- Thread (computer science)
-
This article is about the concurrency concept. For the multithreading in hardware, see Multithreading (computer architecture). For the form of code consisting entirely of subroutine calls, see Threaded code. For other uses, see Thread (disambiguation).
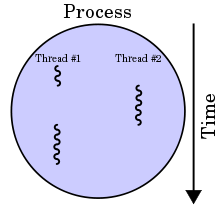 A process with two threads of execution on a single processor.
A process with two threads of execution on a single processor.
In computer science, a thread of execution is the smallest unit of processing that can be scheduled by an operating system. The implementation of threads and processes differs from one operating system to another, but in most cases, a thread is contained inside a process. Multiple threads can exist within the same process and share resources such as memory, while different processes do not share these resources. In particular, the threads of a process share the latter's instructions (its code) and its context (the values that its variables reference at any given moment). To give an analogy, multiple threads in a process are like multiple cooks reading off the same cook book and following its instructions, not necessarily from the same page.
On a single processor, multithreading generally occurs by time-division multiplexing (as in multitasking): the processor switches between different threads. This context switching generally happens frequently enough that the user perceives the threads or tasks as running at the same time. On a multiprocessor or multi-core system, the threads or tasks will actually run at the same time, with each processor or core running a particular thread or task.
Many modern operating systems directly support both time-sliced and multiprocessor threading with a process scheduler. The kernel of an operating system allows programmers to manipulate threads via the system call interface. Some implementations are called a kernel thread, whereas a lightweight process (LWP) is a specific type of kernel thread that shares the same state and information.
Programs can have user-space threads when threading with timers, signals, or other methods to interrupt their own execution, performing a sort of ad-hoc time-slicing.
Contents
How threads differ from processes
Threads differ from traditional multitasking operating system processes in that:
- processes are typically independent, while threads exist as subsets of a process
- processes carry considerably more state information than threads, whereas multiple threads within a process share process state as well as memory and other resources
- processes have separate address spaces, whereas threads share their address space
- processes interact only through system-provided inter-process communication mechanisms
- Context switching between threads in the same process is typically faster than context switching between processes.
Systems like Windows NT and OS/2 are said to have "cheap" threads and "expensive" processes; in other operating systems there is not so great a difference except the cost of address space switch which implies a TLB flush.
Multithreading
Multithreading as a widespread programming and execution model allows multiple threads to exist within the context of a single process. These threads share the process' resources but are able to execute independently. The threaded programming model provides developers with a useful abstraction of concurrent execution. However, perhaps the most interesting application of the technology is when it is applied to a single process to enable parallel execution on a multiprocessor system.
This advantage of a multithreaded program allows it to operate faster on computer systems that have multiple CPUs, CPUs with multiple cores, or across a cluster of machines — because the threads of the program naturally lend themselves to truly concurrent execution. In such a case, the programmer needs to be careful to avoid race conditions, and other non-intuitive behaviors. In order for data to be correctly manipulated, threads will often need to rendezvous in time in order to process the data in the correct order. Threads may also require mutually-exclusive operations (often implemented using semaphores) in order to prevent common data from being simultaneously modified, or read while in the process of being modified. Careless use of such primitives can lead to deadlocks.
Another use of multithreading, applicable even for single-CPU systems, is the ability for an application to remain responsive to input. In a single-threaded program, if the main execution thread blocks on a long-running task, the entire application can appear to freeze. By moving such long-running tasks to a worker thread that runs concurrently with the main execution thread, it is possible for the application to remain responsive to user input while executing tasks in the background. On the other hand, in most cases multithreading is not the only way to keep program responsive, with non-blocking I/O and/or Unix signals being used to achieve the same result.[1]
Operating systems schedule threads in one of two ways:
- Preemptive multithreading is generally considered the superior approach, as it allows the operating system to determine when a context switch should occur. The disadvantage to preemptive multithreading is that the system may make a context switch at an inappropriate time, causing lock convoy, priority inversion or other negative effects which may be avoided by cooperative multithreading.
- Cooperative multithreading, on the other hand, relies on the threads themselves to relinquish control once they are at a stopping point. This can create problems if a thread is waiting for a resource to become available.
Until late 1990s, CPUs in desktop computers did not have much support for multithreading, because switching between threads was generally already quicker than full process context switches. Processors in embedded systems, which have higher requirements for real-time behaviors, might support multithreading by decreasing the thread-switch time, perhaps by allocating a dedicated register file for each thread instead of saving/restoring a common register file. In the late 1990s, the idea of executing instructions from multiple threads simultaneously, known as simultaneous multithreading, has reached desktops with Intel's Pentium 4 processor, under the name hyper threading. It has been dropped from Intel Core and Core 2 architectures, but later was re-instated in Core i7 architecture.
Critics of multithreading contend that increasing the use of threads has significant drawbacks:
"Although threads seem to be a small step from sequential computation, in fact, they represent a huge step. They discard the most essential and appealing properties of sequential computation: understandability, predictability, and determinism. Threads, as a model of computation, are wildly nondeterministic, and the job of the programmer becomes one of pruning that nondeterminism." -- 'The Problem with Threads, Edward A. Lee, UC Berkeley, 2006[2]
Processes, kernel threads, user threads, and fibers
Main articles: Process (computing) and Fiber (computer science)A process is the "heaviest" unit of kernel scheduling. Processes own resources allocated by the operating system. Resources include memory, file handles, sockets, device handles, and windows. Processes do not share address spaces or file resources except through explicit methods such as inheriting file handles or shared memory segments, or mapping the same file in a shared way. Processes are typically preemptively multitasked.
A kernel thread is the "lightest" unit of kernel scheduling. At least one kernel thread exists within each process. If multiple kernel threads can exist within a process, then they share the same memory and file resources. Kernel threads are preemptively multitasked if the operating system's process scheduler is preemptive. Kernel threads do not own resources except for a stack, a copy of the registers including the program counter, and thread-local storage (if any). The kernel can assign one thread to each logical core in a system (because each processor splits itself up into multiple logical cores if it supports multithreading, or only support one logical core per physical core if it does not support multithreading), and can swap out threads that get blocked. However, kernel threads take much longer than user threads to be swapped.
Threads are sometimes implemented in userspace libraries, thus called user threads. The kernel is not aware of them, so they are managed and scheduled in userspace. Some implementations base their user threads on top of several kernel threads to benefit from multi-processor machines (M:N model). In this article the term "thread" (without kernel or user qualifier) defaults to referring to kernel threads. User threads as implemented by virtual machines are also called green threads. User threads are generally fast to create and manage, but cannot take advantage of multithreading or multiprocessing and get blocked if all of their associated kernel threads get blocked even if there are some user threads that are ready to run.
Fibers are an even lighter unit of scheduling which are cooperatively scheduled: a running fiber must explicitly "yield" to allow another fiber to run, which makes their implementation much easier than kernel or user threads. A fiber can be scheduled to run in any thread in the same process. This permits applications to gain performance improvements by managing scheduling themselves, instead of relying on the kernel scheduler (which may not be tuned for the application). Parallel programming environments such as OpenMP typically implement their tasks through fibers.
Thread and fiber issues
Concurrency and data structures
Threads in the same process share the same address space. This allows concurrently-running code to couple tightly and conveniently exchange data without the overhead or complexity of an IPC. When shared between threads, however, even simple data structures become prone to race hazards if they require more than one CPU instruction to update: two threads may end up attempting to update the data structure at the same time and find it unexpectedly changing underfoot. Bugs caused by race hazards can be very difficult to reproduce and isolate.
To prevent this, threading APIs offer synchronization primitives such as mutexes to lock data structures against concurrent access. On uniprocessor systems, a thread running into a locked mutex must sleep and hence trigger a context switch. On multi-processor systems, the thread may instead poll the mutex in a spinlock. Both of these may sap performance and force processors in SMP systems to contend for the memory bus, especially if the granularity of the locking is fine.
I/O and scheduling
User thread or fiber implementations are typically entirely in userspace. As a result, context switching between user threads or fibers within the same process is extremely efficient because it does not require any interaction with the kernel at all: a context switch can be performed by locally saving the CPU registers used by the currently executing user thread or fiber and then loading the registers required by the user thread or fiber to be executed. Since scheduling occurs in userspace, the scheduling policy can be more easily tailored to the requirements of the program's workload.
However, the use of blocking system calls in user threads (as opposed to kernel threads) or fibers can be problematic. If a user thread or a fiber performs a system call that blocks, the other user threads and fibers in the process are unable to run until the system call returns. A typical example of this problem is when performing I/O: most programs are written to perform I/O synchronously. When an I/O operation is initiated, a system call is made, and does not return until the I/O operation has been completed. In the intervening period, the entire process is "blocked" by the kernel and cannot run, which starves other user threads and fibers in the same process from executing.
A common solution to this problem is providing an I/O API that implements a synchronous interface by using non-blocking I/O internally, and scheduling another user thread or fiber while the I/O operation is in progress. Similar solutions can be provided for other blocking system calls. Alternatively, the program can be written to avoid the use of synchronous I/O or other blocking system calls.
SunOS 4.x implemented "light-weight processes" or LWPs. NetBSD 2.x+, and DragonFly BSD implement LWPs as kernel threads (1:1 model). SunOS 5.2 through SunOS 5.8 as well as NetBSD 2 to NetBSD 4 implemented a two level model, multiplexing one or more user level threads on each kernel thread (M:N model). SunOS 5.9 and later, as well as NetBSD 5 eliminated user threads support, returning to a 1:1 model. [1] FreeBSD 5 implemented M:N model. FreeBSD 6 supported both 1:1 and M:N, user could choose which one should be used with a given program using /etc/libmap.conf. Starting with FreeBSD 7, the 1:1 became the default. FreeBSD 8 no longer supports the M:N model.
The use of kernel threads simplifies user code by moving some of the most complex aspects of threading into the kernel. The program doesn't need to schedule threads or explicitly yield the processor. User code can be written in a familiar procedural style, including calls to blocking APIs, without starving other threads. However, kernel threading may force a context switch between threads at any time, and thus expose race hazards and concurrency bugs that would otherwise lie latent. On SMP systems, this is further exacerbated because kernel threads may literally execute concurrently on separate processors.
Models
1:1 (Kernel-level threading)
Threads created by the user are in 1-1 correspondence with schedulable entities in the kernel. This is the simplest possible threading implementation. Win32 used this approach from the start. On Linux, the usual C library implements this approach (via the NPTL or older LinuxThreads). The same approach is used by Solaris, NetBSD and FreeBSD.
N:1 (User-level threading)
An N:1 model implies that all application-level threads map to a single kernel-level scheduled entity; the kernel has no knowledge of the application threads. With this approach, context switching can be done very quickly and, in addition, it can be implemented even on simple kernels which do not support threading. One of the major drawbacks however is that it cannot benefit from the hardware acceleration on multi-threaded processors or multi-processor computers: there is never more than one thread being scheduled at the same time. It is used by GNU Portable Threads.
M:N (Hybrid threading)
M:N maps some N number of application threads onto some M number of kernel entities, or "virtual processors." This is a compromise between kernel-level ("1:1") and user-level ("N:1") threading. In general, "M:N" threading systems are more complex to implement than either kernel or user threads, because changes to both kernel and user-space code are required. In the M:N implementation, the threading library is responsible for scheduling user threads on the available schedulable entities; this makes context switching of threads very fast, as it avoids system calls. However, this increases complexity and the likelihood of priority inversion, as well as suboptimal scheduling without extensive (and expensive) coordination between the userland scheduler and the kernel scheduler.
Implementations
There are many different and incompatible implementations of threading. These include both kernel-level and user-level implementations. However, they often follow more or less closely the POSIX Threads interface.
Kernel-level implementation examples
- Light Weight Kernel Threads (LWKT) in various BSDs
- M:N threading
- Native POSIX Thread Library (NPTL) for Linux, an implementation of the POSIX Threads (pthreads) standard
- Apple Multiprocessing Services version 2.0 and later, uses the built-in nanokernel in Mac OS 8.6 and later which was modified to support it.
- Microsoft Windows from Windows 95 and Windows NT onwards.
User-level implementation examples
- GNU Portable Threads
- FSU Pthreads
- Apple Inc.'s Thread Manager
- REALbasic (includes an API for cooperative threading)
- Netscape Portable Runtime (includes a user-space fibers implementation)
Hybrid implementation examples
- Scheduler activations used by the NetBSD native POSIX threads library implementation (an M:N model as opposed to a 1:1 kernel or userspace implementation model)
- Marcel from the PM2 project.
- The OS for the Tera/Cray MTA
- Microsoft Windows 7
Fiber implementation examples
Fibers can be implemented without operating system support, although some operating systems or libraries provide explicit support for them.
- Win32 supplies a fiber API[3] (Windows NT 3.51 SP3 and later)
- Ruby as Green threads
Programming Language Support
Many programming languages support threading in some capacity. Many implementations of C and C++ do not provide direct support for threading on their own, but provide access to the native threading APIs provided by the operating system. Some higher level (and usually cross platform) programming languages such as Java, Python, and .NET, expose threading to the developer while abstracting the platform specific differences in threading implementations in the runtime to the developer. A number of other programming languages also try to abstract the concept of concurrency and threading from the developer altogether (Cilk, OpenMP, MPI). Some languages are designed to parallelism (Ateji PX, CUDA).
A few interpreted programming languages such as Ruby and (the CPython implementation of) Python support threading, but have a limitation that is known as a Global Interpreter Lock (GIL). The GIL is a mutual exclusion lock held by the interpreter that can prevent the interpreter from concurrently interpreting the applications code on two or more threads at the same time, which effectively limits the concurrency on multiple core systems (mostly for processor-bound threads, and not much for network-bound ones).
Event-driven programming hardware description languages like Verilog have a different threading model which supports extremely large numbers of threads (for modeling hardware).
See also
- Win32 Thread Information Block
- Hardware: Multithreading (computer hardware), Multi-core (computing), Simultaneous multithreading
- Theory: Communicating sequential processes, Computer multitasking, Message passing
- Problems: Thread safety, Priority inversion
- Techniques: Protothreads, Thread pool pattern, Lock-free and wait-free algorithms
- System Calls: clone (Linux system call)
References
- ^ Single-Threading: Back to the Future? Sergey Ignatchenko, Overload #97
- ^ http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-1.pdf The Problem with Threads, Edward A. Lee, UC Berkeley, 2006
- ^ CreateFiber, MSDN
- David R. Butenhof: Programming with POSIX Threads, Addison-Wesley, ISBN 0-201-63392-2
- Bradford Nichols, Dick Buttlar, Jacqueline Proulx Farell: Pthreads Programming, O'Reilly & Associates, ISBN 1-56592-115-1
- Charles J. Northrup: Programming with UNIX Threads, John Wiley & Sons, ISBN 0-471-13751-0
- Mark Walmsley: Multi-Threaded Programming in C++, Springer, ISBN 1-85233-146-1
- Paul Hyde: Java Thread Programming, Sams, ISBN 0-672-31585-8
- Bill Lewis: Threads Primer: A Guide to Multithreaded Programming, Prentice Hall, ISBN 0-13-443698-9
- Steve Kleiman, Devang Shah, Bart Smaalders: Programming With Threads, SunSoft Press, ISBN 0-13-172389-8
- Pat Villani: Advanced WIN32 Programming: Files, Threads, and Process Synchronization, Harpercollins Publishers, ISBN 0-87930-563-0
- Jim Beveridge, Robert Wiener: Multithreading Applications in Win32, Addison-Wesley, ISBN 0-201-44234-5
- Thuan Q. Pham, Pankaj K. Garg: Multithreaded Programming with Windows NT, Prentice Hall, ISBN 0-13-120643-5
- Len Dorfman, Marc J. Neuberger: Effective Multithreading in OS/2, McGraw-Hill Osborne Media, ISBN 0-07-017841-0
- Alan Burns, Andy Wellings: Concurrency in ADA, Cambridge University Press, ISBN 0-521-62911-X
- Uresh Vahalia: Unix Internals: the New Frontiers, Prentice Hall, ISBN 0-13-101908-2
- Alan L. Dennis: .Net Multithreading , Manning Publications Company, ISBN 1-930110-54-5
- Tobin Titus, Fabio Claudio Ferracchiati, Srinivasa Sivakumar, Tejaswi Redkar, Sandra Gopikrishna: C# Threading Handbook, Peer Information Inc, ISBN 1-86100-829-5
- Tobin Titus, Fabio Claudio Ferracchiati, Srinivasa Sivakumar, Tejaswi Redkar, Sandra Gopikrishna: Visual Basic .Net Threading Handbook, Wrox Press Inc, ISBN 1-86100-713-2
External links
- Answers to frequently asked questions for comp.programming.threads
- What makes multi-threaded programming hard?
- Article "Query by Slice, Parallel Execute, and Join: A Thread Pool Pattern in Java" by Binildas C. A.
- Article "The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software" by Herb Sutter
- Article "The Problem with Threads" by Edward Lee
- Concepts of Multithreading
- ConTest - A Tool for Testing Multithreaded Java Applications by IBM
- Debugging and Optimizing Multithreaded OpenMP Programs
- Multithreading at the Open Directory Project
- Multithreading in the Solaris Operating Environment
- Parallel computing community
- POSIX threads explained by Daniel Robbins
- The C10K problem
Categories:- Operating system technology
- Concurrent computing
- Threads


Wikimedia Foundation. 2010.