- Non-Uniform Memory Access
-
Non-Uniform Memory Access (NUMA) is a computer memory design used in Multiprocessing, where the memory access time depends on the memory location relative to a processor. Under NUMA, a processor can access its own local memory faster than non-local memory, that is, memory local to another processor or memory shared between processors.
NUMA architectures logically follow in scaling from symmetric multiprocessing (SMP) architectures. Their commercial development came in work by Burroughs (later Unisys), Convex Computer (later Hewlett-Packard), Silicon Graphics (later Silicon Graphics International), Sequent Computer Systems (later IBM), Data General (later EMC) and Digital (later Compaq, now HP) during the 1990s. Techniques developed by these companies later featured in a variety of Unix-like operating systems, and somewhat in Windows NT.
Contents
Basic concept
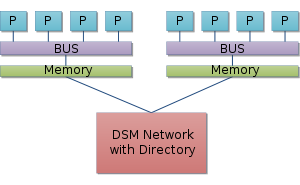 One possible architecture of a NUMA system. Notice that the processors are connected to the bus or crossbar by connections of varying thickness/number. This shows that different CPUs have different priorities to memory access based on their location.
One possible architecture of a NUMA system. Notice that the processors are connected to the bus or crossbar by connections of varying thickness/number. This shows that different CPUs have different priorities to memory access based on their location.
Modern CPUs operate considerably faster than the main memory to which they are attached. In the early days of computing and data processing the CPU generally ran slower than its memory. The performance lines crossed in the 1960s with the advent of the first supercomputers and high-speed computing. Since then, CPUs, increasingly "starved for data", have had to stall while they wait for memory accesses to complete. Many supercomputer designs of the 1980s and 90s focused on providing high-speed memory access as opposed to faster processors, allowing them to work on large data sets at speeds other systems could not approach.
Limiting the number of memory accesses provided the key to extracting high performance from a modern computer. For commodity processors, this means installing an ever-increasing amount of high-speed cache memory and using increasingly sophisticated algorithms to avoid "cache misses". But the dramatic increase in size of the operating systems and of the applications run on them has generally overwhelmed these cache-processing improvements. Multi-processor systems make the problem considerably worse. Now a system can starve several processors at the same time, notably because only one processor can access memory at a time.
NUMA attempts to address this problem by providing separate memory for each processor, avoiding the performance hit when several processors attempt to address the same memory. For problems involving spread data (common for servers and similar applications), NUMA can improve the performance over a single shared memory by a factor of roughly the number of processors (or separate memory banks).
Of course, not all data ends up confined to a single task, which means that more than one processor may require the same data. To handle these cases, NUMA systems include additional hardware or software to move data between banks. This operation has the effect of slowing down the processors attached to those banks, so the overall speed increase due to NUMA will depend heavily on the exact nature of the tasks run on the system at any given time.
Cache coherent NUMA (ccNUMA)
Nearly all CPU architectures use a small amount of very fast non-shared memory known as cache to exploit locality of reference in memory accesses. With NUMA, maintaining cache coherence across shared memory has a significant overhead.
Although simpler to design and build, non-cache-coherent NUMA systems become prohibitively complex to program in the standard von Neumann architecture programming model. As a result, all NUMA computers sold to the market use special-purpose hardware to maintain cache coherence[citation needed], and thus class as "cache-coherent NUMA", or ccNUMA.
Typically, this takes place by using inter-processor communication between cache controllers to keep a consistent memory image when more than one cache stores the same memory location. For this reason, ccNUMA may perform poorly when multiple processors attempt to access the same memory area in rapid succession. Operating-system support for NUMA attempts to reduce the frequency of this kind of access by allocating processors and memory in NUMA-friendly ways and by avoiding scheduling and locking algorithms that make NUMA-unfriendly accesses necessary. Alternatively, cache coherency protocols such as the MESIF protocol attempt to reduce the communication required to maintain cache coherency. Scalable Coherent Interface (SCI) is an IEEE standard defining a directory based cache coherency protocol to avoid scalability limitations found in earlier multiprocessor systems. SCI is used as basis for the Numascale NumaConnect technology.
Current[when?] ccNUMA systems are multiprocessor systems based on the AMD Opteron, which can be implemented without external logic, and Intel Itanium, which requires the chipset to support NUMA. Examples of ccNUMA enabled chipsets are the SGI Shub (Super hub), the Intel E8870, the HP sx2000 (used in the Integrity and Superdome servers), and those found in recent NEC Itanium-based systems. Earlier ccNUMA systems such as those from Silicon Graphics were based on MIPS processors and the DEC Alpha 21364 (EV7) processor.
Intel announced NUMA[clarification needed] introduction to its x86 and Itanium servers in late 2007 with Nehalem and Tukwila CPUs.[1] Both CPU families will share a common chipset; the interconnection is called Intel Quick Path Interconnect (QPI).[2]
NUMA vs. cluster computing
One can view NUMA as a very tightly coupled form of cluster computing. The addition of virtual memory paging to a cluster architecture can allow the implementation of NUMA entirely in software where no NUMA hardware exists. However, the inter-node latency of software-based NUMA remains several orders of magnitude greater than that of hardware-based NUMA.
See also
- Uniform Memory Access (UMA)
- Cluster computing
- Symmetric multiprocessing (SMP)
- Cache only memory architecture (COMA)
- Scratchpad RAM (SPM)
- Supercomputer
- Silicon Graphics, SGI
- HiperDispatch
- Intel QuickPath Interconnect (QPI)
References
This article was originally based on material from the Free On-line Dictionary of Computing, which is licensed under the GFDL.
- ^ Intel Corp. (2008). Intel QuickPath Architecture [White paper]. Retrieved from http://www.intel.com/pressroom/archive/reference/whitepaper_QuickPath.pdf
- ^ Intel Corporation. (September 18th, 2007). Gelsinger Speaks To Intel And High-Tech Industry's Rapid Technology Caden[Press release]. Retrieved from http://www.intel.com/pressroom/archive/releases/2007/20070918corp_b.htm
External links
- NUMA FAQ
- Page-based distributed shared memory
- OpenSolaris NUMA Project
- Introduction video for the Alpha EV7 system architecture
- More videos related to EV7 systems: CPU, IO, etc
- NUMA optimization in Windows Applications
- NUMA Support in Linux at SGI
- Intel Tukwila
- Intel QPI (CSI) explained
- current Itanium NUMA systems
Parallel computing General 
Levels Threads Theory Elements Coordination Multiprocessing · Multithreading (computer architecture) · Memory coherency · Cache coherency · Cache invalidation · Barrier · Synchronization · Application checkpointingProgramming Hardware Multiprocessor (Symmetric · Asymmetric) · Memory (NUMA · COMA · distributed · shared · distributed shared) · SMT
MPP · Superscalar · Vector processor · Supercomputer · BeowulfAPIs Ateji PX · POSIX Threads · OpenMP · OpenHMPP · PVM · MPI · UPC · Intel Threading Building Blocks · Boost.Thread · Global Arrays · Charm++ · Cilk · Co-array Fortran · OpenCL · CUDA · Dryad · DryadLINQProblems Embarrassingly parallel · Grand Challenge · Software lockout · Scalability · Race conditions · Deadlock · Livelock · Deterministic algorithm · Parallel slowdown
Categories:


Wikimedia Foundation. 2010.