- MIMD
-
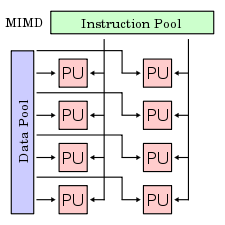
Flynn's taxonomy Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD In computing, MIMD (multiple instruction, multiple data) is a technique employed to achieve parallelism. Machines using MIMD have a number of processors that function asynchronously and independently. At any time, different processors may be executing different instructions on different pieces of data. MIMD architectures may be used in a number of application areas such as computer-aided design/computer-aided manufacturing, simulation, modeling, and as communication switches. MIMD machines can be of either shared memory or distributed memory categories. These classifications are based on how MIMD processors access memory. Shared memory machines may be of the bus-based, extended, or hierarchical type. Distributed memory machines may have hypercube or mesh interconnection schemes.
Contents
The processors are all connected to a "globally available" memory, via either a software or hardware means. The operating system usually maintains its memory coherence.[1]
From a programmer's point-of-view, this memory model is better understood than the distributed memory model. Another advantage is that memory coherence is managed by the operating system and not the written program. Two known disadvantages are: scalability beyond thirty-two processors is difficult, and the shared memory model is less flexible than the distributed memory model.[1]
There are many examples of shared memory (multiprocessors): UMA (Uniform Memory Access), COMA (Cache Only Memory Access) and NUMA (Non-Uniform Memory Access).[2]
Bus-based
MIMD machines with shared memory have processors which share a common, central memory. In the simplest form, all processors are attached to a bus which connects them to memory.
Hierarchical
MIMD machines with hierarchical shared memory use a hierarchy of buses to give processors access to each other's memory. Processors on different boards may communicate through inter-nodal buses. Buses support communication between boards. With this type of architecture, the machine may support over nine thousand processors.
Distributed memory
In distributed memory MIMD machines, each processor has its own individual memory location. Each processor has no direct knowledge about other processor's memory. For data to be shared, it must be passed from one processor to another as a message. Since there is no shared memory, contention is not as great a problem with these machines. It is not economically feasible to connect a large number of processors directly to each other. A way to avoid this multitude of direct connections is to connect each processor to just a few others. This type of design can be inefficient because of the added time required to pass a message from one processor to another along the message path. The amount of time required for processors to perform simple message routing can be substantial. Systems were designed to reduce this time loss and hypercube and mesh are among two of the popular interconnection schemes.
As examples of distributed memory(multicomputers): MPP (massively parallel processors) and COW (Clusters of Workstations). The first one is complex and expensive: lots of super-computers coupled by broad-band networks. Examples: hypercube and mesh interconections. COW is the "home-made" version for a fraction of the price. [3]
Hypercube interconnection network
In an MIMD distributed memory machine with a hypercube system interconnection network containing four processors, a processor and a memory module are placed at each vertex of a square. The diameter of the system is the minimum number of steps it takes for one processor to send a message to the processor that is the farthest away. So, for example, the diameter of a 2-cube is 1. In a hypercube system with eight processors and each processor and memory module being placed in the vertex of a cube, the diameter is 3. In general, a system that contains 2^N processors with each processor directly connected to N other processors, the diameter of the system is N. One disadvantage of a hypercube system is that it must be configured in powers of two, so a machine must be built that could potentially have many more processors than is really needed for the application.
Mesh interconnection network
In an MIMD distributed memory machine with a mesh interconnection network, processors are placed in a two-dimensional grid. Each processor is connected to its four immediate neighbors. Wraparound connections may be provided at the edges of the mesh. One advantage of the mesh interconnection network over the hypercube is that the mesh system need not be configured in powers of two. A disadvantage is that the diameter of the mesh network is greater than the hypercube for systems with more than four processors.
See also
- SMP
- NUMA
- Flynn's taxonomy
- SPMD
- Multi-core (computing)
- Superscalar
- Very long instruction word
References
- ^ a b Ibaroudene, Djaffer. "Parallel Processing, EG6370G: Chapter 1, Motivation and History." Lecture Slides. St Mary's University, San Antonio, Texas. Spring 2008.
- ^ Tanenbaum, Andrew S. Organizacion de Computadoras Un Enfoque Estructurado, pag 551
- ^ Tanenbaum, Andrew S. Organizacion de Computadoras, Un Enfoque Estructurado, pag 551
CPU technologies Architecture Parallelism PipelineLevelThreadsTypes Components Arithmetic logic unit (ALU) · Barrel shifter · Floating-point unit (FPU) · Back-side bus · Multiplexer · Demultiplexer · Registers · Memory management unit (MMU) · Translation lookaside buffer (TLB) · Cache · Register file · Microcode · Control unit · Clock ratePower management Parallel computing General 
Levels Threads Theory Elements Coordination Multiprocessing · Multithreading (computer architecture) · Memory coherency · Cache coherency · Cache invalidation · Barrier · Synchronization · Application checkpointingProgramming Models (Implicit parallelism · Explicit parallelism · Concurrency) · Flynn's taxonomy (SISD • SIMD • MISD • MIMD (SPMD)) · Thread (computer science) · Non-blocking algorithmHardware Multiprocessor (Symmetric · Asymmetric) · Memory (NUMA · COMA · distributed · shared · distributed shared) · SMT
MPP · Superscalar · Vector processor · Supercomputer · BeowulfAPIs Ateji PX · POSIX Threads · OpenMP · OpenHMPP · PVM · MPI · UPC · Intel Threading Building Blocks · Boost.Thread · Global Arrays · Charm++ · Cilk · Co-array Fortran · OpenCL · CUDA · Dryad · DryadLINQProblems Embarrassingly parallel · Grand Challenge · Software lockout · Scalability · Race conditions · Deadlock · Livelock · Deterministic algorithm · Parallel slowdown
Categories:- Computing acronyms
- Flynn's Taxonomy
- Parallel computing
- Classes of computers


Wikimedia Foundation. 2010.