- MPEG-1
-
Moving Picture Experts Group Phase 1 (MPEG-1) Filename extension .mpg, .mpeg, .mp1, .mp2, .mp3, .m1v, .m1a, .m2a, .mpa, .mpvInternet media type audio/mpeg, video/mpegDeveloped by ISO, IEC Type of format audio, video, container Extended from JPEG, H.261 Extended to MPEG-2 Standard(s) ISO/IEC 11172 MPEG-1 is a standard for lossy compression of video and audio. It is designed to compress VHS-quality raw digital video and CD audio down to 1.5 Mbit/s (26:1 and 6:1 compression ratios respectively)[1] without excessive quality loss, making video CDs, digital cable/satellite TV and digital audio broadcasting (DAB) possible.[2][3]
Today, MPEG-1 has become the most widely compatible lossy audio/video format in the world, and is used in a large number of products and technologies. Perhaps the best-known part of the MPEG-1 standard is the MP3 audio format it introduced.
The MPEG-1 standard is published as ISO/IEC 11172 – Information technology—Coding of moving pictures and associated audio for digital storage media at up to about 1.5 Mbit/s. The standard consists of the following five Parts:[4][5][6][7][8]
- Systems (storage and synchronization of video, audio, and other data together)
- Video (compressed video content)
- Audio (compressed audio content)
- Conformance testing (testing the correctness of implementations of the standard)
- Reference software (example software showing how to encode and decode according to the standard)
Contents
History
Modeled on the successful collaborative approach and the compression technologies developed by the Joint Photographic Experts Group and CCITT's Experts Group on Telephony (creators of the JPEG image compression standard and the H.261 standard for video conferencing respectively) the Moving Picture Experts Group (MPEG) working group was established in January 1988. MPEG was formed to address the need for standard video and audio formats, and build on H.261 to get better quality through the use of more complex encoding methods.[2][9][10]
Development of the MPEG-1 standard began in May 1988. 14 video and 14 audio codec proposals were submitted by individual companies and institutions for evaluation. The codecs were extensively tested for computational complexity and subjective (human perceived) quality, at data rates of 1.5 Mbit/s. This specific bitrate was chosen for transmission over T-1/E-1 lines and as the approximate data rate of audio CDs.[11] The codecs that excelled in this testing were utilized as the basis for the standard and refined further, with additional features and other improvements being incorporated in the process.[12]
After 20 meetings of the full group in various cities around the world, and 4½ years of development and testing, the final standard (for parts 1–3) was approved in early November 1992 and published a few months later.[13] The reported completion date of the MPEG-1 standard, varies greatly: a largely complete draft standard was produced in September 1990, and from that point on, only minor changes were introduced.[2] The draft standard was publicly available for purchase.[14] The standard was finished with the 6 November 1992 meeting.[15] The Berkeley Plateau Multimedia Research Group developed a MPEG-1 decoder in November 1992.[16] In July 1990, before the first draft of the MPEG-1 standard had even been written, work began on a second standard, MPEG-2,[17] intended to extend MPEG-1 technology to provide full broadcast-quality video (as per CCIR 601) at high bitrates (3–15 Mbit/s), and support for interlaced video.[18] Due in part to the similarity between the two codecs, the MPEG-2 standard includes full backwards compatibility with MPEG-1 video, so any MPEG-2 decoder can play MPEG-1 videos.[19]
Notably, the MPEG-1 standard very strictly defines the bitstream, and decoder function, but does not define how MPEG-1 encoding is to be performed, although a reference implementation is provided in ISO/IEC-11172-5.[1] This means that MPEG-1 coding efficiency can drastically vary depending on the encoder used, and generally means that newer encoders perform significantly better than their predecessors.[20] The first three parts (Systems, Video and Audio) of ISO/IEC 11172 were published in August 1993.[21]
MPEG-1 Parts[4][8] Part Number First public release date (First edition) Latest correction Title Description Part 1 ISO/IEC 11172-1 1993 1999[22] Systems Part 2 ISO/IEC 11172-2 1993 2006[23] Video Part 3 ISO/IEC 11172-3 1993 1996[24] Audio Part 4 ISO/IEC 11172-4 1995 2007[25] Compliance testing Part 5 ISO/IEC TR 11172-5 1998 2007[26] Software simulation Patents
MPEG-1 video and Layer I/II audio may be able to be implemented without payment of license fees.[27][28][29][30][31] The ISO patent database lists one patent for ISO 11172, US 4,472,747, which expired in 2003.[32] The near-complete draft of the MPEG-1 standard was publicly available as ISO CD 11172[14] by December 6, 1991.[33] Due to its age, many of the patents on the technology have expired. Neither the Kuro5hin article "Patent Status of MPEG-1, H.261 and MPEG-2"[34] nor a thread on the gstreamer-devel[35] mailing list were able to list a single unexpired MPEG-1 video and Layer I/II audio patent. A discussion on whatwg mentioned the now expired US 5,214,678 patent as a possible patent on audio layer II.[36] A full MPEG-1 decoder and encoder can not be implemented royalty free since there are companies that require patent fees for implementations of MPEG-1 Layer 3 Audio as discussed in the MP3 article.
Applications
- Most popular computer software for video playback includes MPEG-1 decoding, in addition to any other supported formats.
- The popularity of MP3 audio has established a massive installed base of hardware that can play back MPEG-1 Audio (all three layers).
- "Virtually all digital audio devices" can play back MPEG-1 Audio.[37] Many millions have been sold to-date.
- Before MPEG-2 became widespread, many digital satellite/cable TV services used MPEG-1 exclusively.[10][20]
- The widespread popularity of MPEG-2 with broadcasters means MPEG-1 is playable by most digital cable and satellite set-top boxes, and digital disc and tape players, due to backwards compatibility.
- MPEG-1 is the exclusive video and audio format used on Video CD (VCD), the first consumer digital video format, and still a very popular format around the world.
- The Super Video CD standard, based on VCD, uses MPEG-1 audio exclusively, as well as MPEG-2 video.
- The DVD-Video format uses MPEG-2 video primarily, but MPEG-1 support is explicitly defined in the standard.
- The DVD-Video standard originally required MPEG-1 Layer II audio for PAL countries, but was changed to allow AC-3/Dolby Digital-only discs. MPEG-1 Layer II audio is still allowed on DVDs, although newer extensions to the format, like MPEG Multichannel, are rarely supported.
- Most DVD players also support Video CD and MP3 CD playback, which use MPEG-1.
- The international Digital Video Broadcasting (DVB) standard primarily uses MPEG-1 Layer II audio, and MPEG-2 video.
- The international Digital Audio Broadcasting (DAB) standard uses MPEG-1 Layer II audio exclusively, due to MP2's especially high quality, modest decoder performance requirements, and tolerance of errors.
Part 1: Systems
Part 1 of the MPEG-1 standard covers systems, and is defined in ISO/IEC-11172-1.
MPEG-1 Systems specifies the logical layout and methods used to store the encoded audio, video, and other data into a standard bitstream, and to maintain synchronization between the different contents. This file format is specifically designed for storage on media, and transmission over data channels, that are considered relatively reliable. Only limited error protection is defined by the standard, and small errors in the bitstream may cause noticeable defects.
This structure was later named an MPEG program stream: "The MPEG-1 Systems design is essentially identical to the MPEG-2 Program Stream structure."[38] This terminology is more popular, precise (differentiates it from an MPEG transport stream) and will be used here.
Elementary streams
Elementary Streams (ES) are the raw bitstreams of MPEG-1 audio and video encoded data (output from an encoder). These files can be distributed on their own, such as is the case with MP3 files.
Packetized Elementary Streams (PES) are elementary streams packetized into packets of variable lengths, i.e., divided ES into independent chunks where cyclic redundancy check (CRC) checksum was added to each packet for error detection.
System Clock Reference (SCR) is a timing value stored in a 33-bit header of each PES, at a frequency/precision of 90 kHz, with an extra 9-bit extension that stores additional timing data with a precision of 27 MHz.[39][40] These are inserted by the encoder, derived from the system time clock (STC). Simultaneously encoded audio and video streams will not have identical SCR values, however, due to buffering, encoding, jitter, and other delay.
Program streams
For more details on this topic, see MPEG program stream.Program Streams (PS) are concerned with combining multiple packetized elementary streams (usually just one audio and video PES) into a single stream, ensuring simultaneous delivery, and maintaining synchronization. The PS structure is known as a multiplex, or a container format.
Presentation time stamps (PTS) exist in PS to correct the inevitable disparity between audio and video SCR values (time-base correction). 90 kHz PTS values in the PS header tell the decoder which video SCR values match which audio SCR values.[39] PTS determines when to display a portion of an MPEG program, and is also used by the decoder to determine when data can be discarded from the buffer.[41] Either video or audio will be delayed by the decoder until the corresponding segment of the other arrives and can be decoded.
PTS handling can be problematic. Decoders must accept multiple program streams that have been concatenated (joined sequentially). This causes PTS values in the middle of the video to reset to zero, which then begin incrementing again. Such PTS wraparound disparities can cause timing issues that must be specially handled by the decoder.
Decoding Time Stamps (DTS), additionally, are required because of B-frames. With B-frames in the video stream, adjacent frames have to be encoded and decoded out-of-order (re-ordered frames). DTS is quite similar to PTS, but instead of just handling sequential frames, it contains the proper time-stamps to tell the decoder when to decode and display the next B-frame (types of frames explained below), ahead of its anchor (P- or I-) frame. Without B-frames in the video, PTS and DTS values are identical.[42]
Multiplexing
To generate the PS, the multiplexer will interleave the (two or more) packetized elementary streams. This is done so the packets of the simultaneous streams can be transferred over the same channel and are guaranteed to both arrive at the decoder at precisely the same time. This is a case of time-division multiplexing.
Determining how much data from each stream should be in each interleaved segment (the size of the interleave) is complicated, yet an important requirement. Improper interleaving will result in buffer underflows or overflows, as the receiver gets more of one stream than it can store (eg. audio), before it gets enough data to decode the other simultaneous stream (eg. video). The MPEG Video Buffering Verifier (VBV) assists in determining if a multiplexed PS can be decoded by a device with a specified data throughput rate and buffer size.[43] This offers feedback to the muxer and the encoder, so that they can change the mux size or adjust bitrates as needed for compliance.
Part 2: Video
Part 2 of the MPEG-1 standard covers video and is defined in ISO/IEC-11172-2. The design was heavily influenced by H.261.
MPEG-1 Video exploits perceptual compression methods to significantly reduce the data rate required by a video stream. It reduces or completely discards information in certain frequencies and areas of the picture that the human eye has limited ability to fully perceive. It also exploits temporal (over time) and spatial (across a picture) redundancy common in video to achieve better data compression than would be possible otherwise. (See: Video compression)
Color space
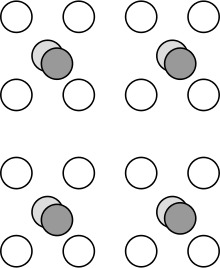 Example of 4:2:0 subsampling. The two overlapping center circles represent chroma blue and chroma red (color) pixels, while the 4 outside circles represent the luma (brightness).
Example of 4:2:0 subsampling. The two overlapping center circles represent chroma blue and chroma red (color) pixels, while the 4 outside circles represent the luma (brightness).
Before encoding video to MPEG-1, the color-space is transformed to Y'CbCr (Y'=Luma, Cb=Chroma Blue, Cr=Chroma Red). Luma (brightness, resolution) is stored separately from chroma (color, hue, phase) and even further separated into red and blue components. The chroma is also subsampled to 4:2:0, meaning it is reduced by one half vertically and one half horizontally, to just one quarter the resolution of the video.[1] This software algorithm also has analogies in hardware, such as the output from a Bayer pattern filter, common in digital colour cameras.
Because the human eye is much less sensitive to small changes in color than in brightness, chroma subsampling is a very effective way to reduce the amount of video data that needs to be compressed. On videos with fine detail (high spatial complexity) this can manifest as chroma aliasing artifacts. Compared to other digital compression artifacts, this issue seems to be very rarely a source of annoyance.
Because of subsampling, Y'CbCr video must always be stored using even dimensions (divisible by 2), otherwise chroma mismatch ("ghosts") will occur, and it will appear as if the color is ahead of, or behind the rest of the video, much like a shadow.
Y'CbCr is often inaccurately called YUV which is only used in the domain of analog video signals. Similarly, the terms luminance and chrominance are often used instead of the (more accurate) terms luma and chroma.
Resolution/Bitrate
MPEG-1 supports resolutions up to 4095×4095 (12-bits), and bitrates up to 100 Mbit/s.[10]
MPEG-1 videos are most commonly seen using Source Input Format (SIF) resolution: 352x240, 352x288, or 320x240. These low resolutions, combined with a bitrate less than 1.5 Mbit/s, make up what is known as a constrained parameters bitstream (CPB), later renamed the "Low Level" (LL) profile in MPEG-2. This is the minimum video specifications any decoder should be able to handle, to be considered MPEG-1 compliant. This was selected to provide a good balance between quality and performance, allowing the use of reasonably inexpensive hardware of the time.[2][10]
Frame/picture/block types
MPEG-1 has several frame/picture types that serve different purposes. The most important, yet simplest, is I-frame.
I-frames
I-frame is an abbreviation for Intra-frame, so-called because they can be decoded independently of any other frames. They may also be known as I-pictures, or keyframes due to their somewhat similar function to the key frames used in animation. I-frames can be considered effectively identical to baseline JPEG images.[10]
High-speed seeking through an MPEG-1 video is only possible to the nearest I-frame. When cutting a video it is not possible to start playback of a segment of video before the first I-frame in the segment (at least not without computationally intensive re-encoding). For this reason, I-frame-only MPEG videos are used in editing applications.
I-frame only compression is very fast, but produces very large file sizes: a factor of 3× (or more) larger than normally encoded MPEG-1 video, depending on how temporally complex a specific video is.[2] I-frame only MPEG-1 video is very similar to MJPEG video. So much so that very high-speed and theoretically lossless (in reality, there are rounding errors) conversion can be made from one format to the other, provided a couple of restrictions (color space and quantization matrix) are followed in the creation of the bitstream.[44]
The length between I-frames is known as the group of pictures (GOP) size. MPEG-1 most commonly uses a GOP size of 15-18. i.e. 1 I-frame for every 14-17 non-I-frames (some combination of P- and B- frames). With more intelligent encoders, GOP size is dynamically chosen, up to some pre-selected maximum limit.[10]
Limits are placed on the maximum number of frames between I-frames due to decoding complexing, decoder buffer size, recovery time after data errors, seeking ability, and accumulation of IDCT errors in low-precision implementations most common in hardware decoders (See: IEEE-1180).
P-frames
P-frame is an abbreviation for Predicted-frame. They may also be called forward-predicted frames, or inter-frames (B-frames are also inter-frames).
P-frames exist to improve compression by exploiting the temporal (over time) redundancy in a video. P-frames store only the difference in image from the frame (either an I-frame or P-frame) immediately preceding it (this reference frame is also called the anchor frame).
The difference between a P-frame and its anchor frame is calculated using motion vectors on each macroblock of the frame (see below). Such motion vector data will be embedded in the P-frame for use by the decoder.
A P-frame can contain any number of intra-coded blocks, in addition to any forward-predicted blocks.[45]
If a video drastically changes from one frame to the next (such as a cut), it is more efficient to encode it as an I-frame.
B-frames
B-frame stands for bidirectional-frame. They may also be known as backwards-predicted frames or B-pictures. B-frames are quite similar to P-frames, except they can make predictions using both the previous and future frames (i.e. two anchor frames).
It is therefore necessary for the player to first decode the next I- or P- anchor frame sequentially after the B-frame, before the B-frame can be decoded and displayed. This means decoding B-frames requires larger data buffers and causes an increased delay on both decoding and during encoding. This also necessitates the decoding time stamps (DTS) feature in the container/system stream (see above). As such, B-frames have long been subject of much controversy, they are often avoided in videos, and are sometimes not fully supported by hardware decoders.
No other frames are predicted from a B-frame. Because of this, a very low bitrate B-frame can be inserted, where needed, to help control the bitrate. If this was done with a P-frame, future P-frames would be predicted from it and would lower the quality of the entire sequence. However, similarly, the future P-frame must still encode all the changes between it and the previous I- or P- anchor frame. B-frames can also be beneficial in videos where the background behind an object is being revealed over several frames, or in fading transitions, such as scene changes.[2][10]
A B-frame can contain any number of intra-coded blocks and forward-predicted blocks, in addition to backwards-predicted, or bidirectionally predicted blocks.[10][45]
D-frames
MPEG-1 has a unique frame type not found in later video standards. D-frames or DC-pictures are independent images (intra-frames) that have been encoded DC-only (AC coefficients are removed—see DCT below) and hence are very low quality. D-frames are never referenced by I-, P- or B- frames. D-frames are only used for fast previews of video, for instance when seeking through a video at high speed.[2]
Given moderately higher-performance decoding equipment, this feature can be approximated by decoding I-frames instead. This provides higher quality previews, and without the need for D-frames taking up space in the stream, yet not improving video quality.
Macroblocks
Main article: MacroblockMPEG-1 operates on video in a series of 8x8 blocks for quantization. However, because chroma (color) is subsampled by a factor of 4, each pair of (red and blue) chroma blocks corresponds to 4 different luma blocks. This set of 6 blocks, with a resolution of 16x16, is called a macroblock.
A macroblock is the smallest independent unit of (color) video. Motion vectors (see below) operate solely at the macroblock level.
If the height and/or width of the video is not exact multiples of 16, a full row of macroblocks must still be encoded (though not displayed) to store the remainder of the picture (macroblock padding). This wastes a significant amount of data in the bitstream, and is to be strictly avoided.
Some decoders will also improperly handle videos with partial macroblocks, resulting in visible artifacts.
Motion vectors
To decrease the amount of spatial redundancy in a video, only blocks that change are updated, (up to the maximum GOP size). This is known as conditional replenishment. However, this is not very effective by itself. Movement of the objects, and/or the camera may result in large portions of the frame needing to be updated, even though only the position of the previously encoded objects has changed. Through motion estimation the encoder can compensate for this movement and remove a large amount of redundant information.
The encoder compares the current frame with adjacent parts of the video from the anchor frame (previous I- or P- frame) in a diamond pattern, up to a (encoder-specific) predefined radius limit from the area of the current macroblock. If a match is found, only the direction and distance (i.e. the vector of the motion) from the previous video area to the current macroblock need to be encoded into the inter-frame (P- or B- frame). The reverse of this process, performed by the decoder to reconstruct the picture, is called motion compensation.
A predicted macroblock rarely matches the current picture perfectly, however. The differences between the estimated matching area, and the real frame/macroblock is called the prediction error. The larger the error, the more data must be additionally encoded in the frame. For efficient video compression, it is very important that the encoder is capable of effectively and precisely performing motion estimation.
Motion vectors record the distance between two areas on screen based on the number of pixels (called pels). MPEG-1 video uses a motion vector (MV) precision of one half of one pixel, or half-pel. The finer the precision of the MVs, the more accurate the match is likely to be, and the more efficient the compression. There are trade-offs to higher precision, however. Finer MVs result in larger data size, as larger numbers must be stored in the frame for every single MV, increased coding complexity as increasing levels of interpolation on the macroblock are required for both the encoder and decoder, and diminishing returns (minimal gains) with higher precision MVs. Half-pel was chosen as the ideal trade-off. (See: qpel)
Because neighboring macroblocks are likely to have very similar motion vectors, this redundant information can be compressed quite effectively by being stored DPCM-encoded. Only the (smaller) amount of difference between the MVs for each macroblock needs to be stored in the final bitstream.
P-frames have 1 motion vector per macroblock, relative to the previous anchor frame. B-frames, however, can use 2 motion vectors; one from the previous anchor frame, and one from the future anchor frame.[45]
Partial macroblocks, and black borders/bars encoded into the video that do not fall exactly on a macroblock boundary, cause havoc with motion prediction. The block padding/border information prevents the macroblock from closely matching with any other area of the video, and so, significantly larger prediction error information must be encoded for every one of the several dozen partial macroblocks along the screen border. DCT encoding and quantization (see below) also isn't nearly as effective when there is large/sharp picture contrast in a block.
An even more serious problem exists with macroblocks that contain significant, random, edge noise, where the picture transitions to (typically) black. All the above problems also apply to edge noise. In addition, the added randomness is simply impossible to compress significantly. All of these effects will lower the quality (or increase the bitrate) of the video substantially.
DCT
Each 8x8 block is encoded by first applying a Forward Discrete Cosine Transform (FDCT) and then a quantization process. The FDCT process (by itself) is theoretically lossless, and can be reversed by applying an Inverse DCT (IDCT) to reproduce the original values (in the absence of any quantization and rounding errors). In reality, there are some (sometimes large) rounding errors introduced both by quantization in the encoder (as described in the next section) and by IDCT approximation error in the decoder. The minimum allowed accuracy of a decoder IDCT approximation is defined by ISO/IEC 23002-1. (Prior to 2006, it was specified by IEEE 1180-1990.)
The FDCT process converts the 8x8 block of uncompressed pixel values (brightness or color difference values) into an 8x8 indexed array of frequency coefficient values. One of these is the (statistically high in variance) DC coefficient, which represents the average value of the entire 8x8 block. The other 63 coefficients are the statistically smaller AC coefficients, which are positive or negative values each representing sinusoidal deviations from the flat block value represented by the DC coefficient.
An example of an encoded 8x8 FDCT block:
Since the DC coefficient value is statistically correlated from one block to the next, it is compressed using DPCM encoding. Only the (smaller) amount of difference between each DC value and the value of the DC coefficient in the block to its left needs to be represented in the final bitstream.
Additionally, the frequency conversion performed by applying the DCT provides a statistical decorrelation function to efficiently concentrate the signal into fewer high-amplitude values prior to applying quantization (see below).
Quantization
Quantization (of digital data) is, essentially, the process of reducing the accuracy of a signal, by dividing it into some larger step size (i.e. finding the nearest multiple, and discarding the remainder/modulus).
The frame-level quantizer is a number from 0 to 31 (although encoders will usually omit/disable some of the extreme values) which determines how much information will be removed from a given frame. The frame-level quantizer is either dynamically selected by the encoder to maintain a certain user-specified bitrate, or (much less commonly) directly specified by the user.
Contrary to popular belief, a fixed frame-level quantizer (set by the user) does not deliver a constant level of quality. Instead, it is an arbitrary metric that will provide a somewhat varying level of quality, depending on the contents of each frame. Given two files of identical sizes, the one encoded at an average bitrate should look better than the one encoded with a fixed quantizer (variable bitrate). Constant quantizer encoding can be used, however, to accurately determine the minimum and maximum bitrates possible for encoding a given video.
A quantization matrix is a string of 64-numbers (0-255) which tells the encoder how relatively important or unimportant each piece of visual information is. Each number in the matrix corresponds to a certain frequency component of the video image.
An example quantization matrix:
Quantization is performed by taking each of the 64 frequency values of the DCT block, dividing them by the frame-level quantizer, then dividing them by their corresponding values in the quantization matrix. Finally, the result is rounded down. This significantly reduces, or completely eliminates, the information in some frequency components of the picture. Typically, high frequency information is less visually important, and so high frequencies are much more strongly quantized (drastically reduced). MPEG-1 actually uses two separate quantization matrices, one for intra-blocks (I-blocks) and one for inter-block (P- and B- blocks) so quantization of different block types can be done independently, and so, more effectively.[2]
This quantization process usually reduces a significant number of the AC coefficients to zero, (known as sparse data) which can then be more efficiently compressed by entropy coding (lossless compression) in the next step.
An example quantized DCT block:
Quantization eliminates a large amount of data, and is the main lossy processing step in MPEG-1 video encoding. This is also the primary source of most MPEG-1 video compression artifacts, like blockiness, color banding, noise, ringing, discoloration, et al. This happens when video is encoded with an insufficient bitrate, and the encoder is therefore forced to use high frame-level quantizers (strong quantization) through much of the video.
Entropy coding
Several steps in the encoding of MPEG-1 video are lossless, meaning they will be reversed upon decoding, to produce exactly the same (original) values. Since these lossless data compression steps don't add noise into, or otherwise change the contents (unlike quantization), it is sometimes referred to as noiseless coding.[37] Since lossless compression aims to remove as much redundancy as possible, it is known as entropy coding in the field of information theory.
The DCT block tend to have the most important frequencies towards the top left corner. The coefficients tend to zero towards the bottom-right. Maximum compression can be achieved by a zig-zag scanning of the DCT block starting from the top left and using Run-length encoding techniques.
The DC coefficients and motion vectors are DPCM-encoded.
Run-length encoding (RLE) is a very simple method of compressing repetition. A sequential string of characters, no matter how long, can be replaced with a few bytes, noting the value that repeats, and how many times. For example, if someone were to say "five nines", you would know they mean the number: 99999.
RLE is particularly effective after quantization, as a significant number of the AC coefficients are now zero (called sparse data), and can be represented with just a couple bytes. This is stored in a special 2-dimensional Huffman table that codes the run-length and the run-ending character.
Huffman Coding is a very popular method of entropy coding, and used in MPEG-1 video to reduce the data size. The data is analyzed to find strings that repeat often. Those strings are then put into a special table, with the most frequently repeating data assigned the shortest code. This keeps the data as small as possible with this form of compression.[37] Once the table is constructed, those strings in the data are replaced with their (much smaller) codes, which reference the appropriate entry in the table. The decoder simply reverses this process to produce the original data.
This is the final step in the video encoding process, so the result of Huffman coding is known as the MPEG-1 video "bitstream."
GOP configurations for specific applications
I-frames store complete frame info within the frame and is therefore suited for random access. P-frames provide compression using motion vectors relative to the previous frame ( I or P ). B-frames provide maximum compression but requires the previous as well as next frame for computation. Therefore, processing of B-frames require more buffer on the decoded side. A configuration of the Group of Pictures (GOP) should be selected based on these factors. I-frame only sequences gives least compression, but is useful for random access, FF/FR and editability. I and P frame sequences give moderate compression but add a certain degree of random access, FF/FR functionality. I,P & B frame sequences give very high compression but also increases the coding/decoding delay significantly. Such configurations are therefore not suited for video-telephony or video-conferencing applications.
The typical data rate of an I-frame is 1 bit per pixel while that of a P-frame is 0.1 bit per pixel and for a B-frame, 0.015 bit per pixel.[46]
Part 3: Audio
Part 3 of the MPEG-1 standard covers audio and is defined in ISO/IEC-11172-3.
MPEG-1 Audio utilizes psychoacoustics to significantly reduce the data rate required by an audio stream. It reduces or completely discards certain parts of the audio that the human ear can't hear, either because they are in frequencies where the ear has limited sensitivity, or are masked by other (typically louder) sounds.[47]
Channel Encoding:
- Mono
- Joint Stereo – intensity encoded
- Joint Stereo – M/S encoded for Layer 3 only
- Stereo
- Dual (two uncorrelated mono channels)
- Sampling rates: 32000, 44100, and 48000 Hz
- Bitrates: 32, 48, 56, 64, 80, 96, 112, 128, 160, 192, 224, 256, 320 and 384 kbit/s
MPEG-1 Audio is divided into 3 layers. Each higher layer is more computationally complex, and generally more efficient at lower bitrates than the previous.[10] The layers are semi backwards compatible as higher layers reuse technologies implemented by the lower layers. A "Full" Layer II decoder can also play Layer I audio, but not Layer III audio, although not all higher level players are "full".[47]
Layer I
Main article: MPEG-1 Audio Layer IMPEG-1 Layer I is nothing more than a simplified version of Layer II.[12] Layer I uses a smaller 384-sample frame size for very low delay, and finer resolution.[20] This is advantageous for applications like teleconferencing, studio editing, etc. It has lower complexity than Layer II to facilitate real-time encoding on the hardware available circa 1990.[37]
Layer I saw limited adoption in its time, and most notably was used on Philips' defunct Digital Compact Cassette at a bitrate of 384 kbit/s.[1] With the substantial performance improvements in digital processing since its introduction, Layer I quickly became unnecessary and obsolete.
Layer I audio files typically use the extension .mp1 or sometimes .m1a
Layer II
Main article: MPEG-1 Audio Layer IIMPEG-1 Layer II (MP2—often incorrectly called MUSICAM)[47] is a lossy audio format designed to provide high quality at about 192 kbit/s for stereo sound. Decoding MP2 audio is computationally simple, relative to MP3, AAC, etc.
History/MUSICAM
MPEG-1 Layer II was derived from the MUSICAM (Masking pattern adapted Universal Subband Integrated Coding And Multiplexing) audio codec, developed by Centre commun d'études de télévision et télécommunications (CCETT), Philips, and Institut für Rundfunktechnik (IRT/CNET)[10][12][48] as part of the EUREKA 147 pan-European inter-governmental research and development initiative for the development of digital audio broadcasting.
Most key features of MPEG-1 Audio were directly inherited from MUSICAM, including the filter bank, time-domain processing, audio frame sizes, etc. However, improvements were made, and the actual MUSICAM algorithm was not used in the final MPEG-1 Layer II audio standard. The widespread usage of the term MUSICAM to refer to Layer II is entirely incorrect and discouraged for both technical and legal reasons.[47]
Technical details
Layer II/MP2 is a time-domain encoder. It uses a low-delay 32 sub-band polyphased filter bank for time-frequency mapping; having overlapping ranges (i.e. polyphased) to prevent aliasing.[49] The psychoacoustic model is based on the principles of auditory masking, simultaneous masking effects, and the absolute threshold of hearing (ATH). The size of a Layer II frame is fixed at 1152-samples (coefficients).
Time domain refers to how analysis and quantization is performed: on short, discrete samples/chunks of the audio waveform. This offers low delay as only a small number of samples are analyzed before encoding, as opposed to frequency domain encoding (like MP3) which must analyze many times more samples before it can decide how to transform and output encoded audio. This also offers higher performance on complex, random and transient impulses (such as percussive instruments, and applause), offering avoidance of artifacts like pre-echo.
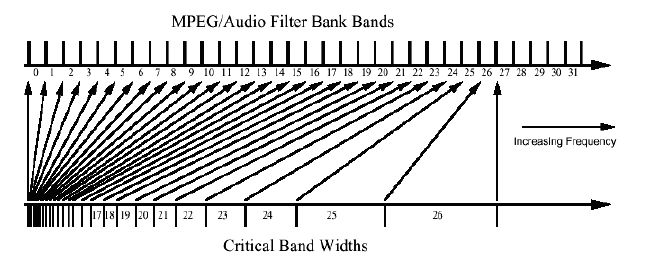
 Visualization of the 32 sub-band filter bank used by MPEG-1 Audio, showing the disparity between the equal band-size of MP2 and the varying width of critical bands ("barks").
Visualization of the 32 sub-band filter bank used by MPEG-1 Audio, showing the disparity between the equal band-size of MP2 and the varying width of critical bands ("barks").The 32 sub-band filter bank returns 32 amplitude coefficients, one for each equal-sized frequency band/segment of the audio, which is about 700 Hz wide (depending on the audio's sampling frequency). The encoder then utilizes the psychoacoustic model to determine which sub-bands contain audio information that is less important, and so, where quantization will be inaudible, or at least much less noticeable.[37]
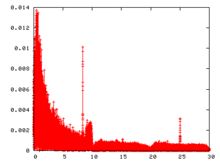 Example FFT analysis on an audio wave sample.
Example FFT analysis on an audio wave sample.The psychoacoustic model is applied using a 1024-point Fast Fourier Transform (FFT). Of the 1152 samples per frame, 64 samples at the top and bottom of the frequency range are ignored for this analysis. They are presumably not significant enough to change the result. The psychoacoustic model uses an empirically determined masking model to determine which sub-bands contribute more to the masking threshold, and how much quantization noise each can contain without being perceived. Any sounds below the absolute threshold of hearing (ATH) are completely discarded. The available bits are then assigned to each sub-band accordingly.[47][49]
Typically, sub-bands are less important if they contain quieter sounds (smaller coefficient) than a neighboring (i.e. similar frequency) sub-band with louder sounds (larger coefficient). Also, "noise" components typically have a more significant masking effect than "tonal" components.[48]
Less significant sub-bands are reduced in accuracy by quantization. This basically involves compressing the frequency range (amplitude of the coefficient), i.e. raising the noise floor. Then computing an amplification factor, for the decoder to use to re-expand each sub-band to the proper frequency range.[50][51]
Layer II can also optionally use intensity stereo coding, a form of joint stereo. This means that the frequencies above 6 kHz of both channels are combined/down-mixed into one single (mono) channel, but the "side channel" information on the relative intensity (volume, amplitude) of each channel is preserved and encoded into the bitstream separately. On playback, the single channel is played through left and right speakers, with the intensity information applied to each channel to give the illusion of stereo sound.[37][48] This perceptual trick is known as stereo irrelevancy. This can allow further reduction of the audio bitrate without much perceivable loss of fidelity, but is generally not used with higher bitrates as it does not provide very high quality (transparent) audio.[37][49][52][53]
Quality
Subjective audio testing by experts, in the most critical conditions ever implemented, has shown MP2 to offer transparent audio compression at 256 kbit/s for 16-bit 44.1 kHz CD audio using the earliest reference implementation (more recent encoders should presumably perform even better).[1][48][49][54] That (approximately) 1:6 compression ratio for CD audio is particularly impressive because it is quite close to the estimated upper limit of perceptual entropy, at just over 1:8.[55][56] Achieving much higher compression is simply not possible without discarding some perceptible information.[citation needed][dubious ]
MP2 remains a favoured lossy audio coding standard due to its particularly high audio coding performances on important audio material such as castanet, symphonic orchestra, male and female voices and particularly complex and high energy transients (impulses) like percussive sounds: triangle, glockenspiel and audience applause.[20] More recent testing has shown that MPEG Multichannel (based on MP2), despite being compromised by an inferior matrixed mode (for the sake of backwards compatibility)[1][49] rates just slightly lower than much more recent audio codecs, such as Dolby Digital (AC-3) and Advanced Audio Coding (AAC) (mostly within the margin of error—and substantially superior in some cases, such as audience applause).[57][58] This is one reason that MP2 audio continues to be used extensively. The MPEG-2 AAC Stereo verification tests reached a vastly different conclusion, however, showing AAC to provide superior performance to MP2 at half the bitrate.[59] The reason for this disparity with both earlier and later tests is not clear, but strangely, a sample of applause is notably absent from this test.[dubious ]
Layer II audio files typically use the extension .mp2 or sometimes .m2a
Layer III/MP3
Main article: MPEG-1 Audio Layer IIIMPEG-1 Layer III (MP3) is a lossy audio format designed to provide acceptable quality at about 64 kbit/s for monaural audio over single-channel (BRI) ISDN links, and 128 kbit/s for stereo sound.
History/ASPEC
Layer III/MP3 was derived from the Adaptive Spectral Perceptual Entropy Coding (ASPEC) codec developed by Fraunhofer as part of the EUREKA 147 pan-European inter-governmental research and development initiative for the development of digital audio broadcasting. ASPEC was adapted to fit in with the Layer II/MUSICAM model (frame size, filter bank, FFT, etc.), to become Layer III.[12]
ASPEC was itself based on Multiple adaptive Spectral audio Coding (MSC) by E. F. Schroeder, Optimum Coding in the Frequency domain (OCF) the doctoral thesis by Karlheinz Brandenburg at the University of Erlangen-Nuremberg, Perceptual Transform Coding (PXFM) by J. D. Johnston at AT&T Bell Labs, and Transform coding of audio signals by Y. Mahieux and J. Petit at Institut für Rundfunktechnik (IRT/CNET).[60]
Technical details
MP3 is a frequency-domain audio transform encoder. Even though it utilizes some of the lower layer functions, MP3 is quite different from Layer II/MP2.
MP3 works on 1152 samples like Layer II, but needs to take multiple frames for analysis before frequency-domain (MDCT) processing and quantization can be effective. It outputs a variable number of samples, using a bit buffer to enable this variable bitrate (VBR) encoding while maintaining 1152 sample size output frames. This causes a significantly longer delay before output, which has caused MP3 to be considered unsuitable for studio applications where editing or other processing needs to take place.[49]
MP3 does not benefit from the 32 sub-band polyphased filter bank, instead just using an 18-point MDCT transformation on each output to split the data into 576 frequency components, and processing it in the frequency domain.[48] This extra granularity allows MP3 to have a much finer psychoacoustic model, and more carefully apply appropriate quantization to each band, providing much better low-bitrate performance.
Frequency-domain processing imposes some limitations as well, causing a factor of 12 or 36 × worse temporal resolution than Layer II. This causes quantization artifacts, due to transient sounds like percussive events and other high-frequency events that spread over a larger window. This results in audible smearing and pre-echo.[49] MP3 uses pre-echo detection routines, and VBR encoding, which allows it to temporarily increase the bitrate during difficult passages, in an attempt to reduce this effect. It is also able to switch between the normal 36 sample quantization window, and instead using 3× short 12 sample windows instead, to reduce the temporal (time) length of quantization artifacts.[49] And yet in choosing a fairly small window size to make MP3's temporal response adequate enough to avoid the most serious artifacts, MP3 becomes much less efficient in frequency domain compression of stationary, tonal components.
Being forced to use a hybrid time domain (filter bank) /frequency domain (MDCT) model to fit in with Layer II simply wastes processing time and compromises quality by introducing aliasing artifacts. MP3 has an aliasing cancellation stage specifically to mask this problem, but which instead produces frequency domain energy which must be encoded in the audio. This is pushed to the top of the frequency range, where most people have limited hearing, in hopes the distortion it causes will be less audible.
Layer II's 1024 point FFT doesn't entirely cover all samples, and would omit several entire MP3 sub-bands, where quantization factors must be determined. MP3 instead uses two passes of FFT analysis for spectral estimation, to calculate the global and individual masking thresholds. This allows it to cover all 1152 samples. Of the two, it utilizes the global masking threshold level from the more critical pass, with the most difficult audio.
In addition to Layer II's intensity encoded joint stereo, MP3 can use middle/side (mid/side, m/s, MS, matrixed) joint stereo. With mid/side stereo, certain frequency ranges of both channels are merged into a single (middle, mid, L+R) mono channel, while the sound difference between the left and right channels is stored as a separate (side, L-R) channel. Unlike intensity stereo, this process does not discard any audio information. When combined with quantization, however, it can exaggerate artifacts.
If the difference between the left and right channels is small, the side channel will be small, which will offer as much as a 50% bitrate savings, and associated quality improvement. If the difference between left and right is large, standard (discrete, left/right) stereo encoding may be preferred, as mid/side joint stereo will not provide any benefits. An MP3 encoder can switch between m/s stereo and full stereo on a frame-by-frame basis.[48] [53][61]
Unlike Layers I/II, MP3 uses variable-length Huffman coding (after perceptual) to further reduce the bitrate, without any further quality loss.[47][49]
Quality
These technical limitations inherently prevent MP3 from providing critically transparent quality at any bitrate. This makes Layer II sound quality actually superior to MP3 audio, when it is used at a high enough bitrate to avoid noticeable artifacts. The term "transparent" often gets misused, however. The quality of MP3 (and other codecs) is sometimes called "transparent," even at impossibly low bitrates, when what is really meant is "good quality on average/non-critical material," or perhaps "exhibiting only non-annoying artifacts."
MP3's more fine-grained and selective quantization does prove notably superior to Layer II/MP2 at lower-bitrates, however. It is able to provide nearly equivalent audio quality to Layer II, at a 15% lower bitrate (approximately).[58][59] 128 kbit/s is considered the "sweet spot" for MP3; meaning it provides generally acceptable quality stereo sound on most music, and there are diminishing quality improvements from increasing the bitrate further. MP3 is also regarded as exhibiting artifacts that are less annoying than Layer II, when both are used at bitrates that are too low to possibly provide faithful reproduction.
Layer III audio files use the extension .mp3.
MPEG-2 audio extensions
The MPEG-2 standard includes several extensions to MPEG-1 Audio.[49] These are known as MPEG-2 BC – backwards compatible with MPEG-1 Audio.[62][63][64][65] MPEG-2 Audio is defined in ISO/IEC 13818-3
- MPEG Multichannel – Backward compatible 5.1-channel surround sound.[19]
- Sampling rates: 16000, 22050, and 24000 Hz
- Bitrates: 8, 16, 24, 40, 48, and 144 kbit/s
These sampling rates are exactly half that of those originally defined for MPEG-1 Audio. They were introduced to maintain higher quality sound when encoding audio at lower-bitrates.[19] The even-lower bitrates were introduced because tests showed that MPEG-1 Audio could provide higher quality than any existing (circa 1994) very low bitrate (i.e. speech) audio codecs.[66]
Part 4: Conformance testing
Part 4 of the MPEG-1 standard covers conformance testing, and is defined in ISO/IEC-11172-4.
Conformance: Procedures for testing conformance.
Provides two sets of guidelines and reference bitstreams for testing the conformance of MPEG-1 audio and video decoders, as well as the bitstreams produced by an encoder.[10][17]
Part 5: Reference software
Part 5 of the MPEG-1 standard includes reference software, and is defined in ISO/IEC TR 11172-5.
Simulation: Reference software.
C reference code for encoding and decoding of audio and video, as well as multiplexing and demultiplexing.[10][17]
This includes the ISO Dist10 audio encoder code, which LAME and TooLAME were originally based upon.
File extension
.mpg is one of a number of file extensions for MPEG-1 or MPEG-2 audio and video compression. MPEG-1 Part 2 video is rare nowadays, and this extension typically refers to an MPEG program stream (defined in MPEG-1 and MPEG-2) or MPEG transport stream (defined in MPEG-2). Other suffixes such as .m2ts also exists specifying the precise container, in this case MPEG-2 TS, but this has little relevance to MPEG-1 media.
.mp3 is the most common extension for files containing MPEG-1 Layer 3 audio. An MP3 file is typically an uncontained stream of raw audio; the conventional way to tag MP3 files is by writing data to "garbage" segments of each frame, which preserve the media information but are discarded by the player. This is similar in many respects to how raw .AAC files are tagged (but this is less supported nowadays, e.g. iTunes).
Note that although it would apply, .mpg does not normally append raw AAC or AAC in MPEG-2 Part 7 Containers. The .aac extension normally denotes these audio files.
See also
- MPEG The Moving Picture Experts Group, developers of the MPEG-1 standard
- MP3 More (less technical) detail about MPEG-1 Layer III audio
- MPEG Multichannel Backwards compatible 5.1 channel surround sound extension to Layer II audio
- MPEG-2 The direct successor to the MPEG-1 standard.
- Implementations
- Libavcodec includes MPEG-1/2 video/audio encoders and decoders
- Mjpegtools MPEG-1/2 video/audio encoders
- TooLAME A high quality MPEG-1 Layer II audio encoder.
- LAME A high quality MP3 (Layer III) audio encoder.
- Musepack A format originally based on MPEG-1 Layer II audio, but now incompatible.
References
- ^ a b c d e f Adler, Mark; Popp, Harald; Hjerde, Morten (November 9, 1996), MPEG-FAQ: multimedia compression [1/9], faqs.org, http://www.faqs.org/faqs/mpeg-faq/part1/, retrieved 2008-04-09
- ^ a b c d e f g h Le Gall, Didier (April, 1991) (PDF), MPEG: a video compression standard for multimedia applications, Communications of the ACM, http://www.cis.temple.edu/~vasilis/Courses/CIS750/Papers/mpeg_6.pdf, retrieved 2008-04-09
- ^ Chiariglione, Leonardo (October 21, 1989), Kurihama 89 press release, ISO/IEC, http://mpeg.chiariglione.org/meetings/kurihama89/kurihama_press.htm, retrieved 2008-04-09
- ^ a b ISO/IEC JTC 1/SC 29 (2009-10-30). "Programme of Work — Allocated to SC 29/WG 11, MPEG-1 (Coding of moving pictures and associated audio for digital storage media at up to about 1,5 Mbit/s)". http://www.itscj.ipsj.or.jp/sc29/29w42911.htm. Retrieved 2009-11-10.
- ^ ISO. "ISO/IEC 11172-1:1993 - Information technology -- Coding of moving pictures and associated audio for digital storage media at up to about 1,5 Mbit/s -- Part 1: Systems". http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=19180. Retrieved 2009-11-10.
- ^ MPEG. "About MPEG - Achievements". chiariglione.org. http://mpeg.chiariglione.org/achievements.htm. Retrieved 2009-10-31.
- ^ MPEG. "Terms of Reference". chiariglione.org. http://mpeg.chiariglione.org/terms_of_reference.htm. Retrieved 2009-10-31.
- ^ a b MPEG. "MPEG standards - Full list of standards developed or under development". chiariglione.org. http://mpeg.chiariglione.org/standards.htm. Retrieved 2009-10-31.
- ^ Fogg, Chad (April 2, 1996), MPEG-2 FAQ, University of California, Berkeley, http://bmrc.berkeley.edu/research/mpeg/faq/mpeg2-v38/faq_v38.html, retrieved 2008-04-09
- ^ a b c d e f g h i j k l Fogg, Chad (April 2, 1996), MPEG-2 FAQ (archived website), University of California, Berkeley, archived from the original on 2008-06-16, http://web.archive.org/web/20080616113041/http://bmrc.berkeley.edu/research/mpeg/faq/mpeg2-v38/faq_v38.html, retrieved 2010-08-03
- ^ Chiariglione, Leonardo (March, 2001), Open source in MPEG, Linux Journal, http://leonardo.chiariglione.org/publications/linux/linux00.htm, retrieved 2008-04-09
- ^ a b c d Chiariglione, Leonardo; Le Gall, Didier; Musmann, Hans-Georg; Simon, Allen (September, 1990), Press Release - Status report of ISO MPEG, ISO/IEC, http://mpeg.chiariglione.org/meetings/santa_clara90/santa_clara_press.htm, retrieved 2008-04-09
- ^ Meetings, ISO/IEC, http://mpeg.chiariglione.org/meetings.htm, retrieved 2008-04-09
- ^ a b http://bmrc.berkeley.edu/research/mpeg/software/Old/mpegfa31.txt Q. Well, then how do I get the documents, like the MPEG I draft? A. MPEG is a draft ISO standard. It's exact name is ISO CD 11172. ... You may order it from your national standards body (e.g. ANSI in the USA) or buy it from companies like OMNICOM ...
- ^ International Organisation For Standardisation Organisation Internationale De Normalisation Iso
- ^ http://bmrc.berkeley.edu/research/publications/1992/101/101.html http://bmrc.berkeley.edu/frame/research/mpeg/ A Continuous Media Player, Lawrence A. Rowe and Brian C. Smith, Proc. 3rd Int. Workshop on Network and OS Support for Digital Audio and Video, San Diego CA (November 1992)
- ^ a b c Achievements, ISO/IEC, http://mpeg.chiariglione.org/achievements.htm, retrieved 2008-04-03
- ^ Chiariglione, Leonardo (November 6, 1992), MPEG Press Release, London, 6 November 1992, ISO/IEC, http://mpeg.chiariglione.org/meetings/london/london_press.htm, retrieved 2008-04-09
- ^ a b c Wallace, Greg (April 2, 1993), Press Release, ISO/IEC, http://mpeg.chiariglione.org/meetings/sydney93/sydney_press.htm, retrieved 2008-04-09
- ^ a b c d Popp, Harald; Hjerde, Morten (November 9, 1996), MPEG-FAQ: multimedia compression [2/9], faqs.org, http://www.faqs.org/faqs/mpeg-faq/part2/, retrieved 2008-04-10
- ^ International Organisation For Standardisation Organisation Internationale De Normalisation Iso
- ^ ISO. "ISO/IEC 11172-1:1993 - Information technology -- Coding of moving pictures and associated audio for digital storage media at up to about 1,5 Mbit/s -- Part 1: Systems". http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=19180. Retrieved 2010-07-18.
- ^ ISO. "ISO/IEC 11172-2:1993 - Information technology -- Coding of moving pictures and associated audio for digital storage media at up to about 1,5 Mbit/s -- Part 2: Video". http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=22411. Retrieved 2010-07-18.
- ^ ISO. "ISO/IEC 11172-3:1993 - Information technology -- Coding of moving pictures and associated audio for digital storage media at up to about 1,5 Mbit/s -- Part 3: Audio". http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=22412. Retrieved 2010-07-18.
- ^ ISO. "ISO/IEC 11172-4:1995 - Information technology -- Coding of moving pictures and associated audio for digital storage media at up to about 1,5 Mbit/s -- Part 4: Compliance testing". http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=22691. Retrieved 2010-07-18.
- ^ ISO. "ISO/IEC TR 11172-5:1998 - Information technology -- Coding of moving pictures and associated audio for digital storage media at up to about 1,5 Mbit/s -- Part 5: Software simulation". http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=25029. Retrieved 2010-07-18.
- ^ Ozer, Jan (October 12, 2001), Choosing the Optimal Video Resolution: The MPEG-2 Player Market, extremetech.com, http://www.extremetech.com/article2/0,1697,1153916,00.asp, retrieved 2008-04-09
- ^ Comparison between MPEG 1 & 2, snazzizone.com, http://www.snazzizone.com/TP09.html, retrieved 2008-04-09
- ^ MPEG 1 And 2 Compared, Pure Motion Ltd., 2003, http://213.130.34.82/resources/technical/mpegcompared/index.htm, retrieved 2008-04-09
- ^ [homework] summary of the video (and audio) codec discussion from Dave Singer on 2007-11-09 (public-html@w3.org from November 2007)
- ^ MPEG-1 Video Coding (H.261)
- ^ ISO Patent DatabaseISO JTC1 Patent Database Search for 11172 in page
- ^ Performance of a Software MPEG Video Decoder Reference 3 in the paper is to Committee Draft of Standard ISO/IEC 11172, December 6, 1991
- ^ Patent Status of MPEG-1,H.261 and MPEG-2
- ^ "[gst-devel] Can a MPEG-1 with Audio Layers 1&2 plugin be in plugins-good (patentwise)?". SourceForge.net. 2008-08-23. http://sourceforge.net/mailarchive/message.php?msg_id=20163106. Retrieved 2011-03-04.
- ^ http://lists.whatwg.org/pipermail/whatwg-whatwg.org/2009-May/020015.html http://patft1.uspto.gov/netacgi/nph-Parser?patentnumber=5214678 "Digital transmission system using subband coding of a digital signal" Filed: May 31, 1990, Granted May 25, 1993, Expires May 31, 2010?
- ^ a b c d e f g Grill, B.; Quackenbush, S. (October 2005), MPEG-1 Audio, ISO/IEC, http://mpeg.chiariglione.org/technologies/mpeg-1/mp01-aud/index.htm, retrieved 2009-12-29
- ^ Chiariglione, Leonardo, MPEG-1 Systems, ISO/IEC, http://mpeg.chiariglione.org/faq/mp1-sys/mp1-sys.htm, retrieved 2008-04-09
- ^ a b Pack Header, http://dvd.sourceforge.net/dvdinfo/packhdr.html, retrieved 2008-04-07
- ^ Fimoff, Mark; Bretl, Wayne E. (December 1, 1999), MPEG2 Tutorial, http://www.bretl.com/mpeghtml/STC.HTM, retrieved 2008-04-09
- ^ Fimoff, Mark; Bretl, Wayne E. (December 1, 1999), MPEG2 Tutorial, http://www.bretl.com/mpeghtml/PTS.HTM, retrieved 2008-04-09
- ^ Fimoff, Mark; Bretl, Wayne E. (December 1, 1999), MPEG2 Tutorial, http://www.bretl.com/mpeghtml/DTS.HTM, retrieved 2008-04-09
- ^ Fimoff, Mark; Bretl, Wayne E. (December 1, 1999), MPEG2 Tutorial, http://www.bretl.com/mpeghtml/VBV.HTM, retrieved 2008-04-09
- ^ Acharya, Soam; Smith, Brian (1998), Compressed Domain Transcoding of MPEG, Cornell University, IEEE Computer Society, ICMCS, pp. 3, http://citeseer.ist.psu.edu/acharya98compressed.html, retrieved 2008-04-09 - (Requires clever reading: says quantization matrices differ, but those are just defaults, and selectable)
- ^ a b c Wee, Susie J.; Vasudev, Bhaskaran; Liu, Sam (March 13, 1997) [1], Transcoding MPEG Video Streams in the Compressed Domain, HP, archived from the original on 2007-08-17, http://web.archive.org/web/20070817191927/http://www.hpl.hp.com/personal/Susie_Wee/PAPERS/hpidc97/hpidc97.html, retrieved 2008-04-01
- ^ http://bmrc.berkeley.edu/frame/research/mpeg/mpeg_overview.html
- ^ a b c d e f Thom, D.; Purnhagen, H. (October 1998), MPEG Audio FAQ Version 9, ISO/IEC, http://mpeg.chiariglione.org/faq/mp1-aud/mp1-aud.htm, retrieved 2008-04-09
- ^ a b c d e f Church, Steve, Perceptual Coding and MPEG Compression, NAB Engineering Handbook, Telos Systems, http://www.telos-systems.com/techtalk/mpeg/default.htm, retrieved 2008-04-09
- ^ a b c d e f g h i j Pan, Davis (Summer, 1995) (PDF), A Tutorial on MPEG/Audio Compression, IEEE Multimedia Journal, pp. 8, http://www.cs.columbia.edu/~coms6181/slides/6R/mpegaud.pdf, retrieved 2008-04-09
- ^ Smith, Brian (1996), A Survey of Compressed Domain Processing Techniques, Cornell University, pp. 7, http://citeseer.ist.psu.edu/257196.html, retrieved 2008-04-09
- ^ Cheng, Mike, Psychoacoustic Models in TooLAME/TwoLAME, twolame.org, http://www.twolame.org/doc/psycho.html, retrieved 2008-04-09
- ^ Grill, B.; Quackenbush, S. (October 2005), MPEG-1 Audio, archive.org, archived from the original on 2008-04-27, http://web.archive.org/web/20080427195833/http://www.chiariglione.org/mpeg/technologies/mp01-aud/index.htm, retrieved 2009-12-29
- ^ a b Herre, Jurgen (October 5, 2004) (PDF), From Joint Stereo to Spatial Audio Coding, Conference on Digital Audio Effects, pp. 2, http://dafx04.na.infn.it/WebProc/Proc/P_157.pdf, retrieved 2008-04-17
- ^ C.Grewin, and T.Ryden, Subjective Assessments on Low Bit-rate Audio Codecs, Proceedings of the 10th International AES Conference, pp 91 - 102, London 1991
- ^ J. Johnston, Estimation of Perceptual Entropy Using Noise Masking Criteria, in Proc. ICASSP-88, pp. 2524-2527, May 1988.
- ^ J. Johnston, Transform Coding of Audio Signals Using Perceptual Noise Criteria, IEEE Journal Select Areas in Communications, vol. 6, no. 2, pp. 314-323, Feb. 1988.
- ^ Wustenhagen et al., Subjective Listening Test of Multi-channel Audio Codecs, AES 105th Convention Paper 4813, San Francisco 1998
- ^ a b B/MAE Project Group (September, 2007) (PDF), EBU evaluations of multichannel audio codecs, European Broadcasting Union, http://www.ebu.ch/CMSimages/en/tec_doc_t3324-2007_tcm6-53801.pdf, retrieved 2008-04-09
- ^ a b Meares, David; Watanabe, Kaoru; Scheirer, Eric (February, 1998) (PDF), Report on the MPEG-2 AAC Stereo Verification Tests, ISO/IEC, pp. 18, http://sound.media.mit.edu/mpeg4/audio/public/w2006.pdf, retrieved 2008-04-16[dead link]
- ^ Painter, Ted; Spanias, Andreas (April, 2000) (PDF), Perceptual Coding of Digital Audio (PROCEEDINGS OF THE IEEE, VOL. 88, NO. 4), PROCEEDINGS OF THE IEEE, http://www.ee.columbia.edu/~marios/courses/e6820y02/project/papers/Perceptual%20coding%20of%20digital%20audio%20.pdf, retrieved 2008-04-01[dead link]
- ^ Amorim, Roberto (September 19, 2006), GPSYCHO - Mid/Side Stereo, LAME, http://lame.sourceforge.net/ms_stereo.php, retrieved 2008-04-17
- ^ ISO (1998-10). "MPEG Audio FAQ Version 9 – MPEG-1 and MPEG-2 BC". ISO. http://mpeg.chiariglione.org/faq/mp1-aud/mp1-aud.htm. Retrieved 2009-10-28.
- ^ D. Thom, H. Purnhagen, and the MPEG Audio Subgroup (1998-10). "MPEG Audio FAQ Version 9 - MPEG Audio". http://mpeg.chiariglione.org/faq/audio.htm. Retrieved 2009-10-31.
- ^ MPEG.ORG. "AAC". http://www.mpeg.org/MPEG/audio/aac.html. Retrieved 2009-10-28.
- ^ ISO (2006-01-15) (PDF), ISO/IEC 13818-7, Fourth edition, Part 7 – Advanced Audio Coding (AAC), http://webstore.iec.ch/preview/info_isoiec13818-7%7Bed4.0%7Den.pdf, retrieved 2009-10-28
- ^ Chiariglione, Leonardo (November 11, 1994), Press Release, ISO/IEC, http://mpeg.chiariglione.org/meetings/singapore94/singapore_press.htm, retrieved 2008-04-09
External links
- Official Web Page of the Moving Picture Experts Group (MPEG) a working group of ISO/IEC
- MPEG Industry Forum Organization
- Source Code to Implement MPEG-1
- A simple, concise explanation from Berkeley Multimedia Research Center
MPEG-1 • 2 • 3 • 4 • 7 • 21 • A • B • C • D • E • V • M • U MPEG-1 Parts MPEG-2 Parts Part 1: Systems (Transport stream · Program stream) · Part 2: Video (H.262) · Part 3: Audio (Layer I · Layer II · Layer III · MPEG Multichannel) · Part 6: DSM CC · Part 7: Advanced audio codingMPEG-4 Parts Part 2: Video · Part 3: Audio · Part 6: DMIF · Part 10: Advanced Video Coding (H.264) · Part 11: Scene description · Part 12: ISO base media file format · Part 14: MP4 file format · Part 17: Streaming text format · Part 20: LASeRMPEG-7 Parts MPEG-21 Parts Parts 2, 3 and 9: Digital Item · Part 5: Rights Expression LanguageMPEG-D Parts Part 1: MPEG Surround · Part 3: Unified Speech and Audio CodingMultimedia compression and container formats Video OthersAudio MPEG-1 Layer III (MP3) · MPEG-1 Layer II (Multichannel) · MPEG-1 Layer I · AAC · HE-AAC · MPEG Surround · MPEG-4 ALS · MPEG-4 SLS · MPEG-4 DST · MPEG-4 HVXC · MPEG-4 CELP · USACOthersAC-3 · AMR · AMR-WB · AMR-WB+ · Apple Lossless · Asao · ATRAC · CELT · DRA · DTS · EVRC · EVRC-B · FLAC · GSM-HR · GSM-FR · GSM-EFR · iLBC · iSAC · Monkey's Audio · TTA (True Audio) · MT9 · A-law · μ-law · Musepack · OptimFROG · Opus · OSQ · QCELP · RealAudio · RTAudio · SD2 · SHN · SILK · Siren · SMV · Speex · SVOPC · TwinVQ · VMR-WB · Vorbis · WavPack · WMAImage OthersContainers ISO/IECITU-TOthersSee Compression methods for methods and Compression software implementations for codecs Data compression methods Information theory Lossless Shannon–Fano · Shannon–Fano–Elias · Huffman · Adaptive Huffman · Arithmetic · Range · Golomb · Universal (Gamma · Exp-Golomb · Fibonacci · Levenshtein)RLE · Byte pair encoding · DEFLATE · Lempel–Ziv (LZ77/78 · LZSS · LZW · LZWL · LZO · LZMA · LZX · LZRW · LZJB · LZS · LZT · ROLZ) · Statistical Lempel ZivOthersAudio Audio codec partsOthersImage TermsMethodsOthersVideo TermsVideo characteristics · Frame · Frame rate · Interlace · Frame types · Video quality · Video resolutionOthersSee Compression formats for formats and Compression software implementations for codecs Categories:- Audio codecs
- Video codecs
- MPEG





Wikimedia Foundation. 2010.