- Diacritic
-
For the academic journal, see Diacritics (journal).
Diacritical marks
Diacritics accent acute( ´ ) double acute( ˝ ) grave( ` ) double grave( ̏ ) breve( ˘ ) inverted breve( ̑ ) caron / háček( ˇ ) cedilla / cédille( ¸ ) circumflex / vokáň( ˆ ) dot( · ) hook / dấu hỏi( ̉ ) horn / dấu móc( ̛ ) macron( ¯ ) ogonek / nosinė( ˛ ) ring / kroužek( ˚, ˳ ) rough breathing / dasia( ῾ ) smooth breathing / psili( ᾿ ) diaeresis (diaeresis/umlaut)( ¨ ) Marks sometimes used as diacritics apostrophe( ’ ) bar( | ) colon( : ) comma( , ) hyphen( ˗ ) tilde( ~ ) titlo( ҃ ) Diacritical marks in other scripts Arabic diacritics Gurmukhi diacritics Hebrew diacritics Indic diacritics anusvara( ं ং ം ) chandrabindu( ँ ఁ ) nukta( ़ ) virama( ् ് ్ ් ್ ) IPA diacritics Japanese diacritics dakuten( ゙ ) handakuten( ゚ ) Khmer diacritics Syriac diacritics Thai diacritics Related Punctuation marks
A diacritic (
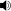 /daɪ.əˈkrɪtɨk/; also diacritical mark, diacritical point, diacritical sign) is a glyph added to a letter, or basic glyph. The term derives from the Greek διακριτικός (diakritikós, "distinguishing"). Diacritic is both an adjective and a noun, whereas diacritical is only an adjective. Some diacritical marks, such as the acute ( ´ ) and grave ( ` ) are often called accents. Diacritical marks may appear above or below a letter, or in some other position such as within the letter or between two letters.
/daɪ.əˈkrɪtɨk/; also diacritical mark, diacritical point, diacritical sign) is a glyph added to a letter, or basic glyph. The term derives from the Greek διακριτικός (diakritikós, "distinguishing"). Diacritic is both an adjective and a noun, whereas diacritical is only an adjective. Some diacritical marks, such as the acute ( ´ ) and grave ( ` ) are often called accents. Diacritical marks may appear above or below a letter, or in some other position such as within the letter or between two letters.The main use of diacritics in the Latin alphabet is to change the sound value of the letter to which they are added. Examples from English are the diaeresis in naïve and Noël, which show that the vowel with the diaeresis mark is pronounced separately from the preceding vowel; the acute and grave accents, which indicate that a final vowel is to be pronounced, as in saké and poetic breathèd, and the cedilla under the "c" in the borrowed French word façade, which shows it is pronounced /s/ rather than /k/. In other Latin alphabets, they may distinguish between homonyms, such as French là "there" versus la "the," which are both pronounced [la]. In Gaelic type, a dot over consonants indicates lenition of the consonant in question. In other alphabetic systems, diacritics may perform other functions. Vowel pointing systems, namely the Arabic harakat ( ـَ, ـُ, ـُ, etc.) and the Hebrew niqqud ( ַ, ֶ, ִ, ֹ , ֻ, etc.) systems, indicate sounds (vowels and tones) that are not conveyed by the basic alphabet. The Indic virama ( ् etc.) and the Arabic sukūn ( ـْـ ) mark the absence of a vowel. Cantillation marks indicate prosody. Other uses include the Early Cyrillic titlo ( ◌҃ ) and the Hebrew gershayim ( ״ ), which, respectively, mark abbreviations or acronyms, and Greek diacritics, which showed that letters of the alphabet were being used as numerals.
In orthography and collation, a letter modified by a diacritic may be treated either as a new, distinct letter or as a letter–diacritic combination. This varies from language to language, and may vary from case to case within a language.
In some cases, letters are used as "in-line diacritics" in place of ancillary glyphs, because they modify the sound of the letter preceding them, as in the case of the "h" in English "sh" and "th".[1]
Contents
Types
Among the types of diacritic used in alphabets based on the Latin script are:
- accent marks (thus called because the acute, the grave and the circumflex accent were originally used to indicate different types of pitch accents, in the polytonic transcription of Greek)
- ◌́ – acute accent (Latin apex)
- ◌̀ – grave accent
- ◌̂ – circumflex accent (Slovak vokáň)
- ◌̌ – caron, inverted circumflex, (Czech háček, Slovak mäkčeň, Slovene strešica, Lakota ičášleče)
- ◌̋ – double acute accent
- ◌̏ – double grave accent
- dots
- ◌̇ – dot (Indic anusvara)
- ◌̣ – a dot below is used in Rheinische Dokumenta
- ◌·◌ – Interpunct
- tittle, the dot used by default in the modern lowercase form of the Latin letters "i" and "j"
- ◌̈ – trema, diaeresis, or umlaut sign
- ◌ː – colon, used in the International Phonetic Alphabet to mark long vowels.
- ring
- ◌̊ – ring (Swedish kål, Czech kroužek as in 'kůl')
- vertical line
- ◌̩ – a vertical line below is used in Rheinische Dokumenta as a schwa mark
- macron or horizontal line
- ◌̄ – macron (Hawaiian kahakō, Māori tohutō)
- ◌̱ – macron below
- overlays
- curves
- curls above
- curls below
- double marks (over or under two base characters)
- ◌͝◌ – double breve
- ◌͡◌ – ligature tie
- ◌᷍◌ – double circumflex
- ◌͞◌ – double macron
- ◌͠◌ – double tilde
The tilde, dot, comma, titlo, apostrophe, bar, and colon are sometimes diacritics, but also have other uses.
Not all diacritics occur adjacent to the letter they modify. In the Wali language of Ghana, for example, an apostrophe indicates a change of vowel quality, but occurs at the beginning of the word, as in the dialects ’Bulengee and ’Dolimi. Because of vowel harmony, all vowels in a word are affected, so the scope of the diacritic is the entire word. In abugida scripts, like those used to write Hindi and Thai, diacritics indicate vowels, and may occur above, below, before, after, or around the consonant letter they modify.
The dot on the letter i of the Latin alphabet originated as a diacritic to clearly distinguish i from the vertical strokes of the adjacent letters. It first appeared in the sequence ii (as in ingeníí) in Latin manuscripts of the 11th century, then spread to i adjacent to m, n, u, and later spread to all lower-case i. The j, which separated from the i later, inherited the "dot". The shape of the diacritic developed from initially resembling today's acute accent to a long flourish by the 15th century. With the advent of Roman type it was reduced to the round dot we have today.[2]
Diacritics specific to non-Latin alphabets
Arabic
Further information: Arabic diacritics- (ئ ؤ إ أ and stand alone ء) hamza: indicates a glottal stop.
- (ــًــٍــٌـ) tanwīn (تنوين) symbols: Serve a grammatical role in Arabic. The sign ـً is most commonly written in combination with alif, e.g. ـًا.
- (ــّـ) shadda: Gemination (doubling) of consonants.
- (ٱ) waṣla: Comes most commonly at the beginning of a word. Indicates a type of hamza that is pronounced only when the letter is read at the beginning of the talk.
- (آ) madda: A written replacement for a hamza that is followed by an alif, i.e. (ءا). Read as a glottal stop followed by a long /aː/, e.g. ءاداب، ءاية، قرءان، مرءاة are written out respectivially as آداب، آية، قرآن، مرآة. This writing rule does not apply when the alif that follows a hamza is not a part of the stem of the word, e.g. نتوءات is not written out as نتوآت as the stem نتوء does not have an alif that follows its hamza.
- (ــٰـ) superscript alif (also "short" or "dagger alif": A replacement for an original alif that is dropped in the writing out of some rare words, e.g. لاكن is not written out with the original alif found in the word pronunciation, instead it is written out as لٰكن.
- ḥarakāt (In Arabic: حركات also called تشكيل tashkīl):
- (ــَـ) fatḥa (a)
- (ــِـ) kasra (i)
- (ــُـ) ḍamma (u)
- (ــْـ) sukūn (no vowel)
- The ḥarakāt or vowel points serve two purposes:
- They serve as a phonetical guide. They indicate the presence of short vowels (fatḥa, kasra, or ḍamma) or their absence (sukūn).
- At the last letter of a word, the vowel point reflects the inflection case or conjugation mood.
- For nouns, The ḍamma is for the nominative, fatḥa for the accusative, and kasra for the genitive.
- For verbs, the ḍamma is for the imperfective, fatḥa for the perfective, and the sukūn is for verbs in the imperative or jussive moods.
- Vowel points or tashkīl should not be confused with consonant points or iʿjam (إعجام) – one, two or three dots written above or below a consonant to distinguish between letters of the same or similar form.
Greek
Further information: Greek diacriticsThese diacritics are used in addition to the acute, grave, and circumflex accents and the diaeresis:
- ◌ͺ (ᾳ) – iota subscript
- ῾◌ – rough breathing (spiritus asper): aspiration
- ᾿◌ – smooth (or soft) breathing (spiritus lenis): lack of aspiration
Hebrew
Further information: Hebrew diacritics Gen. 1:9 "And God said, Let the waters be collected".
Gen. 1:9 "And God said, Let the waters be collected".
Letters in black, niqqud in red, cantillation in blue- Cantillation marks do not generally render correctly; refer to Cantillation#Names and shapes of the ta'amim for a complete table together with instructions for how to maximize the possibility of viewing them in a web browser
- Other
Korean
 Hunminjeongeum, the Korean alphabet
Hunminjeongeum, the Korean alphabetThese diacritics, known as Bangjeom (방점;傍點), were used to mark pitch accents in Hangul for Middle Korean. It is written to the left of a character in vertical writing and above a character in horizontal writing.
- 〮, 〯
Sanskrit
Further information: Brahmic scriptsNon-alphabetic scripts
Some non-alphabetic scripts also employ symbols that function essentially as diacritics.
- Non-pure abjads (such as Hebrew and Arabic script) and abugidas use diacritics for denoting vowels. Hebrew and Arabic also indicate consonant doubling and change with diacritics; Hebrew and Devanagari use them for foreign sounds. Devanagari and related abugidas also use a diacritical mark called a virama to mark the absence of a vowel. In addition, Devanagari uses the moon-dot chandrabindu ( ँ ).
- The Japanese hiragana and katakana syllabaries use the dakuten (◌゛) and handakuten (◌゜) (in Japanese: 濁点 and 半濁点) symbols, also known as nigori (濁) or ten-ten (点々) and maru (丸), to indicate voiced consonants or other phonetical changes.
- Emoticons are commonly created with diacritic symbols, especially Japanese emoticons on popular imageboards.
Alphabetization or collation
Main article: CollationDifferent languages use different rules to put diacritic characters in alphabetical order. French treats letters with diacritical marks the same as the underlying letter for purposes of ordering and dictionaries.
The Scandinavian languages, by contrast, treat the characters with diacritics ä, ö and å as new and separate letters of the alphabet, and sort them after z. Usually ä is sorted as equal to æ (ash) and ö is sorted as equal to ø (o-slash). Also, aa, when used as an alternative spelling to å, is sorted as such. Other letters modified by diacritics are treated as variants of the underlying letter, with the exception that ü is frequently sorted as y.
Languages that treat accented letters as variants of the underlying letter usually alphabetize words with such symbols immediately after similar unmarked words. For instance, in German where two words differ only by an umlaut, the word without it is sorted first in German dictionaries (e.g. schon and then schön, or fallen and then fällen). However, when names are concerned (e.g. in phone books or in author catalogues in libraries), umlauts are often treated as combinations of the vowel with a suffixed e; Austrian phone books now treat characters with umlauts as separate letters (immediately following the underlying vowel).
In Spanish, the grapheme ñ is considered a new letter different from n and collated between n and o, as it denotes a different sound from that of a plain n. But the accented vowels á, é, í, ó, ú are not separated from the unaccented vowels a, e, i, o, u, as the acute accent in Spanish only modifies stress within the word or denotes a distinction between homonyms, and does not modify the sound of a letter.
For a comprehensive list of the collating orders in various languages, see Collating sequence.
Generation with computers
Modern computer technology was developed mostly in the English-speaking countries, so data formats, keyboard layouts, etc. were developed with a bias favoring English, a language with an alphabet without diacritical marks. This has led to fears internationally that the marks and accents may be made obsolete to facilitate the worldwide exchange of data.[citation needed] Efforts have been made to create internationalized domain names that further extend the English alphabet (e.g., "pokémon.com").
Depending on the keyboard layout, which differs amongst countries, it is more or less easy to enter letters with diacritics on computers and typewriters. Some have their own keys; some are created by first pressing the key with the diacritic mark followed by the letter to place it on. Such a key is sometimes referred to as a dead key, as it produces no output of its own, but modifies the output of the key pressed after it.
In modern Microsoft Windows and Linux operating systems, the keyboard layouts US International and UK International feature dead keys that allow one to type Latin letters with the acute, grave, circumflex, diæresis, tilde, and cedilla found in Western European languages (specifically, those combinations found in the ISO Latin-1 character set) directly: "+e gives ë, ~+o gives õ, etc. On Apple Macintosh computers, there are keyboard shortcuts for the most common diacritics; Option-e followed by a vowel places an acute accent, Option-u followed by a vowel gives an umlaut, option-c gives a cedilla, etc. Diacritics can be composed in most X Window System keyboard layouts, as well as other operating systems, such as Microsoft Windows, using additional software.
On computers, the availability of code pages determines whether one can use certain diacritics. Unicode solves this problem by assigning every known character its own code; if this code is known, most modern computer systems provide a method to input it. With Unicode, it is also possible to combine diacritical marks with most characters.
Languages with letters containing diacritics
The following languages have letters that contain diacritics that are considered independent letters distinct from those without diacritics.
- Germanic
-
- Faroese uses acute accents and other special letters. All are considered separate letters and have their own place in the alphabet: á, í, ó, ú, ý, and ø.
- Icelandic uses acute accents and other special letters. All are considered separate letters, and have their own place in the alphabet: á, é, í, ó, ú, ý, and ö.
- Danish and Norwegian uses additional characters like the o-slash ø and the a-circle å. These letters are collated after z and æ, in the order ø, å. Historically the å has developed from a ligature by writing a small a on top of the letter a; if an å character is unavailable, some Scandinavian languages allow the substitution of a doubled a. The Scandinavian languages collate these letters after z, but have different collation standards.
- Swedish uses characters identical to a-umlaut (ä) and o-umlaut (ö) in the place of ash and o-slash in addition to the a-circle (å). Historically the umlaut for the Swedish letters ä and ö, like the German umlaut, has developed from a small gothic e written on top of the letters. These letters are collated after z, in the order å, ä, ö.
- Celtic
-
- Irish uses acute accents, called fadas. Fadas are used to indicate vowel length. These are the following vowels á, é, í, ó, ú.
- Welsh uses the circumflex, diaeresis, acute and grave accents on its seven vowels a, e, i, o, u, w, y.
- Following orthographic reforms since the 1970s, Scottish Gaelic uses grave accents only, which can be used on any vowel (à, è, ì, ò, ù). Formerly acute accents could be used on á, ó and é, which were used to indicate a specific vowel quality. With the elimination of these accents, the new orthography relies on the reader having prior knowledge of pronunciation of a given word.
- Manx uses the single diacritic ç combined with h to give the digraph <çh> (pronounced /tʃ/) to mark the distinction between it and the digraph <ch> (pronounced /h/ or /x/). Other diacritics used in Manx included â, ê, ï, etc. to mark the distinction between two similarly spelled words but with slightly differing pronunciation.
- Some orthographies of Cornish such as Kernowek Standard and Unified Cornish use diacritics, while others such as Kernewek Kemmyn and the Standard Written Form do not.
- Romance
-
- Asturian, Galician and Spanish, the character ñ is a letter and collated between n and o
- Asturian uses Ḷ (lower case ḷ), and Ḥ (lower case ḥ)[3]
- Leonese: could use ñ or nn.
- Romanian uses a breve on the letter a (ă) to indicate the sound schwa /ə/, as well as a circumflex over the letters a (â) and i (î) for the sound /ɨ/. Romanian also writes a comma below the letters s (ș) and t (ț) to represent the sounds /ʃ/ and /t͡s/, respectively. These characters are collated after their non-diacritic equivalent.
- Slavic
-
- Bosnian, Croatian, and Serbian latin alphabet have the symbols č, ć, đ, š and ž, which are considered separate letters and are listed as such in dictionaries and other contexts in which words are listed according to alphabetical order. Bosnian and Croatian also have one digraph including a diacritic, dž, which is also alphabetised independently, and follows d and precedes đ in the alphabetical order. The Serbian Cyrillic alphabet has no diacritics.
- The Czech alphabet contains 27 graphemes (letters) when written without diacritics and 42 graphemes when written including them. Czech uses the acute (á é í ó ú ý), caron (č ď ě ň ř š ť ž), and for one letter (ů) the ring.
- Polish has the following letters: ą ć ę ł ń ó ś ź ż. These are considered to be separate letters, each of them is placed in alphabet right after its Latin counterpart (i.e. ą between a and b), ź and ż are placed after z in this order.
- The Slovak alphabet uses the acute (á é í ó ú ý ĺ ŕ), caron (č ď ľ ň š ť ž), umlaut (ä) and circumflex accent (ô).
- The Slovene alphabet has the symbols č, š and ž, which are considered separate letters and are listed as such in dictionaries and other contexts in which words are listed according to alphabetical order.
- Baltic
-
- Latvian has the following letters: ā ē ī ū ŗ ļ ķ ņ ģ š ž č.
- Lithuanian. In general usage, where letters appear with the caron (č, š and ž) they are considered as separate letters from c, s or z and collated separately; letters with the ogonek (ą, ę, į and ų), the macron (ū) and the superdot (ė) are considered as separate letters as well, but not given a unique collation order.
- Finno-Ugric
-
- Estonian has a distinct letter õ, which contains a tilde. Estonian "dotted vowels" ä, ö, ü are similar to German, but these are also distinct letters, not like German umlauted letters. All four have their own place in the alphabet, between w and x. Carons in š or ž appear only in foreign proper names and loanwords. Also these are distinct letters, placed in the alphabet between s and t.
- Finnish uses dotted vowels (ä and ö). As in Swedish and Estonian, these are regarded as individual letters, rather than vowel + umlaut combinations (as happens in German). It also uses the characters å, š and ž in foreign names and loanwords. In the Finnish and Swedish alphabets, å, ä and ö collate as separate letters after z, the others as variants of their base letter.
- Hungarian uses the umlaut, the acute and double acute accent (unique to Hungarian): ö ü, á é í ó ú and ő ű. The acute accent indicates the long form of a vowel (in case of i/í, o/ó, u/ú) while the double acute performs the same function for ö and ü. The acute accent can also indicate a different sound (more open, like in case of a/á, e/é). Both long and short forms of the vowels are listed separately in the Hungarian alphabet but members of the pairs a/á, e/é, i/í, o/ó, ö/ő, u/ú and ü/ű are collated in dictionaries as the same letter.
- Livonian has the following letters: ā, ä, ǟ, ḑ, ē, ī, ļ, ņ, ō, ȯ, ȱ, õ, ȭ, ŗ, š, ț, ū, ž.
- Turkic
-
- Azerbaijani includes the distinct Turkish alphabet letters Ç, Ğ, I, İ, Ö, Ş and Ü.
- Crimean Tatar includes the distinct Turkish alphabet letters Ç, Ğ, I, İ, Ö, Ş and Ü. Unlike Standard Turkish (but like Cypriot Turkish), Crimean Tatar also has the letter Ñ.
- Gagauz includes the distinct Turkish alphabet letters Ç, Ğ, I, İ, Ö and Ü. Unlike Turkish, Gagauz also has the letters Ä, Ê Ș and Ț. Ș and Ț are derived from the Romanian alphabet for the same sounds. Sometime the turkish Ş may be used instead.
- Turkish uses a G with a breve (Ğ), two letters with an umlaut (Ö and Ü, representing two rounded front vowels), two letters with a cedilla (Ç and Ş, representing the affricate /tʃ/ and the fricative /ʃ/), and also possesses a dotted capital İ (and a dotless lowercase ı representing a high unrounded back vowel). In Turkish each of these are separate letters, rather than versions of other letters, where dotted capital İ and lower case i are the same letter, as are dotless capital I and lowercase ı. Typographically, Ç and Ş are often rendered with a subdot, as in Ṣ; when a hook is used, it tends to have more a comma shape than the usual cedilla. The new Azerbaijani, Crimean Tatar, and Gagauz alphabets are based on the Turkish alphabet and its same diacriticized letters, with some additions.
- Other
-
- Albanian has two special letters Ç and Ё upper and lowercase. They are placed next to the most similar letters in the alphabet, c and e correspondingly.
- Esperanto has the symbols ŭ, ĉ, ĝ, ĥ, ĵ and ŝ, which are included in the alphabet, and considered separate letters.
- Hawaiian uses the kahakô (macron) over vowels, although there is some disagreement over considering them as individual letters. The kahakô over a vowel can completely change the meaning of a word that is spelled the same but without the kahakô.
- Kurdish uses the symbols Ç, Ê, Î, Ş and Û with other 26 standard Latin alphabet symbols.
- Maltese uses a C, G, and Z with a dot over them (Ċ, Ġ, Ż), and also has an H with an extra horizontal bar. For uppercase H, the extra bar is written slightly above the usual bar. For lowercase H, the extra bar is written crossing the vertical, like a t, and not touching the lower part (Ħ, ħ). The above characters are considered separate letters. The letter 'c' without a dot has fallen out of use due to redundancy. 'Ċ' is pronounced like the English 'ch' and 'k' is used as a hard c as in 'cat'. 'Ż' is pronounced just like the english 'Z' as in 'Zebra', while 'Z' is used to make the sound of 'ts' in English (like 'tsunami' or 'maths'). 'Ġ' is used as a hard 'G' like in 'geometry', while the 'G' sounds like a soft 'G' like in 'log'. The digraph 'għ' (called għajn after the Arabic letter name ʻayn for غ) is considered separate, and sometimes ordered after 'g', whilst in other volumes it is placed between 'n' and 'o' (the Latin letter 'o' originally evolved from the shape of Phoenician ʻayin, which was traditionally collated after Phoenician nūn).
- Vietnamese uses the horn diacritic for the letters ơ and ư; the circumflex for the letters â, ê, and ô; the breve for the letter ă; and a bar through the letter đ.
- Lakota alphabet uses the caron for the letters č, ȟ, ǧ, š, and ž. It also uses the acute accent for stressed vowels á, é, í, ó, ú, áŋ, íŋ, úŋ.
- Cyrillic alphabets
-
- Belarusian has a letter ў.
- Belarusian, Bulgarian, Russian and Ukrainian have the letter й.
- Belarusian and Russian have the letter ё. In Russian, this letter is usually replaced in print by е, although it has a different pronunciation. The use of е instead of ё in print does not affect the pronunciation. Ё is still used in children's books and in handwriting, is always used in dictionaries. A minimal pair is все (vse, "all" pl.) and всё (vsyo, "everything" n. sg.). In Belarusian the replacement by е is a mistake, in Russian, it is possible to use either е and ё in print in place of ё but the former is more common.
- The Cyrillic Ukrainian alphabet has the letters й and ї. Ukrainian Latynka has many more.
- Macedonian has the letters ќ and ѓ.
- In Bulgarian the possessive pronoun ѝ (ì, "her") is spelled with a grave accent in order to distinguish it from the conjunction и (i, "and").
- The acute accent " ́" above any vowel in Cyrillic alphabets is used in dictionaries, books for children and foreign learners to indicate the word stress, it also can be used for disambiguation of similarly spelled words with different lexical stresses.
Diacritics that do not produce new letters
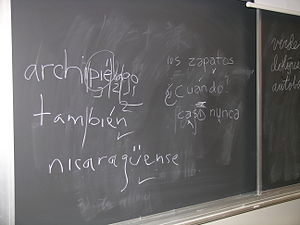 Blackboard used in class at Harvard shows students' efforts at placing the ü and acute accent diacritic used in Spanish orthography.
Blackboard used in class at Harvard shows students' efforts at placing the ü and acute accent diacritic used in Spanish orthography.Non-English languages
The following languages have letter-diacritic combinations that are not considered independent letters.
- Afrikaans uses diaeresis to mark vowels that are pronounced separately and not as one would expect where they occur together, for example voel (to feel) as opposed to voël (bird). The circumflex is used in ê, î, ô and û generally to indicate long close-mid, as opposed to open-mid vowels, for example in the words wêreld (world) and môre (morning, tomorrow). The acute accent is used to add emphasis in the same way as underlining or writing in bold or italics in English, for example Dit is jóú boek (It is your book). The grave accent is used to distinguish between words that are different only in placement of the stress, for example appel (apple) and appèl (appeal) and in a few cases where it makes no difference to the pronunciation but distinguishes between homophones. The two most usual cases of the latter are the in the sayings òf... òf (either... or) and nòg... nòg (neither... nor) to distinguish them from of (or) and nog (again, still).
- Aymara uses a diacritical horn over p, q, t, k, ch.
- Bengali uses different sorts of diacritics, called matra of the elements in set of vowels called the shôrobôrno, for instance, কা is the aakaar or আ-kar of ক.
- Catalan has the following composite characters: à, ç, é, è, í, ï, ó, ò, ú, ü, l·l. The acute and the grave accent indicate stress and vowel height, the cedilla marks the result of a historical palatalization, the diaeresis mark indicates either a hiatus, or that the letter u is pronounced when the graphemes gü, qü are followed by e or i, the interpunct (·) distinguishes the different values of ll/l·l.
- Czech has the acute á, é, í, ó, ú, ý, the caron č, ď, ě, ň, ř, š, ť, ž, and the ring ů.
- Dutch uses the diaeresis. For example in ruïne it means that the u and the i are separately pronounced in their usual way, and not in the way that the combination ui is normally pronounced. Thus it works as a separation sign and not as an indication for an alternative version of the i. Diacritics can be used for emphasis (érg koud for very cold) or for disambiguation between a number of words that are spelled the same when context doesn't indicate the correct meaning (één appel = one apple, een appel = an apple; vóórkomen = to occur, voorkómen = to prevent). Grave and acute accents are used on a very small number of words, mostly loanwords. The ç also appears in some loanwords.
- Faroese. Non-Faroese accented letters are not added to the Faroese alphabet. These include é, ö, ü, å and recently also letters like š, ł, and ć.
- Filipino has the following composite characters: á, à, â, é, è, ê, í, ì, î, ó, ò, ô, ú, ù, û. The actual use of diacritics for Filipino, however, is rare.
- Finnish. Carons in š and ž appear only in foreign proper names and loanwords, but may be substituted with sh or zh if and only if it is technically impossible to produce accented letters in the medium. Contrary to Estonian, š and ž are not considered distinct letters in Finnish.
- French uses the grave accent (accent grave), the acute accent (accent aigu), the circumflex (accent circonflexe), the cedilla (cédille), and the diaeresis (tréma).
- Galician vowels can bear an acute accent (á, é, í, ó, ú) to indicate stress or difference between two otherwise same written words (é, '(he/she) is' vs. e, 'and'), but trema is only used with ï and ü to show diaeresis in pronunciation. Only in foreign words Galician may use of another diacritics as ç (widely used in the Middle Age) ê or à.
- German uses the three so-called umlauts ä, ö and ü. These diacritics indicate vowel changes. For instance the word Ofen [ˈoːfən] (English: oven) has the plural Öfen [ˈøːfən] (ovens). The sign originated in a superscript e; a handwritten Sütterlin e resembles two parallel vertical lines, like an umlaut. In old German texts, we see the letter "Y", when being pronounced [y] written as "ÿ". For example "Babÿlon."
- Hebrew has many various diacritic marks known as niqqud that are used above and below script to represent vowels. These must be distinguished from cantillation, which are keys to pronunciation and syntax.
- The International Phonetic Alphabet uses diacritic symbols and diacritic letters to indicate phonetic features or secondary articulations.
- Irish uses acute accent to indicate that the vowel is long. It is known as síneadh fada (long sign) or simply fada (long) in Irish. Historically, a dot was positioned above certain consonants to signify Séimhiú, however this has largely been replaced by the usage of the letter H, although this dot can still be seen in Gaelic Script.
- Italian mainly has the acute and the grave (à, è/é, ì, ò/ó, ù), typically to indicate a stressed syllable that would not be stressed under the normal rules of pronunciation but sometimes also to distinguish between words that are otherwise spelled the same way (e.g. "e", and; "è", is). Despite its rare use, Italian ortography allows the circumflex accent (î) too, in two cases: it can be found in old literary context (roughly up to 19th century) to signal a syncope (fêro→fecero, they did), or in modern Italian to signal the contraction of ″-ii″ due to the plural ending -i whereas the root ends with another -i; e.g., s. demonio, p. demonii→demonî; in this case the circumflex also signals that the word intended is not demoni, plural of "demone" by shifting the accent (demònî, "devils"; dèmoni, "demons").
- Lithuanian uses the acute, grave and tilde in dictionaries to indicate stress types in the language's pitch accent system.
- Maltese sometimes uses diacritics on some vowels to indicate stress or long vowels, but this is restricted to pronunciation assistance in dictionaries.
- Occitan has the following composite characters: á, à, ç, é, è, í, ï, ó, ò, ú, ü, n·h, s·h. The acute and the grave accent indicate stress and vowel height, the cedilla marks the result of a historical palatalization, the diaeresis mark indicates either a hiatus, or that the letter u is pronounced when the graphemes gü, qü are followed by e or i, the interpunct (·) distinguishes the different values of nh/n·h and sh/s·h.
- Portuguese has the following composite characters: à, á, â, ã, ç, é, ê, í, ó, ô, õ, ú. The acute and the circumflex accent indicate stress and vowel height, the grave accent indicates crasis, the tilde represents nasalization, and the cedilla marks the result of a historical palatalization. Portuguese has also made use of the following composite characters: "è, ì, ò, ù, ï, ü", but have come to be abolished during the last 5 orthographic reforms occurring between 1911 and 2011.
- Acute accents are also used in Slavic language dictionaries and textbooks to indicate lexical stress, placed over the vowel of the stressed syllable. This can also serve to disambiguate meaning (e.g., in Russian писа́ть (pisáť) means "to write", but пи́сать (písať) means "to piss"), or "бо́льшая часть" (the biggest part) vs "больша́я часть" (the big part).
- Slovak has the acute (á, é, í, ĺ, ó, ŕ, ú, ý), the caron (č, ď, dž, ľ, ň, š, ť, ž), the circumflex (only above o – ô) and the diaeresis (only above a – ä).
- Spanish uses the acute accent and the diaeresis. The acute is used on a vowel in a stressed syllable in words with irregular stress patterns. It can also be used to "break up" a diphthong as in tío (pronounced [ˈti.o], rather than [ˈtjo] as it would be without the accent). Moreover, the acute can be used to distinguish words that otherwise are spelt alike, such as si ("if") and sí ("yes"), and also to distinguish interrogative and exclamative pronouns from homophones with a different grammatical function, such as donde/¿dónde? ("where"/"where?") or como/¿cómo? ("as"/"how?"). The diaeresis is used only over u (ü) for it to be pronounced [w] in the combinations gue and gui, where u is normally silent, for example ambigüedad. In poetry, the diaeresis may be used on i and u as a way to force a hiatus.
- Swedish uses the acute accent to show non-standard stress, for example in kafé (café) and resumé (résumé). This occasionally helps resolve ambiguities, such as ide (hibernation) versus idé (idea). In these words, the acute accent is not optional. Some proper names use non-standard diacritics, such as Carolina Klüft and Staël von Holstein. For foreign loanwords the original accents are strongly recommended, unless the word has been infused into the language, in which case they are optional. Hence crème fraîche but ampere.
- Tamil does not have any diacritics in itself, but uses the Hindu numerals 2, 3 and 4 as diacritics to represent aspirated, voiced, and voiced-aspirated consonants when the Tamil script is used to write long passages in Sanskrit.
- Thai has its own system of diacritics derived from Indian numerals, which denote different tones.
- Vietnamese uses the acute accent (dấu sắc), the grave accent (dấu huyền), the tilde (dấu ngã), the dot below (dấu nặng) and the hook (dấu hỏi) on vowels as tone indicators.
- Welsh uses the circumflex, diaeresis, acute and grave accents on its seven vowels a, e, i, o, u, w, y. The most common is the circumflex (which it calls to bach, meaning "little roof", or acen grom "crooked accent", or hirnod "long sign") to denote a long vowel, usually to disambiguate it from a similar word with a short vowel. The rarer grave accent has the opposite effect, shortening vowel sounds that would usually be pronounced long. The acute accent and diaeresis are also occasionally used, to denote stress and vowel separation respectively. The w-circumflex and the y-circumflex are among the most commonly accented characters in Welsh, but unusual in languages generally, and were until recently very hard to obtain in word-processed and HTML documents.
English
English is one of the few European languages that does not have many words that contain diacritical marks. Exceptions are unassimilated foreign loanwords, including borrowings from French and, increasingly, Spanish; however, the diacritic is also sometimes omitted from such words. Loanwords that frequently appear with the diacritic in English include café, résumé or resumé (a usage that helps distinguish it from the verb resume), soufflé, and naïveté (see English words with diacritics). In older practice (and even among some orthographically conservative modern writers) one may see examples such as élite and rôle.
English speakers and writers once used the diaeresis more often than now in words such as coöperation (from Fr. coopération), zoölogy (from Grk. zoologia), and seeër (now more commonly see-er), but this practice has become far less common; The New Yorker magazine is one of the only major publications that still uses it.
A few English words can only be distinguished from others by a diacritic or modified letter, including animé, exposé, lamé, maté, öre, øre, pâté, piqué, rosé, and soufflé. The same is true of résumé, alternately resumé, but nevertheless it is sometimes spelled resume in the US, and saké, which is more commonly spelled sake. In a few words, diacritics that did not exist in the original have been added for disambiguation, as in maté (from Sp. and Port. mate) and Malé (from Dhivehi މާލެ).
The acute and grave accents are occasionally used in poetry and lyrics: the acute to indicate stress overtly where it might be ambiguous (rébel vs. rebél) or nonstandard for metrical reasons (caléndar), the grave to indicate that an ordinarily silent or elided syllable is pronounced (warnèd, parlìament). In certain personal names such as Renée and Zoë, the diacritical marks are included more often than omitted.
Transliteration
Several languages that are not written with the Roman alphabet are transliterated, or romanized, using diacritics. Examples:
- Arabic has several romanisations, depending on the type of the application, region, intended audience, country, etc. many of them extensively use diacritics, e.g., some methods use a dot for rendering emphatic consonants (ṣ, ṭ, ḍ, ẓ, ḥ). Macron is often used to render long vowels. š is often used for /ʃ/, ġ for /ɣ/.
- Chinese has several romanizations that use the umlaut, but only on u (ü). In Hanyu Pinyin, the four tones of Mandarin Chinese are denoted by the macron (first tone), acute (second tone), caron (third tone) and grave (fourth tone) diacritics. Example: ā, á, ǎ, à.
- Romanized Japanese (Romaji) uses diacritics to mark long vowels. The Hepburn romanization system uses a macron to mark long vowels, and the Kunrei-shiki and Nihon-shiki systems use a circumflex.
- Sanskrit, as well as many of its descendants, like Hindi and Bengali, uses a lossless transliteration system for representing words in the Roman alphabet. This includes several letters with diacritical markings, such as horizontal lines above vowels (ā, ī, ū), dots above and below consonants (ṛ, ḥ, ṃ, ṇ, ṣ, ṭ, ḍ) as well as a few others (ś, ñ).
See also
- Alphabets derived from the Latin
- Category:Latin-derived alphabets
- Category:Specific letter-diacritic combinations
- Collating sequence
- Combining character
- English words with diacritics
- Heavy metal umlaut
- Latin alphabet
- List of Latin letters
- List of U.S. cities with diacritics
- Romanization
- Typing accents
- Wiktionary:Appendix:English words with diacritics
References
- ^ Henry Sweet (1877) A Handbook of Phonetics, p 174–175: "Even letters with accents and diacritics [...] being only cast for a few founts, act practically as new letters. [...] We may consider the h in sh and th simply as a diacritic written for convenience on a line with the letter it modifies."
- ^ OED
- ^ Academia de la Llingua Asturiana, Gramática de la Llingua Asturiana, tercera edición, Oviedo: Academia de la Llingua Asturiana (2001), ISBN 84-8168-310-8, http://www.academiadelallingua.com/diccionariu/gramatica_llingua.pdf (page 16, section 1.2)
External links
- Diacritics Project
- Unicode
- Orthographic diacritics and multilingual computing, by J. C. Wells
- Notes on the use of the diacritics, by Markus Lång
- Entering International Characters (in Linux, KDE)
- Standard Character Set for Macintosh PDF at Adobe.com
- Keyboard Help—Learn how to create world language accent marks and other diacriticals on a computer
Aa Bb Cc Dd Ee Ff Gg Hh Ii Jj Kk Ll Mm Nn Oo Pp Qq Rr Ss Tt Uu Vv Ww Xx Yy Zz Related- History
- Palaeography
- Derivations
- Diacritics
- Punctuation
- Numerals
- Unicode
- List of letters
- ISO/IEC 646
Typography terminology Page 
Paragraph Character Typeface anatomyCounter · Diacritics · Dingbat · Glyph · Initial · Kerning · Letter-spacing · Ligature · Subscript and superscript · Swash · Text figuresCapitalizationVertical aspectsClassifications Punctuation Typesetting Calligraphy · ETAOIN SHRDLU · Font (Computer font) · Font catalog · Letterpress · Lorem ipsum · Movable type · Pangram · Phototypesetting · Punchcutting · Type design · Typeface · Type foundry · MicrotypographyTypographic units Digital typography Categories:- Diacritics
- Punctuation
- Typography
- accent marks (thus called because the acute, the grave and the circumflex accent were originally used to indicate different types of pitch accents, in the polytonic transcription of Greek)




Wikimedia Foundation. 2010.