- Transfer RNA
-
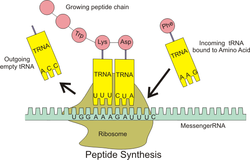 The interaction of tRNA and mRNA in protein synthesis
The interaction of tRNA and mRNA in protein synthesis
tRNA Identifiers Symbol tRNA Rfam RF00005 Other data RNA type gene, tRNA Available PDB structures: 3icq, 1asy, 1asz, 1il2, 2tra, 3tra, 486d, 1fir, 1yfg, 3eph, 3epj, 3epk, 3epl, 1efw, 1c0a, 2ake, 2azx, 2dr2, 1f7u, 1f7v, 3foz, 2hgp, 2j00 , 2j02, 2ow8, 2v46, 2v48, 2wdg, 2wdh, 2wdk, 2wdm, 2wh1 Transfer RNA (tRNA) is an adaptor molecule composed of RNA, typically 73 to 93 nucleotides in length, that is used in biology to bridge the three-letter genetic code in messenger RNA (mRNA) with the twenty-letter code of amino acids in proteins.[1] The role of tRNA as an adaptor is best understood by considering its three-dimensional structure. One end of the tRNA carries the genetic code in a three-nucleotide sequence called the anticodon. The anticodon forms three base pairs with a codon in mRNA during protein biosynthesis. The mRNA encodes a protein as a series of contiguous codons, each of which is recognized by a particular tRNA. On the other end of its three-dimensional structure, each tRNA is covalently attached to the amino acid that corresponds to the anticodon sequence. This covalent attachment to the tRNA 3’ end is catalyzed by enzymes called aminoacyl-tRNA synthetases. Each type of tRNA molecule can be attached to only one type of amino acid, but, because the genetic code contains multiple codons that specify the same amino acid, tRNA molecules bearing different anticodons may also carry the same amino acid.
During protein synthesis, tRNAs are delivered to the ribosome by proteins called elongation factors (EF-Tu in bacteria, eEF-1 in eukaryotes), which aid in decoding the mRNA codon sequence. Once delivered, a tRNA already bound to the ribosome transfers the growing polypeptide chain from its 3’ end to the amino acid attached to the 3’ end of the newly-delivered tRNA, a reaction catalyzed by the ribosome.
Contents
Structure
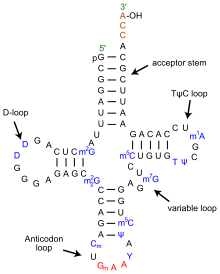 Secondary cloverleaf structure of tRNAPhe from yeast.
Secondary cloverleaf structure of tRNAPhe from yeast. Tertiary structure of tRNA. CCA tail in yellow, Acceptor stem in purple, Variable loop in orange, D arm in red, Anticodon arm in blue with Anticodon in black, T arm in green.
Tertiary structure of tRNA. CCA tail in yellow, Acceptor stem in purple, Variable loop in orange, D arm in red, Anticodon arm in blue with Anticodon in black, T arm in green.The structure of tRNA can be decomposed into its primary structure, its secondary structure (usually visualized as the cloverleaf structure), and its tertiary structure (all tRNAs have a similar L-shaped 3D structure that allows them to fit into the P and A sites of the ribosome). The cloverleaf structure becomes the 3D L-shaped structure through coaxial stacking of the helices, which is a common RNA Tertiary Structure motif.
- The 5'-terminal phosphate group.
- The acceptor stem is a 7-base pair (bp) stem made by the base pairing of the 5'-terminal nucleotide with the 3'-terminal nucleotide (which contains the CCA 3'-terminal group used to attach the amino acid). The acceptor stem may contain non-Watson-Crick base pairs.
- The CCA tail is a cytosine-cytosine-adenine sequence at the 3' end of the tRNA molecule. This sequence is important for the recognition of tRNA by enzymes and critical in translation.[2][3] In prokaryotes, the CCA sequence is transcribed in some tRNA sequences. In most prokaryotic tRNAs and eukaryotic tRNAs, the CCA sequence is added during processing and therefore does not appear in the tRNA gene.[4]
- The D arm is a 4 bp stem ending in a loop that often contains dihydrouridine.
- The anticodon arm is a 5-bp stem whose loop contains the anticodon.
- The T arm is a 5 bp stem containing the sequence TΨC where Ψ is a pseudouridine.
- Bases that have been modified, especially by methylation, occur in several positions throughout the tRNA. The first anticodon base, or wobble-position, is sometimes modified to inosine (derived from adenine), pseudouridine (derived from uracil) or lysidine (derived from cytosine).
Anticodon
An anticodon[5] is a unit made up of three nucleotides that correspond to the three bases of the codon on the mRNA. Each tRNA contains a specific anticodon triplet sequence that can base-pair to one or more codons for an amino acid. For example, the codon for lysine is AAA; the anticodon of a lysine tRNA might be UUU. Some anticodons can pair with more than one codon due to a phenomenon known as wobble base pairing. Frequently, the first nucleotide of the anticodon is one of two not found on mRNA: inosine and pseudouridine, which can hydrogen bond to more than one base in the corresponding codon position. In the genetic code, it is common for a single amino acid to be specified by all four third-position possibilities, or at least by both Pyrimidines and Purines; for example, the amino acid glycine is coded for by the codon sequences GGU, GGC, GGA, and GGG.
To provide a one-to-one correspondence between tRNA molecules and codons that specify amino acids, 61 types of tRNA molecules would be required per cell. However, many cells contain fewer than 61 types of tRNAs because the wobble base is capable of binding to several, though not necessarily all, of the codons that specify a particular amino acid. A minimum of 31 tRNA are required to translate, unambiguously, all 61 sense codons of the standard genetic code.[6][7]
Aminoacylation
Aminoacylation is the process of adding an aminoacyl group to a compound. It produces tRNA molecules with their CCA 3' ends covalently linked to an amino acid.
Each tRNA is aminoacylated (or charged) with a specific amino acid by an aminoacyl tRNA synthetase. There is normally a single aminoacyl tRNA synthetase for each amino acid, despite the fact that there can be more than one tRNA, and more than one anticodon, for an amino acid. Recognition of the appropriate tRNA by the synthetases is not mediated solely by the anticodon, and the acceptor stem often plays a prominent role.[8]
Reaction:
Sometimes, certain organisms can have one or more aminoacyl tRNA synthetases missing. This leads to mischarging of the tRNA by a chemically related amino acid. The correct amino acid is made by enzymes that modify the mischarged amino acid to the correct one.
For example, Helicobacter pylori has glutaminyl tRNA synthetase missing. Thus, glutamate tRNA synthetase mischarges tRNA-glutamine(tRNA-Gln) with glutamate. An amidotransferase then converts the acid side chain of the glutamate to the amide, forming the correctly charged gln-tRNA-Gln.
Binding to ribosome
The range of conformations adopted by tRNA as it transits the A/T through P/E sites on the ribosome. The Protein Data Bank (PDB) codes for the structural models used as end points of the animation are given. Both tRNAs are modeled as phenylalanine-specific tRNA from Escherichia coli, with the A/T tRNA as a homology model of the deposited coordinates. Color coding as shown for tRNA tertiary structure. Adapted from.[9]The ribosome has three binding sites for tRNA molecules that span the space between the two ribosomal subunits: the A (aminoacyl), P (peptidyl), and E (exit) sites. In addition, the ribosome has two other sites for tRNA binding that are used during mRNA decoding or during the initiation of protein synthesis. These are the T site (named elongation factor Tu) and I site (initiation).[10][11] By convention, the tRNA binding sites are denoted with the site on the small ribosomal subunit listed first and the site on the large ribosomal subunit listed second. For example, the A site is often written A/A, the P site, P/P, and the E site, E/E.[10]The binding proteins like L27, L2, L14, L15, L16 at the A- and P- sites have been determined by affinity labeling by A.P. Czernilofsky et al. (Proc. Natl. Acad. Sci, USA, pp 230–234, 1974).
Once translation initiation is complete, the first aminoacyl tRNA is located in the P/P site, ready for the elongation cycle described below. During translation elongation, tRNA first binds to the ribosome as part of a complex with elongation factor Tu (EF-Tu) or its eukaryotic (eEF-1)or archaeal counterpart. This initial tRNA binding site is called the A/T site. In the A/T site, the A-site half resides in the small ribosomal subunit where the mRNA decoding site is located. The mRNA decoding site is where the mRNA codon is read out during translation. The T-site half resides mainly on the large ribosomal subunit where EF-Tu or eEF-1 interacts with the ribosome. Once mRNA decoding is complete, the aminoacyl-tRNA is bound in the A/A site and is ready for the next peptide bond to be formed to its attached amino acid. The peptidyl-tRNA, which transfers the growing polypeptide to the aminoacyl-tRNA bound in the A/A site, is bound in the P/P site. Once the peptide bond is formed, the tRNA in the P/P site is deacylated, or has a free 3’ end, and the tRNA in the A/A site carries the growing polypeptide chain. To allow for the next elongation cycle, the tRNAs then move through hybrid A/P and P/E binding sites, before completing the cycle and residing in the P/P and E/E sites. Once the A/A and P/P tRNAs have moved to the P/P and E/E sites, the mRNA has also moved over by one codon and the A/T site is vacant, ready for the next round of mRNA decoding. The tRNA bound in the E/E site then leaves the ribosome.
The P/I site is actually the first to bind to aminoacyl tRNA, which is delivered by an initiation factor called IF2 in bacteria.[11] However, the existence of the P/I site in eukaryotic or archaeal ribosomes has not yet been confirmed. The P-site protein L27 has been determined by affinity labeling by E. Collatz and A.P. Czernilofsky (FEBS Lett., Vol. 63, pp 283–286, 1976).
tRNA genes
Organisms vary in the number of tRNA genes in their genome. The nematode worm C. elegans, a commonly used model organism in genetics studies, has 29,647 [12] genes in its nuclear genome, of which 620 code for tRNA.[13][14] The budding yeast Saccharomyces cerevisiae has 275 tRNA genes in its genome. In the human genome, which according to current estimates has about 27,161 genes [15] in total, there are about 4,421 non-coding RNA genes, which include tRNA genes. There are 22 mitochondrial tRNA genes;[16] 497 nuclear genes encoding cytoplasmic tRNA molecules and there are 324 tRNA-derived putative pseudogenes.[17]
Cytoplasmic tRNA genes can be grouped into 49 families according to their anticodon features. These genes are found on all chromosomes, except 22 and Y chromosome. High clustering on 6p is observed (140 tRNA genes), as well on 1 chromosome.[17]
tRNA biogenesis
In eukaryotic cells, tRNAs are transcribed by RNA polymerase III as pre-tRNAs in the nucleus.[18] RNA polymerase III recognizes two internal promoter sequences (A-box B internal promoter) inside tRNA genes.[19] The first promoter begins at nucleotide 8 of mature tRNAs and the second promoter is located 30-60 nucleotides downstream of the first promoter. The transcription terminates after a strech of four or more thymidines.[19]
Pre-tRNAs undergo extensive modifications inside the nucleus. Some pre-tRNAs contain introns that are spliced, or cut, to form the functional tRNA molecule;[20] in bacteria these self-splice, whereas in eukaryotes and archaea they are removed by tRNA splicing endonuclease.[21] The 5' sequence is removed by RNase P,[22] whereas the 3' end is removed by the tRNase Z enzyme.[23] A notable exception is in the archaeon Nanoarchaeum equitans, which does not possess an RNase P enzyme and has a promoter placed such that transcription starts at the 5' end of the mature tRNA.[24] The non-templated 3' CCA tail is added by a nucleotidyl transferase.[25] Before tRNAs are exported into the cytoplasm by Los1/Xpo-t,[26][27] tRNAs are aminoacylated.[28] The order of the processing events is not conserved. For example in yeast, the splicing is not carried out in the nucleus but at the cytoplasmic side of mitochondrial membranes.[29]
History
The existence of tRNA was first hypothesized by Francis Crick, based on the assumption that there must exist an adapter molecule capable of mediating the translation of the RNA alphabet into the protein alphabet. Significant research on structure was conducted in the early 1960s by Alex Rich and Don Caspar, two researchers in Boston, the Jacques Fresco group in Princeton University and a United Kingdom group at King's College London.[30] In 1965, a publication by Robert W. Holley reported the primary structure and suggested three secondary structures.[31] The cloverleaf structure was ascertained by several other studies in the following years[32] and was finally confirmed using X-ray crystallography studies in 1974. Two independent groups, Kim Sung-Hou working under Alexander Rich and a British group headed by Aaron Klug, published the same crystallography findings within a year.[33][34]
See also
- mRNA
- tmRNA
- non-coding RNA and introns
- translation
- Transfer RNA-like structures
- Kim Sung-Hou
- wobble hypothesis
- tRNADB
References
- ^ Crick F (1968). "The origin of the genetic code". J Mol Biol 38 (3): 367–379. doi:10.1016/0022-2836(68)90392-6. PMID 4887876.
- ^ Sprinzl, M., and Cramer, F. (1979) Prog. Nucleic Acids Res. Mol. Biol. 22, 1–16
- ^ Green, R., and Noller, H. F. (1997) Annu. Rev. Biochem. 66, 679–716
- ^ Aebi, M., Kirchner, G., Chen, J. Y., Vijayraghavan, U., Jacobson, A., Martin, N. C., and Abelson, J. (1990) J. Biol. Chem. 265, 16216–16220
- ^ Felsenfeld G, Cantoni G (1964). "Use of thermal denaturation studies to investigate the base sequence of yeast serine sRNA". Proc Natl Acad Sci USA 51 (5): 818–26. doi:10.1073/pnas.51.5.818. PMC 300168. PMID 14172997. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=300168.
- ^ Lodish H, Berk A, Matsudaira P, Kaiser CA, Krieger M, Scott MP, Zipursky SL, Darnell J. (2004). Molecular Biology of the Cell. WH Freeman: New York, NY. 5th ed.
- ^ Crick F (1968). "The origin of the genetic code". J Mol Biol 38 (3): 367–379. doi:10.1016/0022-2836(68)90392-6. PMID 4887876. - page 377
- ^ Schimmel P, Giege R, Moras D, Yokoyama S (1993). "An operational RNA code for amino acids and possible relationship to genetic code". Proc Natl Acad Sci 90 (19): 8763–876. doi:10.1073/pnas.90.19.8763.
- ^ Dunkle JA, Wang L, Feldman MB, Pulk A, Chen VB, Kapral GJ, Noeske J, Richardson JS, Blanchard SC, Cate JH (2011). "Structures of the bacterial ribosome in classical and hybrid states of tRNA binding". Science 332 (6032): 981–984. doi:10.1126/science.1202692. PMID 21596992.
- ^ a b Agirrezabala X, Frank J (2009). "Elongation in translation as a dynamic interaction among the ribosome, tRNA, and elongation factors EF-G and EF-Tu". Q Rev Biophys 42 (3): 159–200. doi:10.1017/S0033583509990060. PMC 2832932. PMID 20025795. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2832932.
- ^ a b Allen GS, Zavialov A, Gursky R, Ehrenberg M, Frank J (2005). "The cryo-EM structure of a translation initiation complex from Escherichia coli". Cell 121 (5): 703–712. doi:10.1016/j.cell.2005.03.023. PMID 15935757.
- ^ WormBase web site, http://www.wormbase.org, release WS187, date 25-Jan-2008.
- ^ Spieth, J; Lawson, D (Jan 2006). "Overview of gene structure". WormBook : the online review of C. Elegans biology: 1–10. doi:10.1895/wormbook.1.65.1. PMID 18023127.
- ^ Hartwell LH, Hood L, Goldberg ML, Reynolds AE, Silver LM, Veres RC. (2004). Genetics: From Genes to Genomes 2nd ed. McGraw-Hill: New York, NY. p 264.
- ^ Ensembl release 48 - Dec 2007 http://www.ensembl.org
- ^ Ibid. p 529.
- ^ a b Lander E. et al. (2001). "Initial sequencing and analysis of the human genome". Nature 409 (6822): 860–921. doi:10.1038/35057062. PMID 11237011.
- ^ White RJ (1997). "Regulation of RNA polymerases I and III by the retinoblastoma protein: a mechanism for growth control?". Trends in Biochemical Sciences 22 (3): 77–80. doi:10.1016/S0968-0004(96)10067-0. PMID 9066256.
- ^ a b Dieci G, Fiorino G, Castelnuovo M, Teichmann M, Pagano A (December 2007). "The expanding RNA polymerase III transcriptome". Trends Genet. 23 (12): 614–22. doi:10.1016/j.tig.2007.09.001. PMID 17977614.
- ^ Tocchini-Valentini,Giuseppe D., Paolo Fruscoloni, and Glauco P. Tocchini-Valentini. "Processing of Multiple Intron-Containing pre-tRNA." PubMed Central. 12 November 2009. Retrieved on 19 July 2011. <http://www.ncbi.nlm.nih.gov/pmc/articles/PMC2787110/>.
- ^ Abelson J, Trotta CR, Li H (1998). "tRNA Splicing". J Biol Chem 273 (21): 12685–12688. doi:10.1074/jbc.273.21.12685. PMID 9582290.
- ^ Frank DN, Pace NR (1998). "Ribonuclease P: unity and diversity in a tRNA processing ribozyme". Annu. Rev. Biochem. 67 (1): 153–80. doi:10.1146/annurev.biochem.67.1.153. PMID 9759486.
- ^ Ceballos M, Vioque A (2007). "tRNase Z". Protein Pept. Lett. 14 (2): 137–45. doi:10.2174/092986607779816050. PMID 17305600.
- ^ Randau L, Schröder I, Söll D (May 2008). "Life without RNase P". Nature 453 (7191): 120–3. doi:10.1038/nature06833. PMID 18451863.
- ^ Weiner AM (October 2004). "tRNA maturation: RNA polymerization without a nucleic acid template". Curr. Biol. 14 (20): R883–5. doi:10.1016/j.cub.2004.09.069. PMID 15498478.
- ^ Kutay, U. .; Lipowsky, G. .; Izaurralde, E. .; Bischoff, F. .; Schwarzmaier, P. .; Hartmann, E. .; Görlich, D. . (1998). "Identification of a tRNA-Specific Nuclear Export Receptor". Molecular Cell 1 (3): 359–369. doi:10.1016/S1097-2765(00)80036-2. PMID 9660920.
- ^ Arts, G. J.; Fornerod, M. .; Mattaj, L. W. (1998). "Identification of a nuclear export receptor for tRNA". Current Biology 8 (6): 305–314. doi:10.1016/S0960-9822(98)70130-7. PMID 9512417.
- ^ Arts, G. .; Kuersten, S. .; Romby, P. .; Ehresmann, B. .; Mattaj, I. . (1998). "The role of exportin-t in selective nuclear export of mature tRNAs". The EMBO journal 17 (24): 7430–7441. doi:10.1093/emboj/17.24.7430. PMC 1171087. PMID 9857198. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1171087.
- ^ Yoshihisa, T.; Yunoki-Esaki, K.; Ohshima, C.; Tanaka, N.; Endo, T. (2003). "Possibility of cytoplasmic pre-tRNA splicing: the yeast tRNA splicing endonuclease mainly localizes on the mitochondria". Molecular biology of the cell 14 (8): 3266–3279. doi:10.1091/mbc.E02-11-0757. PMC 181566. PMID 12925762. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=181566.
- ^ Brian F.C. Clark (October 2006). "The crystal structure of tRNA". J. Biosci. 31 (4): 453–7. doi:10.1007/BF02705184. PMID 17206065. http://www.ias.ac.in/jbiosci/oct2006/453.pdf.
- ^ HOLLEY RW, APGAR J, EVERETT GA et al. (March 1965). "STRUCTURE OF A RIBONUCLEIC ACID". Science 147 (3664): 1462–5. doi:10.1126/science.147.3664.1462. PMID 14263761. http://www.sciencemag.org/cgi/pmidlookup?view=long&pmid=14263761. Retrieved 2010-09-03.
- ^ "The Nobel Prize in Physiology or Medicine 1968". Nobel Foundation. http://nobelprize.org/nobel_prizes/medicine/laureates/1968/index.html. Retrieved 2007-07-28.
- ^ Ladner JE, Jack A, Robertus JD et al. (November 1975). "Structure of yeast phenylalanine transfer RNA at 2.5 A resolution". Proc. Natl. Acad. Sci. U.S.A. 72 (11): 4414–8. doi:10.1073/pnas.72.11.4414. PMC 388732. PMID 1105583. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=388732.
- ^ Kim SH, Quigley GJ, Suddath FL et al. (1973). "Three-dimensional structure of yeast phenylalanine transfer RNA: folding of the polynucleotide chain". Science 179 (4070): 285–8. Bibcode 1973Sci...179..285K. doi:10.1126/science.179.4070.285. PMID 4566654.
External links
- tRNAdb (updated and completely restructured version of Spritzls tRNA compilation)
- original Sprinzl tRNA compilation
- tRNA link to heart disease and stroke
- GtRNAdb: Collection of tRNAs identified from complete genomes
- Molecule of the Month © RCSB Protein Data Bank:
- Rfam entry for tRNA
Types of nucleic acids Constituents Nucleobases · Nucleosides · Nucleotides · DeoxynucleotidesRibonucleic acids
(coding and non-coding)translation: mRNA (pre-mRNA/hnRNA) · tRNA · rRNA · tmRNA
regulatory: miRNA · siRNA · piRNA · aRNA · RNAi ·
RNA processing: snRNA · snoRNA
other/ungrouped: gRNA · shRNA · stRNA · ta-siRNADeoxyribonucleic acids Nucleic acid analogues Cloning vectors biochemical families: prot · nucl · carb (glpr, alco, glys) · lipd (fata/i, phld, strd, gllp, eico) · amac/i · ncbs/i · ttpy/iCategories:- Rfam pages needing a picture
- RNA
- Protein biosynthesis
- Non-coding RNA


Wikimedia Foundation. 2010.