- CUDA
-
CUDA Developer(s) Nvidia Corporation Stable release 4.0 / May 17 2011 Operating system Windows XP and later
Mac OS X
LinuxPlatform See Supported GPUs Type GPGPU License Freeware Website nvidia.com/object/cuda home new.html CUDA or Compute Unified Device Architecture[1] is a parallel computing architecture developed by Nvidia. CUDA is the computing engine in Nvidia graphics processing units (GPUs) that is accessible to software developers through variants of industry standard programming languages. Programmers use 'C for CUDA' (C with Nvidia extensions and certain restrictions), compiled through a PathScale Open64 C compiler,[2] to code algorithms for execution on the GPU. CUDA architecture shares a range of computational interfaces with two competitors -the Khronos Group's OpenCL[3] and Microsoft's DirectCompute.[4] Third party wrappers are also available for Python, Perl, Fortran, Java, Ruby, Lua, MATLAB, and IDL, and native support exists in Mathematica.
CUDA gives developers access to the virtual instruction set and memory of the parallel computational elements in CUDA GPUs. Using CUDA, the latest Nvidia GPUs become accessible for computation like CPUs. Unlike CPUs however, GPUs have a parallel throughput architecture that emphasizes executing many concurrent threads slowly, rather than executing a single thread very quickly. This approach of solving general purpose problems on GPUs is known as GPGPU.
In the computer game industry, in addition to graphics rendering, GPUs are used in game physics calculations (physical effects like debris, smoke, fire, fluids); examples include PhysX and Bullet. CUDA has also been used to accelerate non-graphical applications in computational biology, cryptography and other fields by an order of magnitude or more.[5][6][7][8] An example of this is the BOINC distributed computing client.[9]
CUDA provides both a low level API and a higher level API. The initial CUDA SDK was made public on 15 February 2007, for Microsoft Windows and Linux. Mac OS X support was later added in version 2.0,[10] which supersedes the beta released February 14, 2008.[11] CUDA works with all Nvidia GPUs from the G8x series onwards, including GeForce, Quadro and the Tesla line. CUDA is compatible with most standard operating systems. Nvidia states that programs developed for the G8x series will also work without modification on all future Nvidia video cards, due to binary compatibility.
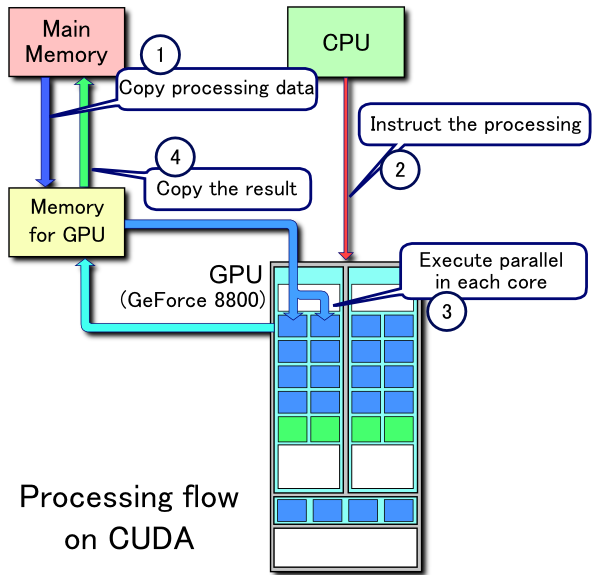
 Example of CUDA processing flow
Example of CUDA processing flow
1. Copy data from main mem to GPU mem
2. CPU instructs the process to GPU
3. GPU execute parallel in each core
4. Copy the result from GPU mem to main memContents
Background
See also: GPUThe GPU, as a specialized processor, addresses the demands of real-time high-resolution 3D graphics compute-intensive tasks. As of 2011[update] GPUs have evolved into highly parallel multi core systems allowing very efficient manipulation of large blocks of data. This design is more effective than general-purpose CPUs for algorithms where processing of large blocks of data is done in parallel, such as:
- push-relabel maximum flow algorithm
- fast sort algorithms of large lists
- two-dimensional fast wavelet transform
For instance, the parallel nature of molecular dynamics simulations is suitable for CUDA implementation.[12]
Advantages
CUDA has several advantages over traditional general-purpose computation on GPUs (GPGPU) using graphics APIs:
- Scattered reads – code can read from arbitrary addresses in memory
- Shared memory – CUDA exposes a fast shared memory region (up to 48KB per Multi-Processor) that can be shared amongst threads. This can be used as a user-managed cache, enabling higher bandwidth than is possible using texture lookups.[13]
- Faster downloads and readbacks to and from the GPU
- Full support for integer and bitwise operations, including integer texture lookups
Limitations
- Texture rendering is not supported (CUDA 3.2 and up addresses this by introducing "surface writes" to cuda Arrays, the underlying opaque data structure).
- Copying between host and device memory may incur a performance hit due to system bus bandwidth and latency (this can be partly alleviated with asynchronous memory transfers, handled by the GPU's DMA engine)
- Threads should be running in groups of at least 32 for best performance, with total number of threads numbering in the thousands. Branches in the program code do not impact performance significantly, provided that each of 32 threads takes the same execution path; the SIMD execution model becomes a significant limitation for any inherently divergent task (e.g. traversing a space partitioning data structure during ray tracing).
- Unlike OpenCL, CUDA-enabled GPUs are only available from Nvidia[14]
- Valid C/C++ may sometimes be flagged and prevent compilation due to optimization techniques the compiler is required to employ to use limited resources.
- CUDA (with compute capability 1.x) uses a recursion-free, function-pointer-free subset of the C language, plus some simple extensions. However, a single process must run spread across multiple disjoint memory spaces, unlike other C language runtime environments.
- CUDA (with compute capability 2.x) allows a subset of C++ class functionality, for example member functions may not be virtual (this restriction will be removed in some future release). [See CUDA C Programming Guide 3.1 - Appendix D.6]
- Double precision (CUDA compute capability 1.3 and above[15]) deviate from the IEEE 754 standard: round-to-nearest-even is the only supported rounding mode for reciprocal, division, and square root. In single precision, denormals and signalling NaNs are not supported; only two IEEE rounding modes are supported (chop and round-to-nearest even), and those are specified on a per-instruction basis rather than in a control word; and the precision of division/square root is slightly lower than single precision.
Supported GPUs
Compute capability table (version of CUDA supported) by GPU and card. Also available directly from Nvidia
Compute
capability
(version)GPUs Cards 1.0 G80, G92, G92b, G94, G94b GeForce 8800GTX/Ultra, 9400GT, 9600GT, 9800GT, Tesla C/D/S870, FX4/5600, 360M, GT 420 1.1 G86, G84, G98, G96, G96b, G94, G94b, G92, G92b GeForce 8400GS/GT, 8600GT/GTS, 8800GT/GTS, 9600 GSO, 9800GTX/GX2, GTS 250, GT 120/30/40, FX 4/570, 3/580, 17/18/3700, 4700x2, 1xxM, 32/370M, 3/5/770M, 16/17/27/28/36/37/3800M, NVS420/50 1.2 GT218, GT216, GT215 GeForce 210, GT 220/40, FX380 LP, 1800M, 370/380M, NVS 2/3100M 1.3 GT200, GT200b GeForce GTX 260, GTX 275, GTX 280, GTX 285, GTX 295, Tesla C/M1060, S1070, Quadro CX, FX 3/4/5800 2.0 GF100, GF110 GeForce (GF100) GTX 465, GTX 470, GTX 480, Tesla C2050, C2070, S/M2050/70, Quadro Plex 7000, GeForce (GF110) GTX570, GTX580, GTX590 2.1 GF104, GF114, GF116, GF108, GF106 GeForce GT 430, GT 440, GTS 450, GTX 460, GTX 550 Ti, GTX 560, GTX 560 Ti, 500M, Quadro 600, 2000, 4000, 5000, 6000 A table of devices officially supporting CUDA (Note that many applications require at least 256 MB of dedicated VRAM, and some recommend at least 96 cuda cores).[14]
see full list here: http://developer.nvidia.com/cuda-gpus
Nvidia GeForce GeForce GTX 590 GeForce GTX 580 GeForce GTX 570 GeForce GTX 560 Ti GeForce GTX 560 GeForce GTX 550 Ti GeForce GTX 480 GeForce GTX 470 GeForce GTX 465 GeForce GTX 460 GeForce GTX 460 SE GeForce GTS 450 GeForce GT 440 GeForce GT 430 GeForce GT 420 GeForce GTX 295 GeForce GTX 285 GeForce GTX 280 GeForce GTX 275 GeForce GTX 260 GeForce GTS 250 GeForce GTS 240 GeForce GT 240 GeForce GT 220 GeForce 210/G210 GeForce GT 140 GeForce 9800 GX2 GeForce 9800 GTX+ GeForce 9800 GTX GeForce 9800 GT GeForce 9600 GSO GeForce 9600 GT GeForce 9500 GT GeForce 9400 GT GeForce 9400 mGPU GeForce 9300 mGPU GeForce 9100 mGPU GeForce 8800 Ultra GeForce 8800 GTX GeForce 8800 GTS GeForce 8800 GT GeForce 8800 GS GeForce 8600 GTS GeForce 8600 GT GeForce 8600 mGT GeForce 8500 GT GeForce 8400 GS GeForce 8300 mGPU GeForce 8200 mGPU GeForce 8100 mGPU Nvidia GeForce Mobile GeForce GTX 580M GeForce GTX 570M GeForce GTX 560M GeForce GT 555M GeForce GT 550M GeForce GT 540M GeForce GT 525M GeForce GT 520M GeForce GTX 480M GeForce GTX 470M GeForce GTX 460M GeForce GT 445M GeForce GT 435M GeForce GT 425M GeForce GT 420M GeForce GT 415M GeForce GTX 285M GeForce GTX 280M GeForce GTX 260M GeForce GTS 360M GeForce GTS 350M GeForce GTS 260M GeForce GTS 250M GeForce GT 335M GeForce GT 330M GeForce GT 325M GeForce GT 320M GeForce 310M GeForce GT 240M GeForce GT 230M GeForce GT 220M GeForce G210M GeForce GTS 160M GeForce GTS 150M GeForce GT 130M GeForce GT 120M GeForce G110M GeForce G105M GeForce G103M GeForce G102M GeForce G100 GeForce 9800M GTX GeForce 9800M GTS GeForce 9800M GT GeForce 9800M GS GeForce 9700M GTS GeForce 9700M GT GeForce 9650M GT GeForce 9650M GS GeForce 9600M GT GeForce 9600M GS GeForce 9500M GS GeForce 9500M G GeForce 9400M G GeForce 9300M GS GeForce 9300M G GeForce 9200M GS GeForce 9100M G GeForce 8800M GTX GeForce 8800M GTS GeForce 8700M GT GeForce 8600M GT GeForce 8600M GS GeForce 8400M GT GeForce 8400M GS GeForce 8400M G GeForce 8200M G Nvidia Quadro Quadro 6000 Quadro 5000 Quadro 4000 Quadro 2000 Quadro 600 Quadro FX 5800 Quadro FX 5600 Quadro FX 4800 Quadro FX 4700 X2 Quadro FX 4600 Quadro FX 3800 Quadro FX 3700 Quadro FX 1800 Quadro FX 1700 Quadro FX 580 Quadro FX 570 Quadro FX 380 Quadro FX 370 Quadro NVS 450 Quadro NVS 420 Quadro NVS 295 Quadro NVS 290 Quadro Plex 1000 Model IV Quadro Plex 1000 Model S4 Nvidia Quadro Mobile Quadro 5010M Quadro 5000M Quadro 4000M Quadro 3000M Quadro 2000M Quadro 1000M Quadro FX 3800M Quadro FX 3700M Quadro FX 3600M Quadro FX 2800M Quadro FX 2700M Quadro FX 1800M Quadro FX 1700M Quadro FX 1600M Quadro FX 880M Quadro FX 770M Quadro FX 570M Quadro FX 380M Quadro FX 370M Quadro FX 360M Quadro NVS 320M Quadro NVS 160M Quadro NVS 150M Quadro NVS 140M Quadro NVS 135M Quadro NVS 130M Nvidia Tesla Tesla C2050/2070 Tesla M2050/M2070 Tesla S2050 Tesla S1070 Tesla M1060 Tesla C1060 Tesla C870 Tesla D870 Tesla S870 Version features and specifications
Feature support (unlisted features are
supported for all compute capabilities)Compute capability (version) 1.0 1.1 1.2 1.3 2.x Integer atomic functions operating on
32-bit words in global memoryNo Yes atomicExch() operating on 32-bit
floating point values in global memoryInteger atomic functions operating on
32-bit words in shared memoryNo Yes atomicExch() operating on 32-bit
floating point values in shared memoryInteger atomic functions operating on
64-bit words in global memoryWarp vote functions Double-precision floating-point operations No Yes Atomic functions operating on 64-bit
integer values in shared memoryNo Yes Floating-point atomic addition operating on
32-bit words in global and shared memory_ballot() _threadfence_system() _syncthreads_count(),
_syncthreads_and(),
_syncthreads_or()Surface functions 3D grid of thread block Technical specifications Compute capability (version) 1.0 1.1 1.2 1.3 2.x Maximum dimensionality of grid of thread blocks 2 3 Maximum x-, y-, or z-dimension of a grid of thread blocks 65535 Maximum dimensionality of thread block 3 Maximum x- or y-dimension of a block 512 1024 Maximum z-dimension of a block 64 Maximum number of threads per block 512 1024 Warp size 32 Maximum number of resident blocks per multiprocessor 8 Maximum number of resident warps per multiprocessor 24 32 48 Maximum number of resident threads per multiprocessor 768 1024 1536 Number of 32-bit registers per multiprocessor 8 K 16 K 32 K Maximum amount of shared memory per multiprocessor 16 KB 48 KB Number of shared memory banks 16 32 Amount of local memory per thread 16 KB 512 KB Constant memory size 64 KB Cache working set per multiprocessor for constant memory 8 KB Cache working set per multiprocessor for texture memory Device dependent, between 6 KB and 8 KB Maximum width for 1D texture
reference bound to a CUDA array8192 32768 Maximum width for 1D texture
reference bound to linear memory227 Maximum width and number of layers
for a 1D layered texture reference8192 x 512 16384 x 2048 Maximum width and height for 2D
texture reference bound to
linear memory or a CUDA array65536 x 32768 65536 x 65535 Maximum width, height, and number
of layers for a 2D layered texture reference8192 x 8192 x 512 16384 x 16384 x 2048 Maximum width, height and depth
for a 3D texture reference bound to linear
memory or a CUDA array2048 x 2048 x 2048 Maximum number of textures that
can be bound to a kernel128 Maximum width for a 1D surface
reference bound to a CUDA arrayNot
supported8192 Maximum width and height for a 2D
surface reference bound to a CUDA array8192 x 8192 Maximum number of surfaces that
can be bound to a kernel8 Maximum number of instructions per
kernel2 million Architecture specifications Compute capability (version) 1.0 1.1 1.2 1.3 2.0 2.1 Number of cores for integer and floating-point arithmetic functions operations 8[16] 32 48 Number of special function units for single-precision floating-point transcendental functions 2 4 8 Number of texture filtering units for every texture address unit or Render Output Unit (ROP) ? 4 8 Number of warp schedulers 1 2 2 Number of instructions issued at once by scheduler 1 1 2[17] For more information please visit this site: http://www.geeks3d.com/20100606/gpu-computing-nvidia-cuda-compute-capability-comparative-table/ and also read Nvidia CUDA programming guide.[18]
Example
This example code in C++ loads a texture from an image into an array on the GPU:
texture<float, 2, cudaReadModeElementType> tex; void foo() { cudaArray* cu_array; // Allocate array cudaChannelFormatDesc description = cudaCreateChannelDesc<float>(); cudaMallocArray(&cu_array, &description, width, height); // Copy image data to array cudaMemcpyToArray(cu_array, image, width*height*sizeof(float), cudaMemcpyHostToDevice); // Set texture parameters (default) tex.addressMode[0] = cudaAddressModeClamp; tex.addressMode[1] = cudaAddressModeClamp; tex.filterMode = cudaFilterModePoint; tex.normalized = false; // do not normalize coordinates // Bind the array to the texture cudaBindTextureToArray(tex, cu_array); // Run kernel dim3 blockDim(16, 16, 1); dim3 gridDim((width + blockDim.x - 1)/ blockDim.x, (height + blockDim.y - 1) / blockDim.y, 1); kernel<<< gridDim, blockDim, 0 >>>(d_data, height, width); // Unbind the array from the texture cudaUnbindTexture(tex); } //end foo() __global__ void kernel(float* odata, int height, int width) { unsigned int x = blockIdx.x*blockDim.x + threadIdx.x; unsigned int y = blockIdx.y*blockDim.y + threadIdx.y; if (x < width && y < height) { float c = tex2D(tex, x, y); odata[y*width+x] = c; } }
Below is an example given in Python that computes the product of two arrays on the GPU. The unofficial Python language bindings can be obtained from PyCUDA.
import pycuda.compiler as comp import pycuda.driver as drv import numpy import pycuda.autoinit mod = comp.SourceModule(""" __global__ void multiply_them(float *dest, float *a, float *b) { const int i = threadIdx.x; dest[i] = a[i] * b[i]; } """) multiply_them = mod.get_function("multiply_them") a = numpy.random.randn(400).astype(numpy.float32) b = numpy.random.randn(400).astype(numpy.float32) dest = numpy.zeros_like(a) multiply_them( drv.Out(dest), drv.In(a), drv.In(b), block=(400,1,1)) print dest-a*b
Additional Python bindings to simplify matrix multiplication operations can be found in the program pycublas.
import numpy from pycublas import CUBLASMatrix A = CUBLASMatrix( numpy.mat([[1,2,3],[4,5,6]],numpy.float32) ) B = CUBLASMatrix( numpy.mat([[2,3],[4,5],[6,7]],numpy.float32) ) C = A*B print C.np_mat()
Language bindings
- Fortran - FORTRAN CUDA, PGI CUDA Fortran Compiler
- Lua - KappaCUDA
- IDL - GPULib
- Mathematica - CUDALink
- MATLAB - Parallel Computing Toolbox, Distributed Computing Server,[19] and 3rd party packages like Jacket.
- .NET - CUDA.NET
- Perl - KappaCUDA, CUDA::Minimal
- Python - PyCUDA KappaCUDA
- Ruby - KappaCUDA
- Java - jCUDA, JCuda, JCublas, JCufft
- Haskell - Data.Array.Accelerate
- .NET - CUDAfy.NET .NET kernel and host code, CURAND, CUBLAS, CUFFT.
Current CUDA architectures
The current generation CUDA architecture (codename: "Fermi") which is standard on Nvidia's released (GeForce 400 Series [GF100] (GPU) 2010-03-27)[20] GPU is designed from the ground up to natively support more programming languages such as C++. It has eight times the peak double-precision floating-point performance compared to Nvidia's previous-generation Tesla GPU. It also introduced several new features[21] including:
- up to 1024 CUDA cores and 3.0 billion transistors on the GTX 590
- Nvidia Parallel DataCache technology
- Nvidia GigaThread engine
- ECC memory support
- Native support for Visual Studio
Current and future usages of CUDA architecture
- Accelerated rendering of 3D graphics
- Accelerated interconversion of video file formats
- Accelerated encryption, decryption and compression
- Distributed Calculations, such as predicting the native conformation of proteins
- Medical analysis simulations, for example virtual reality based on CT and MRI scan images.
- Physical simulations, in particular in fluid dynamics.
- Real Time Cloth Simulation OptiTex.com - Real Time Cloth Simulation
- The Search for Extra-Terrestrial Intelligence (SETI@Home) program[22][23]
See also
- GeForce 8 series
- GeForce 9 series
- GeForce 200 Series
- GeForce 400 Series
- GeForce 500 Series
- Nvidia Quadro - Nvidia's workstation graphics solution
- Nvidia Tesla - Nvidia's first dedicated general purpose GPU (graphics processing unit)
- GPGPU - general purpose computation on GPUs.
- OpenCL - The cross-platform standard supported by both NVidia and AMD/ATI
- DirectCompute - Microsoft API for GPU Computing in Windows Vista and Windows 7
- BrookGPU
- Vectorization
- Lib Sh
- Nvidia Corporation
- Graphics Processing Unit (GPU)
- Stream processing
- Shader
- Larrabee
- Molecular modeling on GPU
- AMD FireStream (ATI GPUs)
- Close to Metal
- rCUDA - An API for computing on remote computers
References
- ^ NVIDIA CUDA Programming Guide Version 1.0
- ^ NVIDIA Clears Water Muddied by Larrabee Shane McGlaun (Blog) - August 5, 2008 - DailyTech
- ^ First OpenCL demo on a GPU on YouTube
- ^ DirectCompute Ocean Demo Running on NVIDIA CUDA-enabled GPU on YouTube
- ^ Giorgos Vasiliadis, Spiros Antonatos, Michalis Polychronakis, Evangelos P. Markatos and Sotiris Ioannidis (September 2008, Boston, MA, USA). "Gnort: High Performance Network Intrusion Detection Using Graphics Processors" (PDF). Proceedings of the 11th International Symposium on Recent Advances in Intrusion Detection (RAID). http://www.ics.forth.gr/dcs/Activities/papers/gnort.raid08.pdf.
- ^ Schatz, M.C., Trapnell, C., Delcher, A.L., Varshney, A. (2007). "High-throughput sequence alignment using Graphics Processing Units". BMC Bioinformatics 8:474: 474. doi:10.1186/1471-2105-8-474. PMC 2222658. PMID 18070356. http://www.biomedcentral.com/1471-2105/8/474.
- ^ Pyrit - Google Code http://code.google.com/p/pyrit/
- ^ Use your NVIDIA GPU for scientific computing, BOINC official site (December 18, 2008)
- ^ NVIDIA CUDA Software Development Kit (CUDA SDK) - Release Notes Version 2.0 for MAC OSX
- ^ CUDA 1.1 - Now on Mac OS X- (Posted on Feb 14, 2008)
- ^ Stephen Zunes (1999). Nonviolent social movements: a geographical perspective. Wiley-Blackwell. p. 47. ISBN 9781577180760. http://books.google.com/books?id=rlIH-NQbFQgC&pg=PA47. Retrieved 10 May 2011.
- ^ Silberstein, Mark (2007). "Efficient computation of Sum-products on GPUs" (PDF). http://www.technion.ac.il/~marks/docs/SumProductPaper.pdf.
- ^ a b "CUDA-Enabled Products". CUDA Zone. Nvidia Corporation. http://www.nvidia.com/object/cuda_learn_products.html. Retrieved 2008-11-03.
- ^ CUDA and double precision floating point numbers
- ^ Cores perform only single-precision floating-point arithmetics. There is 1 double-precision floating-point unit.
- ^ The first scheduler is in charge of the warps with an odd ID and the second scheduler is in charge of the warps with an even ID.
- ^ Appendix F. Features and Technical SpecificationsPDF (3.2 MiB), Page 158 of 173 (Version 4.0 2011-05-06)
- ^ "MATLAB Adds GPGPU Support". 2010-09-20. http://www.hpcwire.com/features/MATLAB-Adds-GPGPU-Support-103307084.html.
- ^ http://www.hardware.info/nl-NL/video/wmGTacRpaA/nVidia_GeForce_GTX_480_special/ Hardware.info broadcast about Nvidia GeForce GTX 470 and 480
- ^ http://www.nvidia.com/object/fermi_architecture.html The Current Generation CUDA Architecture, Code Named Fermi
- ^ http://setiathome.berkeley.edu/cuda.php
- ^ http://setiathome.berkeley.edu/cuda_faq.php
External links
- Now code with Cuda@TechRefined Jul 02,2011
- Nvidia CUDA Official site
- Nvidia Parallel Nsight
- Nvidia CUDA developer registration for professional developers and researchers
- Nvidia CUDA GPU Computing developer forums
- CUDALink package for Mathematica
- Programming Massively Parallel Processors: A Hands-on Approach
- Intro to GPGPU computing featuring CUDA and OpenCL examples
- Integrating CUDA with GNU Autotools
- A conversation with Jen-Hsun Huang, CEO Nvidia Charlie Rose, February 5, 2009
- Scientific Publications, Videos and Software using CUDA
- How-to Guide: Running CUDA on Visual Studio 2008
- Beyond3D – Introducing CUDA Nvidia's Vision for GPU Computing March 10, 2007
- University of Illinois Nvidia CUDA Course taught by Wen-mei Hwu and David Kirk, Spring 2009
- University of Wisconsin-Madison Course, Spring 2011
- CUDA: Breaking the Intel & AMD Dominance
- NVidia CUDA Tutorial Slides (from DoD HPCMP2009)
- Ascalaph Liquid GPU molecular dynamics.
- CUDA implementation for multi-core processors
- Integrate CUDA with Visual C++, September 26, 2008
- CUDA.NET - .NET library for CUDA, Linux/Windows compliant
- CUDA.CS.MSU.SU Russian CUDA developer community
- Enable Intellisense for CUDA in Visual Studio 2008, April 29, 2009
- CUDA Tutorials for high performance computing
- An introduction to CUDA (French)
- NVidia CUDA Tutorial & Examples (from ISC2009)
- GPUBrasil.com, First website on GPGPU in Portuguese
- 3D cloth Simulation OptiTex.com, Implementation of CUDA in Cloth simulation
- DualSPHysics, Implementation of CUDA in Smoothed Particle Hydrodynamics
- DDJ CUDA series, First in the Doctor Dobb's Journal series teaching CUDA (over 22 articles by Rob Farber)
- Technical Report on implementing a real-time fluid simulator with CUDA
- CUDA - A demonstration w.r.t Exact String Matching Algorithms
- Exploring CUDA via the Euclidean Distance
- CUDA Examples
- Parallel Computing Center Parallel Computing, using GPU. Creating and porting various application (jCUDA, CUDA C++). Ukraine, Khmelnitskiy National University.
Nvidia Graphics processing units Early chipsetsRIVA seriesGeForce 256 · GeForce 2 · GeForce 3 · GeForce 4 · GeForce 5 · GeForce 6 · GeForce 7 · GeForce 8 · GeForce 9 · GeForce 100 · GeForce 200 · GeForce 300 · GeForce 400 · GeForce 500Other seriesTechnologiesMotherboard chipsets GeForce SeriesnForce SeriesnForce 220/415/420 · nForce2 · nForce3 · nForce4 · nForce 500 · nForce 600 · nForce 700 · nForce 900TechnologiesOther products Project DenverBridge chipsHandheldSoftwareAcquisitionsKey people Jen-Hsun Huang · Chris Malachowsky · Curtis Priem · David Kirk · Debora Shoquist · Dr. Ranga Jayaraman · Jonah M. AlbenCPU technologies Architecture Parallelism PipelineLevelThreadsTypes Components Arithmetic logic unit (ALU) · Barrel shifter · Floating-point unit (FPU) · Back-side bus · Multiplexer · Demultiplexer · Registers · Memory management unit (MMU) · Translation lookaside buffer (TLB) · Cache · Register file · Microcode · Control unit · Clock ratePower management
Wikimedia Foundation. 2010.