- Metabolic network modelling
-
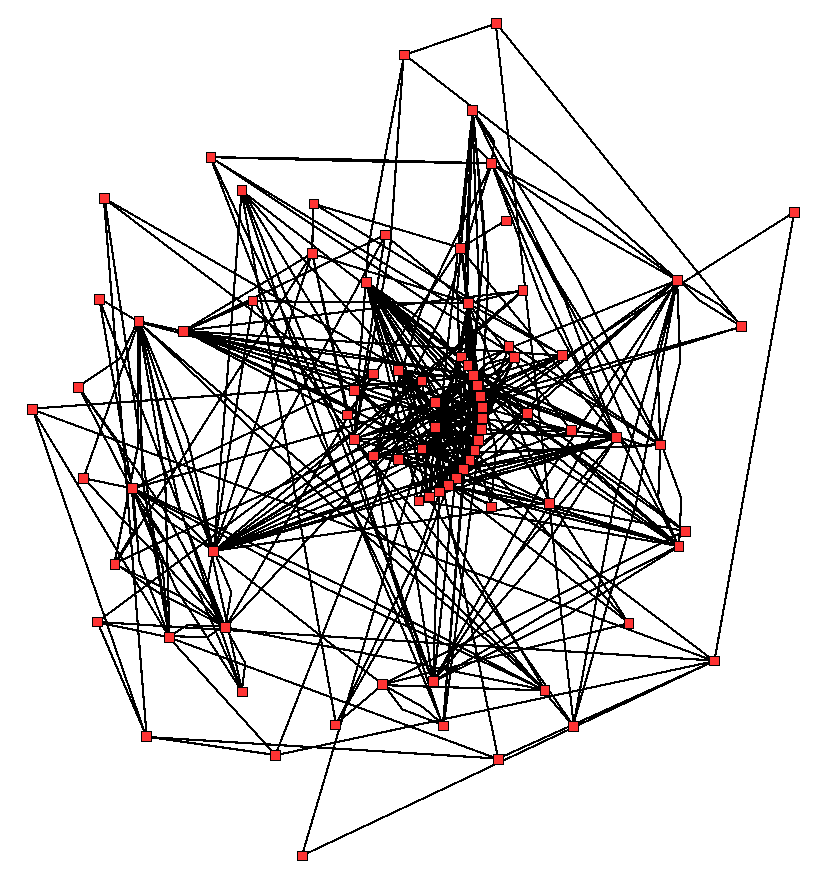
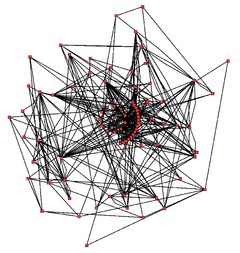 Metabolic network showing interactions between enzymes and metabolites in the Arabidopsis thaliana citric acid cycle. Enzymes and metabolites are the red dots and interactions between them are the lines.
Metabolic network showing interactions between enzymes and metabolites in the Arabidopsis thaliana citric acid cycle. Enzymes and metabolites are the red dots and interactions between them are the lines.
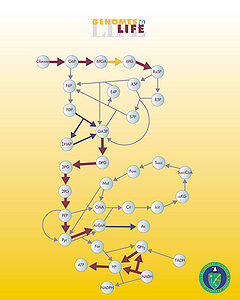
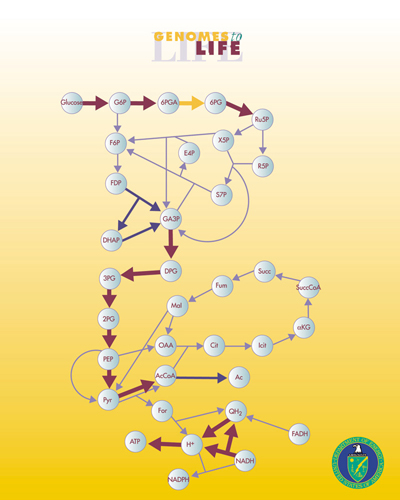
Metabolic network reconstruction and simulation allows for an in depth insight into comprehending the molecular mechanisms of a particular organism, especially correlating the genome with molecular physiology (Francke, Siezen, and Teusink 2005). A reconstruction breaks down metabolic pathways into their respective reactions and enzymes, and analyzes them within the perspective of the entire network. Examples of various metabolic pathways include glycolysis, Krebs cycle, pentose phosphate pathway. In simplified terms, a reconstruction involves collecting all of the relevant metabolic information of an organism and then compiling it in a way that makes sense for various types of analyses to be performed. The correlation between the genome and metabolism is made by searching gene databases, such as KEGG [1], GeneDB [2], for particular genes by inputting enzyme or protein names. For example, a search can be conducted based on the protein name or the EC number (a number that represents the catalytic function of the enzyme of interest) in order to find the associated gene (Francke et al. 2005).
Contents
Beginning steps of a reconstruction
Resources
Below is more detailed description of a few gene/enzyme/reaction/pathway databases that are crucial to a metabolic reconstruction:
- Kyoto Encyclopedia of Genes and Genomes (KEGG): This is a bioinformatics database containing information on genes, proteins, reactions, and pathways. The ‘KEGG Organisms’ section, which is divided into eukaryotes and prokaryotes, encompasses many organisms for which gene and DNA information can be searched by typing in the enzyme of choice. This resource can be extremely useful when building the association between metabolism enzymes, reactions and genes.
- BioCyc, EcoCyc, and MetaCyc: BioCyc is a collection of 1,000 pathway/genome databases (as of Oct 2010), with each database dedicated to one organism. For example, EcoCyc is a highly detailed bioinformatics database on the genome and metabolic reconstruction of Escherichia coli, including thorough descriptions of E. coli signaling pathways and regulatory network. The EcoCyc database can serve as a paradigm and model for any reconstruction. Additionally, MetaCyc, an encyclopedia of experimentally defined metabolic pathways and enzymes, contains 1,500 metabolic pathways and 8,700 metabolic reactions (Oct 2010).
- Pathway Tools [3]: A bioinformatics software package that assists in the construction of pathway/genome databases such as EcoCyc (Karp 2010). Developed by Peter Karp and associates at the SRI International Bioinformatics Group, Pathway Tools comprises several separate units. First, PathoLogic takes an annotated genome for an organism and infers probable metabolic pathways to produce a new pathway/genome database. This can be followed by application of the Pathway Hole Filler, which predicts likely genes to fill "holes" (missing steps) in predicted pathways. Afterward, the Pathway Tools Navigator and Editor functions let users visualize, analyze, access and update the database. Thus, using PathoLogic and encyclopedias like MetaCyc, an initial fast reconstruction can be developed automatically, and then using the other units of Pathway Tools, a very detailed manual update, curation and verification step can be carried out (SRI 2005).
- ERGO: ERGO [4] integrates data from every level including genomic, biochemical data, literature, and high-throughput analysis into a comprehensive user friendly network of metabolic and nonmetabolic pathways.
- metaTIGER [5]: is a collection of metabolic profiles and phylogenomic information on a taxonomically diverse range of eukaryotes. Phylogenomic information is provided by 2,257 large phylogenetic trees which can be interactively explored. High-throughput tree analysis can also be carried out to identify trees of interest, e.g. trees containing horizontal gene transfers. metaTIGER also provides novel facilities for viewing and comparing the metabolic profiles.
- ENZYME: This is an enzyme nomenclature database (part of the ExPASY [6] proteonomics server of the Swiss Institute of Bioinformatics). After searching for a particular enzyme on the database, this resource gives you the reaction that is catalyzed. Additionally, ENZYME has direct links to various other gene/enzyme/medical literature databases such as KEGG, BRENDA, PUBMED, and PUMA2 to name a few.
- BRENDA: A comprehensive enzyme database, BRENDA, allows you to search for an enzyme by name or EC number. You can also search for an organism and find all the relevant enzyme information. Moreover, when an enzyme search is carried out, BRENDA provides a list of all organisms containing the particular enzyme of interest.
- PUBMED: This is an online library developed by the National Center for Biotechnology Information, which contains a massive collection of medical journals. Using the link provided by ENZYME, the search can be directed towards the organism of interest, thus recovering literature on the enzyme and its use inside of the organism.
- Model SEED [7]: This is an online resource for the analysis, comparison, reconstruction, and curation of genome-scale metabolic models (Henry et al. 2010). Users can submit genome sequences to the RAST annotation system, and the resulting annotation can be automatically piped into the Model SEED to produce a draft metabolic model. The Model SEED automatically constructs a network of metabolic reactions, gene-protein-reaction associations for each reaction, and a biomass composition reaction for each genome to produce a model of microbial metabolism that can be simulated using Flux Balance Analysis.
Next steps of the reconstruction
After the initial stages of the reconstruction, a systematic verification is made in order to make sure no inconsistencies are present and that all the entries listed are correct and accurate (Francke et al. 2005). Furthermore, previous literature can be researched in order to support any information obtained from one of the many metabolic reaction and genome databases. This provides an added level of assurance for the reconstruction that the enzyme and the reaction it catalyzes do actually occur in the organism.
Any new reactions not present in the databases need to be added to the reconstruction. The presence or absence of certain reactions of the metabolism will affect the amount of reactants/products that are present for other reactions within the particular pathway. This is because products in one reaction go on to become the reactants for another reaction, i.e. products of one reaction can combine with other proteins or compounds to form new proteins/compounds in the presence of different enzymes or catalysts (Francke et al. 2005).
Francke et al. (2005) provide an excellent example as to why the verification step of the project needs to be performed in significant detail. During a metabolic network reconstruction of Lactobacillus plantarum, the model showed that succinyl-CoA was one of the reactants for a reaction that was a part of the biosynthesis of methionine. However, an understanding of the physiology of the organism would have revealed that due to an incomplete tricarboxylic acid pathway, Lactobacillus plantarum does not actually produce succinyl-CoA, and the correct reactant for that part of the reaction was acetyl-CoA.
Therefore, systematic verification of the initial reconstruction will bring to light several inconsistencies that can adversely affect the final interpretation of the reconstruction, which is to accurately comprehend the molecular mechanisms of the organism. Furthermore, the simulation step also ensures that all the reactions present in the reconstruction are properly balanced. To sum up, a reconstruction that is fully accurate can lead to greater insight about understanding the functioning of the organism of interest (Francke et al. 2005).
Advantages of a reconstruction
- Several inconsistencies exist between gene, enzyme, and reaction databases and published literature sources regarding the metabolic information of an organism. A reconstruction is a systematic verification and compilation of data from various sources that takes into account all of the discrepancies.
- A reconstruction combines the relevant metabolic and genomic information of an organism.
- A reconstruction also allows for metabolic comparisons to be performed between various organisms of the same species as well as between different organisms.
Metabolic network simulation
A metabolic network can be broken down into a stoichiometric matrix where the rows represent the compounds of the reactions, while the columns of the matrix correspond to the reactions themselves. Stoichiometry is a quantitative relationship between substrates of a chemical reaction (Merriam 2002). In order to deduce what the metabolic network suggests, recent research has centered on two approaches; namely extreme pathways and elementary mode analysis (Papin, Stelling, Price, Klamt, Schuster, and Palsson 2004).
Extreme Pathways
Price, Reed, Papin, Wiback and Palsson (2003) use a method of singular value decomposition (SVD) of extreme pathways in order to understand regulation of a human red blood cell metabolism. Extreme pathways are convex basis vectors that consist of steady state functions of a metabolic network (Papin, Price, and Palsson 2002). For any particular metabolic network, there is always a unique set of extreme pathways available (Papin et al. 2004). Furthermore, Price et al. (2003) define a constraint-based approach, where through the help of constraints like mass balance and maximum reaction rates, it is possible to develop a ‘solution space’ where all the feasible options fall within. Then, using a kinetic model approach, a single solution that falls within the extreme pathway solution space can be determined (Price et al. 2003). Therefore, in their study, Price et al. (2003) use both constraint and kinetic approaches to understand the human red blood cell metabolism. In conclusion, using extreme pathways, the regulatory mechanisms of a metabolic network can be studied in further detail.
Elementary mode analysis
Elementary mode analysis closely matches the approach used by extreme pathways. Similar to extreme pathways, there is always a unique set of elementary modes available for a particular metabolic network (Papin et al. 2004). These are the smallest sub-networks that allow a metabolic reconstruction network to function in steady state (Schuster, Fell, and Dandekar 2000; Stelling, Klamt, Bettenbrock, Schuster, and Gilles 2002). According to Stelling et al. (2002), elementary modes can be used to understand cellular objectives for the overall metabolic network. Furthermore, elementary mode analysis takes into account stoichiometrics and thermodynamics when evaluating whether a particular metabolic route or network is feasible and likely for a set of proteins/enzymes (Schuster et al. 2000).
Minimal metabolic behaviors (MMBs)
Recently, Larhlimi and Bockmayr (2009) presented a new approach called "minimal metabolic behaviors" for the analysis of metabolic networks. Like elementary modes or extreme pathways, these are uniquely determined by the network, and yield a complete description of the flux cone. However, the new description is much more compact. In contrast with elementary modes and extreme pathways, which use an inner description based on generating vectors of the flux cone, MMBs are using an outer description of the flux cone. This approach is based on sets of non-negativity constraints. These can be identified with irreversible reactions, and thus have a direct biochemical interpretation. One can characterize a metabolic network by MMBs and the reversible metabolic space.
Flux balance analysis
A different technique to simulate the metabolic network is to perform flux balance analysis. This method uses linear programming, but in contrast to elementary mode analysis and extreme pathways, only a single solution results in the end. Linear programming is usually used to obtain the maximum potential of the objective function that you are looking at, and therefore, when using flux balance analysis, a single solution is found to the optimization problem (Stelling et al. 2002). In a flux balance analysis approach, exchange fluxes are assigned to those metabolites that enter or leave the particular network only. Those metabolites that are consumed within the network are not assigned any exchange flux value. Also, the exchange fluxes along with the enzymes can have constraints ranging from a negative to positive value (ex: -10 to 10).
Furthermore, this particular approach can accurately define if the reaction stoichiometry is in line with predictions by providing fluxes for the balanced reactions. Also, flux balance analysis can highlight the most effective and efficient pathway through the network in order to achieve a particular objective function. In addition, gene knockout studies can be performed using flux balance analysis. The enzyme that correlates to the gene that needs to be removed is given a constraint value of 0. Then, the reaction that the particular enzyme catalyzes is completely removed from the analysis.
Dynamic simulation and parameter estimation
In order to perform a dynamic simulation with such a network it is necessary to construct an ordinary differential equation system that describes the rates of change in each metabolite's concentration or amount. To this end, a rate law, i.e., a kinetic equation is required for each reaction. Often these rate laws contain kinetic parameters with uncertain values. In many cases it is desired to estimate these parameter values with respect to given time-series data of metabolite concentrations. The system is then supposed to reproduce the given data. For this purpose the distance between the given data set and the result of the simulation, i.e., the numerically or in few cases analytically obtained solution of the differential equation system is computed. The values of the parameters are then estimated to minimize this distance (Dräger et al. 2009). One step further, it may be desired to estimate the mathematical structure of the differential equation system because the real rate laws are not known for the reactions within the system under study. To this end, the program SBMLsqueezer allows automatic creation of appropriate rate laws for all reactions with the network.
Conclusion
In conclusion, metabolic network reconstruction and simulation can be effectively used to understand how an organism or parasite functions inside of the host cell. For example, if the parasite serves to compromise the immune system by lysing macrophages, then the goal of metabolic reconstruction/simulation would be to determine the metabolites that are essential to the organism's proliferation inside of macrophages. If the proliferation cycle is inhibited, then the parasite would not continue to evade the host's immune system. A reconstruction model serves as a first step to deciphering the complicated mechanisms surrounding disease. The next step would be to use the predictions and postulates generated from a reconstruction model and apply it to drug delivery and drug-engineering techniques.
Currently, many tropical diseases affecting third world nations are very inadequately characterized, and thus poorly understood. Therefore, a metabolic reconstruction and simulation of the parasites that cause the tropical diseases would aid in developing new and innovative cures and treatments.
See also
- Metabolic network
- Computer simulation
- Computational systems biology
- Metabolic pathway
- Metagenomics
- Metabolic control analysis
References
- Dräger, A, Kronfeld, M, Ziller, M. J., Supper, J., Planatscher, H., Magnus, J. B., Oldiges, M., Kohlbacher, O., and Zell, A. (2009). Modeling metabolic networks in C. glutamicum: a comparison of rate laws in combination with various parameter optimization strategies. BMC Systems Biology, 3(5). doi:10.1186/1752-0509-3-5
- Francke, C., Siezen, R. J. and Teusink, B. (2005). Reconstructing the metabolic network of a bacterium from its genome. Trends in Microbiology. 13(11): 550-558.
- Merriam Webster's Medical Dictionary. (2002). http://dictionary.reference.com/medical/
- Papin, J.A., Price, N.D., and Palsson, B.O. (2002). Extreme Pathway Lengths and Reaction Participation in Genome-Scale Metabolic Networks. Genome Research. 12: 1889–1900.
- Papin, J.A., Stelling, J., Price, N.D., Klamt, S., Schuster, S., and Palsson, B.O. (2004). Comparison of network-based pathway analysis methods. Trends in Biotechnology. 22(8): 400-405.
- Price, N.D., Reed, J.L., Papin, J.A., Wiback, S.J., and Palsson, B.O. (2003). Network-based analysis of metabolic regulation in the human red blood cell. Journal of Theoretical Biology. 225: 185-194.
- Schuster, S., Fell, D.A. and Dandekar, T. (2000). A general definition of metabolic pathways useful for systematic organization and analysis of complex metabolic networks. Nature Biotechnology. 18: 326-332.
- SRI International. (2005). Pathway Tools Information Site. http://bioinformatics.ai.sri.com/ptools/
- Stelling, J., Klamt, S., Bettenbrock, K., Schuster, S. and Gilles, E.D. (2002). Metabolic network structure determines key aspects of functionality and regulation. Nature. 420: 190-193.
- Larhlimi, A., Bockmayr, A. (2009) A new constraint-based description of the steady-state flux cone of metabolic networks. Discrete Applied Mathematics. 157: 2257–2266. doi:10.1016/j.dam.2008.06.039
- Overbeek R, Larsen N, Walunas T, D'Souza M, Pusch G, Selkov Jr, Liolios K, Joukov V, Kaznadzey D, Anderson I, Bhattacharyya A, Burd H, Gardner W, Hanke P, Kapatral V, Mikhailova N, Vasieva O, Osterman A, Vonstein V, Fonstein M, Ivanova N, Kyrpides N. (2003) The ERGO genome analysis and discovery system. Nucleic Acids Res. 31(1):164-71
- Whitaker, J.W., Letunic, I., McConkey, G.A. and Westhead, D.R. metaTIGER: a metabolic evolution resource. Nucleic Acids Res. 2009 37: D531-8.
- Karp, P.D., et al., Pathway Tools version 13.0: Integrated Software for Pathway/Genome Informatics and Systems Biology. Briefings in Bioinformatics. 2010 11:40-79.
- Henry, C.S., DeJongh, M., Best, A.B., Frybarger, P.M., Linsay, B., and R.L. Stevens. High-throughput Generation and Optimization of Genome-scale Metabolic Models. Nature Biotechnology. 2010. doi:10.1038/nbt.1672
External links
- ERGO
- GeneDB
- KEGG
- PathCase Case Western Reserve University
- BRENDA
- BioCyc and Cyclone - provides an open source Java API to the pathway tool BioCyc to extract Metabolic graphs.
- EcoCyc
- MetaCyc
- SEED
- Model SEED
- ENZYME
- SBRI Bioinformatics Tools and Software
- TIGR
- Pathway Tools
- metaTIGER
- Stanford Genomic Resources
- Pathway Hunter Tool
- IMG The Integrated Microbial Genomes system, for genome analysis by the DOE-JGI.
- Systems Analysis, Modelling and Prediction Group at the University of Oxford, Biochemical reaction pathway inference techniques.
- EFMtool provided by Marco Terzer
- SBMLsqueezer
- Cellnet analyzer from Klamt and von Kamp
- Copasi
Scientific modelling Biological Biological data visualization · Chemical process modeling · Cellular model · Protein structure prediction · Ecosystem model · Infectious disease model · Metabolic network modellingEnvironmental Atmospheric model · Wildfire modeling · Chemical transport model · Modular Ocean Model · Climate model · Hydrological modelling · Hydrological transport model · Groundwater model · Geologic modellingSocial Crime mapping · Population model · Biopsychosocial model · Economic model · Input-output model · Business process modelling · Construction and management simulation · Catastrophe modelingRelated topics Systems thinking · Mathematical modeling · Model theory · Systems theory · Visual analytics · Data visualization · List of computer simulation software
Wikimedia Foundation. 2010.