental Alveolar Postalveolar Retroflex Labial-palatal Plosive p 0070 b 0062 p̪ 0070 032A b̪ 0062 032A t̪ 0074 032A d̪ 0064 032A t
0074d 0064 ʈ 0288 ɖ 0256 Implosive ɓ̥ 0253 0325 ɓ 0253 ɗ̪ 0257 032A ɗ 0257 * Ejective pʼ 0070 02BC t̪ʼ 0074 032A 02BC tʼ 0074 02BC ʈʼ 0288 02BC Nasal m̥ 006D 0325 m 006D ɱ̊ 0271 030A ɱ 0271 n̪̊ 006E 032A 030A n̪ 006E 032A n̥ 006E 0325 n 006E ɳ̊ 0273 030A ɳ 0273 Trill ʙ 0299 r̥ 0072 0325 r 0072 * Tap or Flap * * ɾ 027E ɽ 027D Lateral flap ɺ 027A * Fricative ɸ 0278 β 03B2 f
0066v 0076 θ 03B8 ð 00F0 s 0073 z 007A ʃ 0283 ʒ 0292 ʂ 0282 ʐ 0290 Lateral fricative ɬ 026C ɮ 026E * Ejective fricative sʼ 0073 02BC ʃʼ 0283 02BC Ejective lateral fricative ɬʼ 026C 02BC Percussive ʬ
02ACʭ
02ADApproximant β̞̊ 03B2 031E 030A β̞ 03B2 031E ʋ̥ 028B 0325 ʋ 028B ð̞ 00F0 031E ɹ̥ 0279 0325 ɹ 0279 ɻ̊ 027B 030A ɻ 027B ɥ̊ 0265 030A ɥ 0265 Lateral approximant l̥ 006C 0325 l 006C ɭ 026D Click consonant ʘ
0298ǀ
01C0ǃ
01C3ǃ / ǂ
01C3 / 01C2Lateral click * ǁ
01C1Alveolo-palatal Palatal Labial-velar Velar Uvular Pharyngeal Epiglottal Glottal Plosive ȶ 0236 ȡ 0221 c 0063 ɟ 025F k͡p 006B 0361 0070 ɡ͡b 0261 0361 0062 k 006B g 0261 q 0071 ɢ 0262 ʡ 02A1 ʔ 0294 Implosive ʄ 0284 ɠ 0260 ʛ 029B Ejective cʼ 0063 02BC kʼ 006B 02BC qʼ 0071 02BC Nasal ȵ 0235 ɲ 0272 ŋ͡m 014B 0361 006D ŋ 014B ɴ 0274 Trill ʀ 0280 * Tap or Flap * Lateral flap * * Fricative ɕ 0255 ʑ 0291 ç 0063 0327 ʝ 029D x 0078 ɣ 0263 χ 03C7 ʁ 0281 ħ 0127 ʕ 0295 ʜ 029C ʢ 02A2 h 0068 ɦ 0266 Approximant j 006A ʍ 028D w 0077 ɰ 0270 Lateral approximant ȴ 0234 ʎ 028E ʟ 029F Vowels
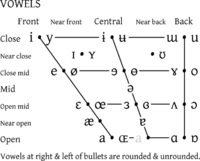
The following figures depict the phonetic vowels and their Unicode / UCS code points. Vowels appearing in pairs in the figure to the right indicate rounded and unrounded variations respectively. Again, characters with Unicode names referring to phonemes are indicated by bold text. Those with explicit application notes are indicated by bold italic text. Those from borrowed unchanged from another script (Latin,, Greek or Cyrillic) are indicated by italics.
Unicode code points for phonetic vowels This table represents the phonetic vowel trapezium
Before and after a bullet are the unrounded · rounded vowels
Close i · y
0069 0079ɨ · ʉ
0268 0289ɯ · u
026F 0075Near-close ɪ · ʏ
026A 028Fɪ̈ · ʊ̈
026A 0308 · 028A 0308· ʊ
028AClose-mid e · ø
0065 00F8ɘ · ɵ
0258 0275ɤ · o
0264 006FMid ə
0259Open-mid ɛ · œ
025B 0153ɜ · ɞ
025C 025Eʌ · ɔ
028C 0254Near-open æ ·
00E6ɐ
0250Open a · ɶ
0061 0276ɑ · ɒ
0251 0252Vowel length marker ː
02D0See also
References
External links
- http://unicode.org/charts/symbols.html
- PhoTransEdit This free software tool translates English texts into IPA phonetics and also exports transcriptions to HTML decimal code numbers.
- Spacing Modifier Letters (everything2.com)
International Phonetic Alphabet IPA topics IPA International Phonetic Association · History of the IPA · Kiel convention (1989) · Journal of the IPA (JIPA) · Naming conventionsPhonetics Special topics Encodings Consonants IPA pulmonic consonants chartchart image • 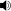 audio
audioPlace → Labial Coronal Dorsal Radical Glottal ↓ Manner Bilabial Labiodental Dental Alveolar Postalv. Retroflex Palatal Velar Uvular Pharyngeal Epiglottal Glottal Nasal m ɱ n̪ n ɳ ɲ ŋ ɴ Plosive p b p̪ b̪ t̪ d̪ t d ʈ ɖ c ɟ k ɡ q ɢ ʡ ʔ Fricative ɸ β f v θ ð s z ʃ ʒ ʂ ʐ ç ʝ x ɣ χ ʁ ħ ʕ ʜ ʢ h ɦ Approximant ʋ ɹ ɻ j ɰ Trill ʙ r ɽ͡r ʀ я * Flap or tap ⱱ̟ ⱱ ɾ ɽ ɢ̆ ʡ̯ Lateral Fric. ɬ ɮ ɭ˔̊ ʎ̥˔ ʟ̝̊ Lateral Appr. l ɭ ʎ ʟ Lateral flap ɺ ɺ̠ ʎ̯ Non-pulmonic consonants Clicks ʘ ǀ ǃ ǂ ǁ Implosives ɓ ɗ ʄ ᶑ ɠ ʛ Ejectives pʼ tʼ cʼ ʈʼ kʼ qʼ fʼ θʼ sʼ ɬʼ xʼ χʼ tsʼ tɬʼ cʎ̝̥ʼ tʃʼ ʈʂʼ kxʼ kʟ̝̊ʼ Affricates p̪f ts dz tʃ dʒ tɕ dʑ ʈʂ ɖʐ tɬ dɮ cç ɟʝ Co-articulated consonants Fricatives ɕ ʑ ɧ Approximants ʍ w ɥ ɫ Stops k͡p ɡ͡b ŋ͡m These tables contain phonetic symbols, which may not display correctly in some browsers. [Help] Where symbols appear in pairs, left—right represent the voiceless—voiced consonants. Shaded areas denote pulmonic articulations judged to be impossible. * Symbol not defined in IPA. Chart image Vowels Vowels: IPA help • chart • chart with audio • viewCategories:- Phonetics
- Unicode blocks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Wikimedia Foundation. 2010.