- Data transformation (statistics)
-
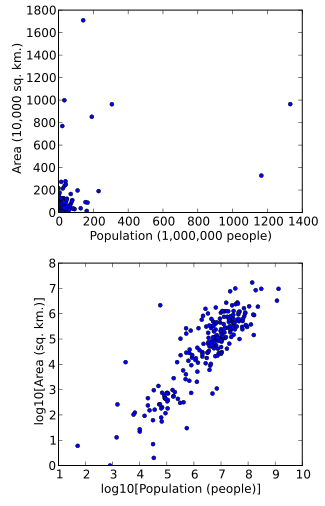 A scatterplot in which the areas of the sovereign states and dependent territories in the world are plotted on the vertical axis against their populations on the horizontal axis. The upper plot uses raw data. In the lower plot, both the area and population data have been transformed using the logarithm function.
A scatterplot in which the areas of the sovereign states and dependent territories in the world are plotted on the vertical axis against their populations on the horizontal axis. The upper plot uses raw data. In the lower plot, both the area and population data have been transformed using the logarithm function.
In statistics, data transformation refers to the application of a deterministic mathematical function to each point in a data set — that is, each data point zi is replaced with the transformed value yi = f(zi), where f is a function. Transforms are usually applied so that the data appear to more closely meet the assumptions of a statistical inference procedure that is to be applied, or to improve the interpretability or appearance of graphs.
Nearly always, the function that is used to transform the data is invertible, and generally is continuous. The transformation is usually applied to a collection of comparable measurements. For example, if we are working with data on peoples' incomes in some currency unit, it would be common to transform each person's income value by the logarithm function.
Contents
Reasons for transforming data
Guidance for how data should be transformed, or whether a transform should be applied at all, should come from the particular statistical analysis to be performed. For example, a simple way to construct an approximate 95% confidence interval for the population mean is to take the sample mean plus or minus two standard error units. However, the constant factor 2 used here is particular to the normal distribution, and is only applicable if the sample mean varies approximately normally. The central limit theorem states that in many situations, the sample mean does vary normally if the sample size is reasonably large. However if the population is substantially skewed and the sample size is at most moderate, the approximation provided by the central limit theorem can be poor, and the resulting confidence interval will likely have the wrong coverage probability. Thus, when there is evidence of substantial skew in the data, it is common to transform the data to a symmetric distribution before constructing a confidence interval. If desired, the confidence interval can then be transformed back to the original scale using the inverse of the transformation that was applied to the data.
Data can also be transformed to make it easier to visualize them. For example, suppose we have a scatterplot in which the points are the countries of the world, and the data values being plotted are the land area and population of each country. If the plot is made using untransformed data (e.g. square kilometers for area and the number of people for population), most of the countries would be plotted in tight cluster of points in the lower left corner of the graph. The few countries with very large areas and/or populations would be spread thinly around most of the graph's area. Simply rescaling units (e.g. to thousand square kilometers, or to millions of people) will not change this. However, following logarithmic transformations of both area and population, the points will be spread more uniformly in the graph.
A final reason that data can be transformed is to improve interpretability, even if no formal statistical analysis or visualization is to be performed. For example, suppose we are comparing cars in terms of their fuel economy. These data are usually presented as "kilometers per liter" or "miles per gallon." However if the goal is to assess how much additional fuel a person would use in one year when driving one car compared to another, it is more natural to work with the data transformed by the reciprocal function, yielding liters per kilometer, or gallons per mile.
Data transformation in regression
Linear regression is a statistical technique for relating a dependent variable Y to one or more independent variables X. The simplest regression models capture a linear relationship between the expected value of Y and each independent variable (when the other independent variables are held fixed). If linearity fails to hold, even approximately, it is sometimes possible to transform either the independent or dependent variables in the regression model to improve the linearity.
Another assumption of linear regression is that the variance be the same for each possible expected value (this is known as homoskedasticity). Univariate normality is not needed for least squares estimates of the regression parameters to be meaningful (see Gauss-Markov theorem). However confidence intervals and hypothesis tests will have better statistical properties if the variables exhibit multivariate normality. This can be assessed empirically by plotting the fitted values against the residuals, and by inspecting the normal quantile plot of the residuals. Note that it is not relevant whether the dependent variable Y is marginally normally distributed.
Examples of logarithmic transformations
Equation: Y = a + bX
Meaning: A unit increase in X is associated with an average of b units increase in Y.
Equation: log(Y) = a + bX (From taking the log of both sides of the equation: Y = eaebX)
Meaning: A unit increase in X is associated with an average of 100b% increase in Y.
Equation: Y = a + blog(X)
Meaning: A 1% increase in X is associated with an average b/100 units increase in Y.
Equation: log(Y) = a + blog(X) (From taking the log of both sides of the equation: Y = eaXb)
Meaning: A 1% increase in X is associated with a b% increase in Y.
Common transformations
The logarithm and square root transformations are commonly used for positive data, and the multiplicative inverse (reciprocal) transformation can be used for non-zero data. The power transform is a family of transformations parametrized by a non-negative value λ that includes the logarithm, square root, and multiplicative inverse as special cases. To approach data transformation systematically, it is possible to use statistical estimation techniques to estimate the parameter λ in the power transform, thereby identifying the transform that is approximately the most appropriate in a given setting. Since the power transform family also includes the identity transform, this approach can also indicate whether it would be best to analyze the data without a transformation. In regression analysis, this approach is known as the Box-Cox technique.
The reciprocal and some power transformations can be meaningfully applied to data that include both positive and negative values (the power transform is invertible over all real numbers if λ is an odd integer). However when both negative and positive values are observed, it is more common to begin by adding a constant to all values, producing a set of non-negative data to which any power transform can be applied.
A common situation where a data transformation is applied is when a value of interest ranges over several orders of magnitude. Many physical and social phenomena exhibit such behavior — incomes, species populations, galaxy sizes, and rainfall volumes, to name a few. Power transforms, and in particular the logarithm, can often be used to induce symmetry in such data. The logarithm is often favored because it is easy to interpret its result in terms of "fold changes."
The logarithm also has a useful effect on ratios. If we are comparing positive quantities X and Y using the ratio X / Y, then if X < Y, the ratio is in the unit interval (0,1), whereas if X > Y, the ratio is in the half-line (1,∞), where the ratio of 1 corresponds to equality. In an analysis where X and Y are treated symmetrically, the log-ratio log(X / Y) is zero in the case of equality, and it has the property that if X is K times greater than Y, the log-ratio is the equidistant from zero as in the situation where Y is K times greater than X (the log-ratios are log(K) and −log(K) in these two situations).
If values are naturally restricted to be in the range 0 to 1, not including the end-points, then a logit transformation may be appropriate: this yields values in the range (−∞,∞).
Transforming to normality
It is not always necessary or desirable to transform a data set to resemble a normal distribution. However if symmetry or normality are desired, they can often be induced through one of the power transformations.
To assess whether normality has been achieved, a graphical approach is usually more informative than a formal statistical test. A normal quantile plot is commonly used to assess the fit of a data set to a normal population. Alternatively, rules of thumb based on the sample skewness and kurtosis have also been proposed, such as having skewness in the range of −0.8 to 0.8 and kurtosis in the range of −3.0 to 3.0.[citation needed]
Transforming to a uniform distribution
If we observe a set of n values X1, ..., Xn with no ties (i.e. there are n distinct values), we can replace Xi with the transformed value Yi = k, where k is defined such that Xi is the kth largest among all the X values. This is called the rank transform[citation needed], and creates data with a perfect fit to a uniform distribution. This approach has a population analogue. If X is any random variable, and F is the cumulative distribution function of X, then as long as F is invertible, the random variable U = F(X) follows a uniform distribution on the unit interval [0,1].
From a uniform distribution, we can transform to any distribution with an invertible cumulative distribution function. If G is an invertible cumulative distribution function, and U is a uniformly distributed random variable, then the random variable G−1(U) has G as its cumulative distribution function.
Variance stabilizing transformations
Main article: Variance-stabilizing transformationMany types of statistical data exhibit a "mean/variance relationship", meaning that the variability is different for data values with different expected values. As an example, in many parts of the world incomes follow an increasing mean/variance relationship. If we consider a number of small area units (e.g., counties in the United States) and obtain the mean and variance of incomes within each county, it is common that the counties with higher mean income also have higher variances.
A variance-stabilizing transformation aims to remove a mean/variance relationship, so that the variance becomes constant relative to the mean. Examples of variance-stabilizing transformations are the Fisher transformation for the sample correlation coefficient, the square root transformation or Anscombe transform for Poisson data (count data), the Box-Cox transformation for regression analysis and the arcsine square root transformation or angular transformation for proportions (binomial data).
Transformations for multivariate data
Univariate functions can be applied point-wise to multivariate data to modify their marginal distributions. It is also possible to modify some attributes of a multivariate distribution using an appropriately constructed transformation. For example, when working with time series and other types of sequential data, it is common to difference the data to improve stationarity. If data are observed as random vectors Xi with covariance matrix Σ, a linear transformation can be used to decorrelate the data. To do this, use the Cholesky decomposition to express Σ = A A'. Then the transformed vector Yi = A−1Xi has the identity matrix as its covariance matrix.
External links
Categories:- Data analysis
- Transforms

Wikimedia Foundation. 2010.