- World Wide Web
-
"WWW" redirects here. For other uses, see WWW (disambiguation)."The Web" redirects here. For other uses, see Web (disambiguation).Not to be confused with the Internet.
World Wide Web 
The Web's historic logo designed by Robert CailliauInventor Tim Berners-Lee[1] Launch year 1991 Company CERN Availability Worldwide The World Wide Web (or the proper World-Wide Web; abbreviated as WWW or W3,[2] and commonly known as the Web) is a system of interlinked hypertext documents accessed via the Internet. With a web browser, one can view web pages that may contain text, images, videos, and other multimedia and navigate between them via hyperlinks.
Using concepts from earlier hypertext systems, British engineer and computer scientist Sir Tim Berners-Lee, now Director of the World Wide Web Consortium (W3C), wrote a proposal in March 1989 for what would eventually become the World Wide Web.[1] At CERN in Geneva, Switzerland, Berners-Lee and Belgian computer scientist Robert Cailliau proposed in 1990 to use hypertext "... to link and access information of various kinds as a web of nodes in which the user can browse at will",[3] and they publicly introduced the project in December.[4]
"The World-Wide Web was developed to be a pool of human knowledge, and human culture, which would allow collaborators in remote sites to share their ideas and all aspects of a common project."[5]
Contents
History
Main article: History of the World Wide Web The NeXT Computer used by Berners-Lee. The hand label declares, "This machine is a server. DO NOT POWER IT DOWN!!"
The NeXT Computer used by Berners-Lee. The hand label declares, "This machine is a server. DO NOT POWER IT DOWN!!"
In the June 1970 issue of Popular Science magazine Arthur C. Clarke was reported to have predicted that satellites would one day "bring the accumulated knowledge of the world to your fingertips" using a console that would combine the functionality of the Xerox, telephone, television and a small computer, allowing data transfer and video conferencing around the globe.[6]
In March 1989, Tim Berners-Lee wrote a proposal that referenced ENQUIRE, a database and software project he had built in 1980, and described a more elaborate information management system.[7]
With help from Robert Cailliau, he published a more formal proposal (on November 12, 1990) to build a "Hypertext project" called "WorldWideWeb" (one word, also "W3") as a "web" of "hypertext documents" to be viewed by "browsers" using a client–server architecture.[3] This proposal estimated that a read-only web would be developed within three months and that it would take six months to achieve "the creation of new links and new material by readers, [so that] authorship becomes universal" as well as "the automatic notification of a reader when new material of interest to him/her has become available." While the read-only goal was met, accessible authorship of web content took longer to mature, with the wiki concept, blogs, Web 2.0 and RSS/Atom.[8]
The proposal was modeled after the Dynatext SGML reader by Electronic Book Technology, a spin-off from the Institute for Research in Information and Scholarship at Brown University. The Dynatext system, licensed by CERN, was technically advanced and was a key player in the extension of SGML ISO 8879:1986 to Hypermedia within HyTime, but it was considered too expensive and had an inappropriate licensing policy for use in the general high energy physics community, namely a fee for each document and each document alteration.
 The CERN datacenter in 2010 housing some www servers
The CERN datacenter in 2010 housing some www serversA NeXT Computer was used by Berners-Lee as the world's first web server and also to write the first web browser, WorldWideWeb, in 1990. By Christmas 1990, Berners-Lee had built all the tools necessary for a working Web:[9] the first web browser (which was a web editor as well); the first web server; and the first web pages,[10] which described the project itself. On August 6, 1991, he posted a short summary of the World Wide Web project on the alt.hypertext newsgroup.[11] This date also marked the debut of the Web as a publicly available service on the Internet. The first photo on the web was uploaded by Berners-Lee in 1992, an image of the CERN house band Les Horribles Cernettes.
Web as a "Side Effect" of the 40 years of Particle Physics Experiments. It happened many times during history of science that the most impressive results of large scale scientific efforts appeared far away from the main directions of those efforts... After the World War 2 the nuclear centers of almost all developed countries became the places with the highest concentration of talented scientists. For about four decades many of them were invited to the international CERN's Laboratories. So specific kind of the CERN's intellectual "entire culture" (as you called it) was constantly growing from one generation of the scientists and engineers to another. When the concentration of the human talents per square foot of the CERN's Labs reached the critical mass, it caused an intellectual explosion The Web – crucial point of human's history – was born... Nothing could be compared to it... We cant imagine yet the real scale of the recent shake, because there has not been so fast growing multi-dimension social-economic processes in human history...[12]
The first server outside Europe was set up at SLAC to host the SPIRES-HEP database. Accounts differ substantially as to the date of this event. The World Wide Web Consortium says December 1992,[13] whereas SLAC itself claims 1991.[14][15] This is supported by a W3C document entitled A Little History of the World Wide Web.[16]
The crucial underlying concept of hypertext originated with older projects from the 1960s, such as the Hypertext Editing System (HES) at Brown University, Ted Nelson's Project Xanadu, and Douglas Engelbart's oN-Line System (NLS). Both Nelson and Engelbart were in turn inspired by Vannevar Bush's microfilm-based "memex", which was described in the 1945 essay "As We May Think".[citation needed]
Berners-Lee's breakthrough was to marry hypertext to the Internet. In his book Weaving The Web, he explains that he had repeatedly suggested that a marriage between the two technologies was possible to members of both technical communities, but when no one took up his invitation, he finally tackled the project himself. In the process, he developed three essential technologies:
- a system of globally unique identifiers for resources on the Web and elsewhere, the Universal Document Identifier (UDI), later known as Uniform Resource Locator (URL) and Uniform Resource Identifier (URI);
- the publishing language HyperText Markup Language (HTML);
- the Hypertext Transfer Protocol (HTTP).[17]
The World Wide Web had a number of differences from other hypertext systems that were then available. The Web required only unidirectional links rather than bidirectional ones. This made it possible for someone to link to another resource without action by the owner of that resource. It also significantly reduced the difficulty of implementing web servers and browsers (in comparison to earlier systems), but in turn presented the chronic problem of link rot. Unlike predecessors such as HyperCard, the World Wide Web was non-proprietary, making it possible to develop servers and clients independently and to add extensions without licensing restrictions. On April 30, 1993, CERN announced that the World Wide Web would be free to anyone, with no fees due.[18] Coming two months after the announcement that the server implementation of the Gopher protocol was no longer free to use, this produced a rapid shift away from Gopher and towards the Web. An early popular web browser was ViolaWWW for Unix and the X Windowing System.
Scholars generally agree that a turning point for the World Wide Web began with the introduction[19] of the Mosaic web browser[20] in 1993. A graphical browser developed by a team at the National Center for Supercomputing Applications at the University of Illinois at Urbana-Champaign (NCSA-UIUC), led by Marc Andreessen, funding for Mosaic came from the U.S. High-Performance Computing and Communications Initiative and the High Performance Computing and Communication Act of 1991, one of several computing developments initiated by U.S. Senator Al Gore.[21] Prior to the release of Mosaic, graphics were not commonly mixed with text in web pages and the Web's popularity was less than older protocols in use over the Internet, such as Gopher and Wide Area Information Servers (WAIS). Mosaic's graphical user interface allowed the Web to become, by far, the most popular Internet protocol.
The World Wide Web Consortium (W3C) was founded by Tim Berners-Lee after he left the European Organization for Nuclear Research (CERN) in October 1994. It was founded at the Massachusetts Institute of Technology Laboratory for Computer Science (MIT/LCS) with support from the Defense Advanced Research Projects Agency (DARPA), which had pioneered the Internet; a year later, a second site was founded at INRIA (a French national computer research lab) with support from the European Commission DG InfSo; and in 1996, a third continental site was created in Japan at Keio University. By the end of 1994, while the total number of websites was still minute compared to present standards, quite a number of notable websites were already active, many of which are the precursors or inspiration for today's most popular services.
Connected by the existing Internet, other websites were created around the world, adding international standards for domain names and HTML. Since then, Berners-Lee has played an active role in guiding the development of web standards (such as the markup languages in which web pages are composed), and in recent years has advocated his vision of a Semantic Web. The World Wide Web enabled the spread of information over the Internet through an easy-to-use and flexible format. It thus played an important role in popularizing use of the Internet.[22] Although the two terms are sometimes conflated in popular use, World Wide Web is not synonymous with Internet.[23] The Web is a collection of documents and both client and server software using Internet protocols such as TCP/IP and HTTP.
Function
The terms Internet and World Wide Web are often used in every-day speech without much distinction. However, the Internet and the World Wide Web are not one and the same. The Internet is a global system of interconnected computer networks. In contrast, the Web is one of the services that runs on the Internet. It is a collection of textual documents and other resources, linked by hyperlinks and URLs, transmitted by web browsers and web servers. In short, the Web can be thought of as an application "running" on the Internet.[24]
Viewing a web page on the World Wide Web normally begins either by typing the URL of the page into a web browser or by following a hyperlink to that page or resource. The web browser then initiates a series of communication messages, behind the scenes, in order to fetch and display it. As an example, consider the Wikipedia page for this article with the URL http://en.wikipedia.org/wiki/World_Wide_Web .
First, the browser resolves the server-name portion of the URL (en.wikipedia.org) into an Internet Protocol address using the globally distributed database known as the Domain Name System (DNS); this lookup returns an IP address such as 208.80.152.2. The browser then requests the resource by sending an HTTP request across the Internet to the computer at that particular address. It makes the request to a particular application port in the underlying Internet Protocol Suite so that the computer receiving the request can distinguish an HTTP request from other network protocols it may be servicing such as e-mail delivery; the HTTP protocol normally uses port 80. The content of the HTTP request can be as simple as the two lines of text
GET /wiki/World_Wide_Web HTTP/1.1 Host: en.wikipedia.org
The computer receiving the HTTP request delivers it to Web server software listening for requests on port 80. If the web server can fulfill the request it sends an HTTP response back to the browser indicating success, which can be as simple as
HTTP/1.0 200 OK Content-Type: text/html; charset=UTF-8
followed by the content of the requested page. The Hypertext Markup Language for a basic web page looks like
<html> <head> <title>World Wide Web — Wikipedia, the free encyclopedia</title> </head> <body> <p>The World Wide Web, abbreviated as WWW and commonly known ...</p> </body> </html>
The web browser parses the HTML, interpreting the markup (<title>, <b> for bold, and such) that surrounds the words in order to draw that text on the screen.
Many web pages consist of more elaborate HTML which references the URLs of other resources such as images, other embedded media, scripts that affect page behavior, and Cascading Style Sheets that affect page layout. A browser that handles complex HTML will make additional HTTP requests to the web server for these other Internet media types. As it receives their content from the web server, the browser progressively renders the page onto the screen as specified by its HTML and these additional resources.
Linking
Most web pages contain hyperlinks to other related pages and perhaps to downloadable files, source documents, definitions and other web resources (this Wikipedia article is full of hyperlinks). In the underlying HTML, a hyperlink looks like
<a href="http://www.w3.org/History/19921103-hypertext/hypertext/WWW/">Early archive
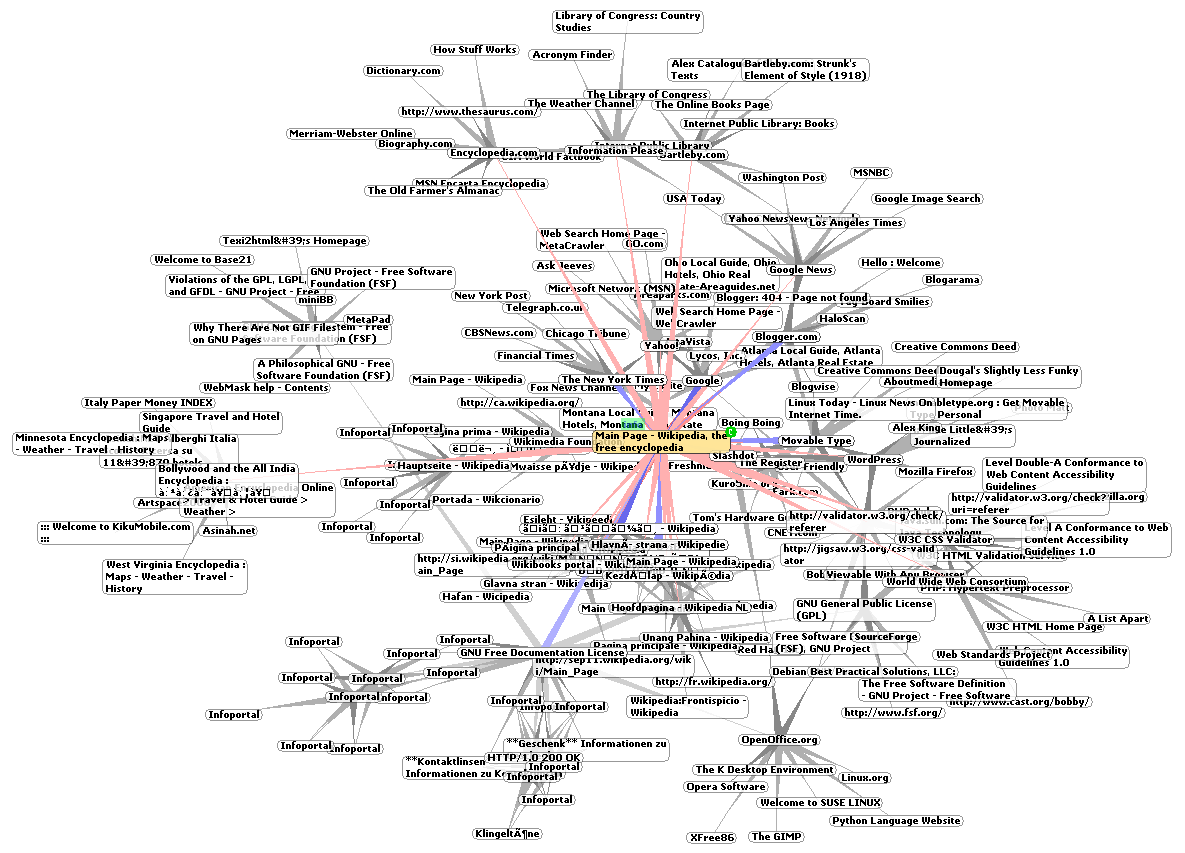
of the first Web site</a> Graphic representation of a minute fraction of the WWW, demonstrating hyperlinks
Graphic representation of a minute fraction of the WWW, demonstrating hyperlinksSuch a collection of useful, related resources, interconnected via hypertext links is dubbed a web of information. Publication on the Internet created what Tim Berners-Lee first called the WorldWideWeb (in its original CamelCase, which was subsequently discarded) in November 1990.[3]
The hyperlink structure of the WWW is described by the webgraph: the nodes of the webgraph correspond to the webpages (or URLs) the directed edges between them to the hyperlinks.
Over time, many web resources pointed to by hyperlinks disappear, relocate, or are replaced with different content. This makes hyperlinks obsolete, a phenomenon referred to in some circles as link rot and the hyperlinks affected by it are often called dead links. The ephemeral nature of the Web has prompted many efforts to archive web sites. The Internet Archive, active since 1996, is one of the best-known efforts.
Dynamic updates of web pages
Main article: Ajax (programming)JavaScript is a scripting language that was initially developed in 1995 by Brendan Eich, then of Netscape, for use within web pages.[25] The standardized version is ECMAScript.[25] To overcome some of the limitations of the page-by-page model described above, some web applications also use Ajax (asynchronous JavaScript and XML). JavaScript is delivered with the page that can make additional HTTP requests to the server, either in response to user actions such as mouse-clicks or based on lapsed time. The server's responses are used to modify the current page rather than creating a new page with each response. Thus, the server must provide only limited, incremental information. Since multiple Ajax requests can be handled at the same time, users can interact with a page even while data is being retrieved. Some web applications regularly poll the server to ask whether new information is available.[26]
WWW prefix
Many domain names used for the World Wide Web begin with www because of the long-standing practice of naming Internet hosts (servers) according to the services they provide. The hostname for a web server is often www, in the same way that it may be ftp for an FTP server, and news or nntp for a USENET news server. These host names appear as Domain Name System (DNS) subdomain names, as in www.example.com. The use of 'www' as a subdomain name is not required by any technical or policy standard; indeed, the first ever web server was called nxoc01.cern.ch,[27] and many web sites exist without it. Many established websites still use 'www', or they invent other subdomain names such as 'www2', 'secure', etc. Many such web servers are set up such that both the domain root (e.g., example.com) and the www subdomain (e.g., www.example.com) refer to the same site; others require one form or the other, or they may map to different web sites.
The use of a subdomain name is useful for load balancing incoming web traffic by creating a CNAME record that points to a cluster of web servers. Since, currently, only a subdomain can be cname'ed, the same result cannot be achieved by using the bare domain root.
When a user submits an incomplete domain name to a web browser in its address bar input field, some web browsers automatically try adding the prefix "www" to the beginning of it and possibly ".com", ".org" and ".net" at the end, depending on what might be missing. For example, entering 'microsoft' may be transformed to http://www.microsoft.com/ and 'openoffice' to http://www.openoffice.org. This feature started appearing in early versions of Mozilla Firefox, when it still had the working title 'Firebird' in early 2003, from an earlier practice in browsers such as Lynx.[28] It is reported that Microsoft was granted a US patent for the same idea in 2008, but only for mobile devices.[29]
In English, www is pronounced by individually pronouncing the name of characters (double-u double-u double-u) or by saying the phrase "triple double-u". Although some technical users pronounce it dub-dub-dub, this is not widespread. The English writer Douglas Adams once quipped in The Independent on Sunday (1999): "The World Wide Web is the only thing I know of whose shortened form takes three times longer to say than what it's short for," with Stephen Fry later pronouncing it in his "Podgrammes" series of podcasts as "wuh wuh wuh." In Mandarin Chinese, World Wide Web is commonly translated via a phono-semantic matching to wàn wéi wǎng (万维网), which satisfies www and literally means "myriad dimensional net",[30] a translation that very appropriately reflects the design concept and proliferation of the World Wide Web. Tim Berners-Lee's web-space states that World Wide Web is officially spelled as three separate words, each capitalized, with no intervening hyphens.[31]
Use of the www prefix is declining as Web 2.0 web applications seek to brand their domain names and make them easily pronounceable.[32] As the mobile web grows in popularity, services like Gmail.com, MySpace.com, Facebook.com and Twitter.com are most often discussed without adding the www to the domain (or the .com)
http and https specifiers
The scheme specifiers (http:// or https://) in URIs refer to the Hypertext Transfer Protocol and to HTTP Secure, respectively, and so define the communication protocol to be used for the request and response. The HTTP protocol is fundamental to the operation of the World Wide Web; the added encryption layer in HTTPS is essential when confidential information such as passwords or banking information are to be exchanged over the public Internet. Web browsers usually prepend the scheme to URLs too, if omitted.
Privacy
It is possible that, average computer users who use the World Wide Web mainly for things like entertainment, may have surrendered the right to privacy in exchange for using a number of services available on the World Wide Web.[33][vague] For example: more than half a billion people worldwide have used a social network service,[34] and of the generations of people within the United States who have had access to the internet from a young age, half have some form of Social Networking presence.[35] and are part of a generational shift that could be changing norms.[36][37][further explanation needed] The social network Facebook progressed from U.S. college students to a 70% non-U.S. audience, but in 2009 estimated that only 20% of its members use privacy settings.[38] In 2010 (six years after co-founding the company), Mark Zuckerberg wrote, "we will add privacy controls that are much simpler to use".[39]
Privacy representatives from 60 countries have resolved to ask for laws to complement industry self-regulation, for education for children and other minors who use the Web, and for default protections for users of social networks.[40] They also believe data protection for personally identifiable information benefits business more than the sale of that information.[40] Users can opt-in to features in browsers to clear their personal histories locally and block some cookies and advertising networks[41] but they are still tracked in websites' server logs, and in particular web beacons.[42] Berners-Lee and colleagues see hope in accountability and appropriate use achieved by extending the Web's architecture to policy awareness, perhaps with audit logging, reasoners and appliances.[43]
In exchange for providing free content, vendors hire advertisers who spy on Web users and base their business model on tracking them.[44] Since 2009, they buy and sell consumer data on exchanges (lacking a few details that could make it possible to de-anonymize, or identify an individual).[44][45] Hundreds of millions of times per day, Lotame Solutions captures what users are typing in real time, and sends that text to OpenAmplify who then tries to determine, to quote a writer at The Wall Street Journal, "what topics are being discussed, how the author feels about those topics, and what the person is going to do about them".[46][47]
Microsoft backed away in 2008 from its plans for strong privacy features in Internet Explorer,[48] leaving its users (50% of the world's Web users) open to advertisers who may make assumptions about them based on only one click when they visit a website.[49] Among services paid for by advertising, Yahoo! could collect the most data about users of commercial websites, about 2,500 bits of information per month about each typical user of its site and its affiliated advertising network sites. Yahoo! was followed by MySpace with about half that potential and then by AOL–TimeWarner, Google, Facebook, Microsoft, and eBay.[50]
Security
The Web has become criminals' preferred pathway for spreading malware. Cybercrime carried out on the Web can include identity theft, fraud, espionage and intelligence gathering.[51] Web-based vulnerabilities now outnumber traditional computer security concerns,[52][53] and as measured by Google, about one in ten web pages may contain malicious code.[54] Most Web-based attacks take place on legitimate websites, and most, as measured by Sophos, are hosted in the United States, China and Russia.[55] The most common of all malware threats is SQL injection attacks against websites.[56] Through HTML and URIs the Web was vulnerable to attacks like cross-site scripting (XSS) that came with the introduction of JavaScript[57] and were exacerbated to some degree by Web 2.0 and Ajax web design that favors the use of scripts.[58] Today by one estimate, 70% of all websites are open to XSS attacks on their users.[59]
Proposed solutions vary to extremes. Large security vendors like McAfee already design governance and compliance suites to meet post-9/11 regulations,[60] and some, like Finjan have recommended active real-time inspection of code and all content regardless of its source.[51] Some have argued that for enterprise to see security as a business opportunity rather than a cost center,[61] "ubiquitous, always-on digital rights management" enforced in the infrastructure by a handful of organizations must replace the hundreds of companies that today secure data and networks.[62] Jonathan Zittrain has said users sharing responsibility for computing safety is far preferable to locking down the Internet.[63]
Standards
Main article: Web standardsMany formal standards and other technical specifications and software define the operation of different aspects of the World Wide Web, the Internet, and computer information exchange. Many of the documents are the work of the World Wide Web Consortium (W3C), headed by Berners-Lee, but some are produced by the Internet Engineering Task Force (IETF) and other organizations.
Usually, when web standards are discussed, the following publications are seen as foundational:
- Recommendations for markup languages, especially HTML and XHTML, from the W3C. These define the structure and interpretation of hypertext documents.
- Recommendations for stylesheets, especially CSS, from the W3C.
- Standards for ECMAScript (usually in the form of JavaScript), from Ecma International.
- Recommendations for the Document Object Model, from W3C.
Additional publications provide definitions of other essential technologies for the World Wide Web, including, but not limited to, the following:
- Uniform Resource Identifier (URI), which is a universal system for referencing resources on the Internet, such as hypertext documents and images. URIs, often called URLs, are defined by the IETF's RFC 3986 / STD 66: Uniform Resource Identifier (URI): Generic Syntax, as well as its predecessors and numerous URI scheme-defining RFCs;
- HyperText Transfer Protocol (HTTP), especially as defined by RFC 2616: HTTP/1.1 and RFC 2617: HTTP Authentication, which specify how the browser and server authenticate each other.
Accessibility
Main article: Web accessibilityAccess to the Web is for everyone regardless of disability—including visual, auditory, physical, speech, cognitive, and neurological. Accessibility features also help others with temporary disabilities like a broken arm or the aging population as their abilities change.[64] The Web is used for receiving information as well as providing information and interacting with society, making it essential that the Web be accessible in order to provide equal access and equal opportunity to people with disabilities.[65] Tim Berners-Lee once noted, "The power of the Web is in its universality. Access by everyone regardless of disability is an essential aspect."[64] Many countries regulate web accessibility as a requirement for websites.[66] International cooperation in the W3C Web Accessibility Initiative led to simple guidelines that web content authors as well as software developers can use to make the Web accessible to persons who may or may not be using assistive technology.[64][67]
Internationalization
The W3C Internationalization Activity assures that web technology will work in all languages, scripts, and cultures.[68] Beginning in 2004 or 2005, Unicode gained ground and eventually in December 2007 surpassed both ASCII and Western European as the Web's most frequently used character encoding.[69] Originally RFC 3986 allowed resources to be identified by URI in a subset of US-ASCII. RFC 3987 allows more characters—any character in the Universal Character Set—and now a resource can be identified by IRI in any language.[70]
Statistics
Between 2005 and 2010, the number of Web users doubled, and was expected to surpass two billion in 2010.[71] According to a 2001 study, there were a massive number, over 550 billion, of documents on the Web, mostly in the invisible Web, or Deep Web.[72] A 2002 survey of 2,024 million Web pages[73] determined that by far the most Web content was in English: 56.4%; next were pages in German (7.7%), French (5.6%), and Japanese (4.9%). A more recent study, which used Web searches in 75 different languages to sample the Web, determined that there were over 11.5 billion Web pages in the publicly indexable Web as of the end of January 2005.[74] As of March 2009[update], the indexable web contains at least 25.21 billion pages.[75] On July 25, 2008, Google software engineers Jesse Alpert and Nissan Hajaj announced that Google Search had discovered one trillion unique URLs.[76] As of May 2009[update], over 109.5 million domains operated.[77][not in citation given] Of these 74% were commercial or other sites operating in the
.comgeneric top-level domain.[77]Statistics measuring a website's popularity are usually based either on the number of page views or on associated server 'hits' (file requests) that it receives.
Speed issues
Frustration over congestion issues in the Internet infrastructure and the high latency that results in slow browsing has led to a pejorative name for the World Wide Web: the World Wide Wait.[78] Speeding up the Internet is an ongoing discussion over the use of peering and QoS technologies. Other solutions to reduce the congestion can be found at W3C.[79] Guidelines for Web response times are:[80]
- 0.1 second (one tenth of a second). Ideal response time. The user does not sense any interruption.
- 1 second. Highest acceptable response time. Download times above 1 second interrupt the user experience.
- 10 seconds. Unacceptable response time. The user experience is interrupted and the user is likely to leave the site or system.
Caching
If a user revisits a Web page after only a short interval, the page data may not need to be re-obtained from the source Web server. Almost all web browsers cache recently obtained data, usually on the local hard drive. HTTP requests sent by a browser will usually ask only for data that has changed since the last download. If the locally cached data are still current, it will be reused. Caching helps reduce the amount of Web traffic on the Internet. The decision about expiration is made independently for each downloaded file, whether image, stylesheet, JavaScript, HTML, or whatever other content the site may provide. Thus even on sites with highly dynamic content, many of the basic resources need to be refreshed only occasionally. Web site designers find it worthwhile to collate resources such as CSS data and JavaScript into a few site-wide files so that they can be cached efficiently. This helps reduce page download times and lowers demands on the Web server.
There are other components of the Internet that can cache Web content. Corporate and academic firewalls often cache Web resources requested by one user for the benefit of all. (See also Caching proxy server.) Some search engines also store cached content from websites. Apart from the facilities built into Web servers that can determine when files have been updated and so need to be re-sent, designers of dynamically generated Web pages can control the HTTP headers sent back to requesting users, so that transient or sensitive pages are not cached. Internet banking and news sites frequently use this facility. Data requested with an HTTP 'GET' is likely to be cached if other conditions are met; data obtained in response to a 'POST' is assumed to depend on the data that was POSTed and so is not cached.
See also
References
- ^ a b "Tim Berners Lee — Time 100 People of the Century". Time Magazine. http://www.time.com/time/magazine/article/0,9171,990627,00.html. Retrieved 17 May 2010. "He wove the World Wide Web and created a mass medium for the 21st century. The World Wide Web is Berners-Lee's alone. He designed it. He loosed it on the world. And he more than anyone else has fought to keep it open, nonproprietary and free. ."
- ^ "World Wide Web Consortium". http://www.w3.org/. "The World Wide Web Consortium (W3C)..."
- ^ a b c "Berners-Lee, Tim; Cailliau, Robert (November 12, 1990). "WorldWideWeb: Proposal for a hypertexts Project". http://w3.org/Proposal.html. Retrieved July 27, 2009.
- ^ Berners-Lee, Tim. "Pre-W3C Web and Internet Background". World Wide Web Consortium. http://w3.org/2004/Talks/w3c10-HowItAllStarted/?n=15. Retrieved April 21, 2009.
- ^ Wardrip-Fruin, Noah and Nick Montfort, ed (2003). The New Media Reader. Section 54. The MIT Press. ISBN 0-262-23227-8.
- ^ von Braun, Wernher (May 1970). "TV Broadcast Satellite". Popular Science: 65–66. http://www.popsci.com/archive-viewer?id=8QAAAAAAMBAJ&pg=66&query=a+c+clarke. Retrieved January 12, 2011.
- ^ Berners-Lee, Tim (March 1989). "Information Management: A Proposal". W3C. http://w3.org/History/1989/proposal.html. Retrieved July 27, 2009.
- ^ "Tim Berners-Lee's original World Wide Web browser". http://info.cern.ch/NextBrowser.html. "With recent phenomena like blogs and wikis, the web is beginning to develop the kind of collaborative nature that its inventor envisaged from the start."
- ^ "Tim Berners-Lee: client". W3.org. http://w3.org/People/Berners-Lee/WorldWideWeb. Retrieved July 27, 2009.
- ^ "First Web pages". W3.org. http://w3.org/History/19921103-hypertext/hypertext/WWW/TheProject.html. Retrieved July 27, 2009.
- ^ "Short summary of the World Wide Web project". Groups.google.com. August 6, 1991. http://groups.google.com/group/alt.hypertext/msg/395f282a67a1916c. Retrieved July 27, 2009.
- ^ Roads and Crossroads of Internet History by Gregory Gromov
- ^ "W3C timeline". http://w3.org/2005/01/timelines/timeline-2500x998.png. Retrieved March 30, 2010.
- ^ "About SPIRES". http://slac.stanford.edu/spires/about/. Retrieved March 30, 2010.
- ^ "The Early World Wide Web at SLAC". http://www.slac.stanford.edu/history/earlyweb/history.shtml.
- ^ "A Little History of the World Wide Web". http://www.w3.org/History.html.
- ^ "Inventor of the Week Archive: The World Wide Web". Massachusetts Institute of Technology: MIT School of Engineering. http://web.mit.edu/invent/iow/berners-lee.html. Retrieved July 23, 2009.
- ^ "Ten Years Public Domain for the Original Web Software". Tenyears-www.web.cern.ch. April 30, 2003. http://tenyears-www.web.cern.ch/tenyears-www/Welcome.html. Retrieved July 27, 2009.
- ^ "Mosaic Web Browser History — NCSA, Marc Andreessen, Eric Bina". Livinginternet.com. http://livinginternet.com/w/wi_mosaic.htm. Retrieved July 27, 2009.
- ^ "NCSA Mosaic — September 10, 1993 Demo". Totic.org. http://totic.org/nscp/demodoc/demo.html. Retrieved July 27, 2009.
- ^ "Vice President Al Gore's ENIAC Anniversary Speech". Cs.washington.edu. February 14, 1996. http://cs.washington.edu/homes/lazowska/faculty.lecture/innovation/gore.html. Retrieved July 27, 2009.
- ^ "Internet legal definition of Internet". West's Encyclopedia of American Law, edition 2. Free Online Law Dictionary. July 15, 2009. http://legal-dictionary.thefreedictionary.com/Internet. Retrieved November 25, 2008.
- ^ "WWW (World Wide Web) Definition". TechTerms. http://techterms.com/definition/www. Retrieved february 19 2010.
- ^ "The W3C Technology Stack". World Wide Web Consortium. http://www.w3.org/Consortium/technology. Retrieved April 21, 2009.
- ^ a b Hamilton, Naomi (July 31, 2008). "The A-Z of Programming Languages: JavaScript". Computerworld. IDG. http://computerworld.com.au/article/255293/-z_programming_languages_javascript. Retrieved May 12, 2009.
- ^ Buntin, Seth (23 September 2008). "jQuery Polling plugin". http://buntin.org/2008/sep/23/jquery-polling-plugin/. Retrieved 2009-08-22.
- ^ Berners-Lee, Tim. "Frequently asked questions by the Press". W3C. http://w3.org/People/Berners-Lee/FAQ.html. Retrieved July 27, 2009.
- ^ "automatically adding www.___.com". mozillaZine. May 16, 2003. http://forums.mozillazine.org/viewtopic.php?f=9&t=10980. Retrieved May 27, 2009.
- ^ Masnick, Mike (July 7, 2008). "Microsoft Patents Adding 'www.' And '.com' To Text". Techdirt. http://techdirt.com/articles/20080626/0203581527.shtml. Retrieved May 27, 2009.
- ^ "MDBG Chinese-English dictionary — Translate". http://us.mdbg.net/chindict/chindict.php?page=translate&trst=0&trqs=World+Wide+Web&trlang=&wddmtm=0. Retrieved July 27, 2009.
- ^ "Frequently asked questions by the Press — Tim BL". W3.org. http://w3.org/People/Berners-Lee/FAQ.html. Retrieved July 27, 2009.
- ^ "It's not your grandfather's Internet". Strategic Finance. 2010. http://findarticles.com/p/articles/mi_hb6421/is_4_92/ai_n56479358/.
- ^ Abelson, Hal; Ledeen, Ken; Lewis, Harry Lewis (April 14, 2008). "1–2". Blown to Bits: Your Life, Liberty, and Happiness After the Digital Explosion. Addison Wesley. ISBN 0-13-713559-9. http://bitsbook.com/. Retrieved November 6, 2008.
- ^ "Social Networking Explodes Worldwide as Sites Increase their Focus on Cultural Relevance" (Press release). comScore. August 12, 2008. http://comscore.com/press/release.asp?press=2396. Retrieved November 9, 2008.
- ^ Lenhart, Amanda; Madden, Mary (April 18, 2007). "Teens, Privacy & Online Social Networks" (PDF). Pew Internet & American Life Project. Archived from the original on 2008-03-06. http://web.archive.org/web/20080306031923/http://www.pewinternet.org/pdfs/PIP_Teens_Privacy_SNS_Report_Final.pdf. Retrieved November 9, 2008.
- ^ Schmidt, Eric (Google) (October 20, 2008). Eric Schmidt at Bloomberg on the Future of Technology. YouTube. Event occurs at 16:30. http://youtube.com/watch?v=rD_x9LW5QRg. Retrieved November 9, 2008.
- ^ Nussbaum, Emily (February 12, 2007). "Say Everything". New York (New York Media). http://nymag.com/news/features/27341/. Retrieved November 9, 2008.
- ^ Stone, Brad (March 28, 2009). "Is Facebook Growing Up Too Fast?". The New York Times. http://nytimes.com/2009/03/29/technology/internet/29face.html?pagewanted=all. and Lee Byron (Facebook) (March 28, 2009). "The Road to 200 Million". The New York Times. http://nytimes.com/imagepages/2009/03/29/business/29face.graf01.ready.html. Retrieved April 2, 2009.
- ^ Zuckerberg, Mark (May 24, 2010). "From Facebook, answering privacy concerns with new settings". The Washington Post. http://www.washingtonpost.com/wp-dyn/content/article/2010/05/23/AR2010052303828.html. Retrieved May 24, 2010.
- ^ a b "Protecting privacy in a borderless world" (PDF) (Press release). 30th International Conference of Data Protection and Privacy Commissioners, via Internet Archive. October 17, 2008. http://wayback.archive.org/web/*/http://www.privacyconference2008.org/pdf/press_final_en.pdf. Retrieved November 8, 2008.
- ^ Cooper, Alissa (October 2008). "Browser Privacy Features: A Work In Progress" (PDF). Center for Democracy and Technology. http://www.cdt.org/privacy/20081022_browser_priv.pdf. Retrieved November 8, 2008.
- ^ Joshua Gomez, Travis Pinnick, and Ashkan Soltani (June 1, 2009). "KnowPrivacy" (PDF). University of California, Berkeley, School of Information. pp. 8–9. http://www.knowprivacy.org/report/KnowPrivacy_Final_Report.pdf. Retrieved June 2, 2009.
- ^ Daniel J. Weitzner, Harold Abelson, Tim Berners-Lee, Joan Feigenbaum, James Hendler, Gerald Jay Sussman (June 13, 2007). "Information Accountability". MIT Computer Science and Artificial Intelligence Laboratory. hdl:1721.1/37600.
- ^ a b Angwin, Julia (July 30, 2010). "The Web's New Gold Mine: Your Secrets". The Wall Street Journal (Dow Jones). http://online.wsj.com/article/SB10001424052748703940904575395073512989404.html. Retrieved August 3, 2010.
- ^ Steel, Emily and Angwin, Julia (August 4, 2010). "On the Web's Cutting Edge, Anonymity in Name Only". The Wall Street Journal (Dow Jones). http://online.wsj.com/article/SB10001424052748703294904575385532109190198.html. Retrieved August 3, 2010.
- ^ Angwin, Julia and Valentino-DeVries, Jennifer (July 30, 2010). "Analyzing What You Have Typed". The Wall Street Journal (Dow Jones). http://blogs.wsj.com/digits/2010/07/30/analyzing-what-you-have-typed/. Retrieved August 3, 2010.
- ^ Valentino-Devries, Jennifer (July 31, 2010). "What They Know About You". The Wall Street Journal (Dow Jones). http://online.wsj.com/article/SB10001424052748703999304575399041849931612.html. Retrieved August 3, 2010.
- ^ Wingfield, Nick (August 2, 2010). "Microsoft Quashed Effort to Boost Online Privacy". The Wall Street Journal (Dow Jones). http://online.wsj.com/article/SB10001424052748703467304575383530439838568.html. Retrieved August 3, 2010.
- ^ Steel, Emily and Angwin, Julia (August 4, 2010). "One Smart Cookie". The Wall Street Journal (Dow Jones). http://online.wsj.com/article/SB10001424052748704017904575409021400239454.html. Retrieved August 3, 2010.
- ^ Story, Louise and comScore (March 10, 2008). "They Know More Than You Think" (JPEG). The New York Times. http://www.nytimes.com/imagepages/2008/03/10/technology/20080310_PRIVACY_GRAPHIC.html. in Story, Louise (March 10, 2008). "To Aim Ads, Web Is Keeping Closer Eye on You". The New York Times (The New York Times Company). http://www.nytimes.com/2008/03/10/technology/10privacy.html. Retrieved March 9, 2008.
- ^ a b Ben-Itzhak, Yuval (April 18, 2008). "Infosecurity 2008 – New defence strategy in battle against e-crime". ComputerWeekly (Reed Business Information). http://www.computerweekly.com/Articles/2008/04/18/230345/infosecurity-2008-new-defence-strategy-in-battle-against.htm. Retrieved April 20, 2008.
- ^ Christey, Steve and Martin, Robert A. (May 22, 2007). "Vulnerability Type Distributions in CVE (version 1.1)". MITRE Corporation. http://cwe.mitre.org/documents/vuln-trends/index.html. Retrieved June 7, 2008.
- ^ (PDF) Symantec Internet Security Threat Report: Trends for July–December 2007 (Executive Summary). XIII. Symantec Corp.. April 2008. pp. 1–2. http://eval.symantec.com/mktginfo/enterprise/white_papers/b-whitepaper_exec_summary_internet_security_threat_report_xiii_04-2008.en-us.pdf. Retrieved May 11, 2008.
- ^ "Google searches web's dark side". BBC News. May 11, 2007. http://news.bbc.co.uk/2/hi/technology/6645895.stm. Retrieved April 26, 2008.
- ^ "Security Threat Report" (PDF). Sophos. Q1 2008. http://www.sophos.com/sophos/docs/eng/marketing_material/sophos-threat-report-Q108.pdf. Retrieved April 24, 2008.
- ^ "Security threat report" (PDF). Sophos. July 2008. http://www.sophos.com/sophos/docs/eng/papers/sophos-security-report-jul08-srna.pdf. Retrieved August 24, 2008.
- ^ Fogie, Seth, Jeremiah Grossman, Robert Hansen, and Anton Rager (2007) (PDF). Cross Site Scripting Attacks: XSS Exploits and Defense. Syngress, Elsevier Science & Technology. pp. 68–69, 127. ISBN 1597491543. http://www.syngress.com/book_catalog//SAMPLE_1597491543.pdf. Retrieved June 6, 2008.[dead link]
- ^ O'Reilly, Tim (September 30, 2005). "What Is Web 2.0". O'Reilly Media. pp. 4–5. http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.html. Retrieved June 4, 2008. and AJAX web applications can introduce security vulnerabilities like "client-side security controls, increased attack surfaces, and new possibilities for Cross-Site Scripting (XSS)", in Ritchie, Paul (March 2007). "The security risks of AJAX/web 2.0 applications" (PDF). Infosecurity (Elsevier). Archived from the original on 2008-06-25. http://web.archive.org/web/20080625065122/http://www.infosecurity-magazine.com/research/Sep07_Ajax.pdf. Retrieved June 6, 2008. which cites Hayre, Jaswinder S. and Kelath, Jayasankar (June 22, 2006). "Ajax Security Basics". SecurityFocus. http://www.securityfocus.com/infocus/1868. Retrieved June 6, 2008.
- ^ Berinato, Scott (January 1, 2007). "Software Vulnerability Disclosure: The Chilling Effect". CSO (CXO Media): p. 7. Archived from the original on 2008-04-18. http://web.archive.org/web/20080418072230/http://www.csoonline.com/article/221113. Retrieved June 7, 2008.
- ^ Prince, Brian (April 9, 2008). "McAfee Governance, Risk and Compliance Business Unit". eWEEK (Ziff Davis Enterprise Holdings). http://www.eweek.com/c/a/Security/McAfee-Governance-Risk-and-Compliance-Business-Unit/. Retrieved April 25, 2008.
- ^ Preston, Rob (April 12, 2008). "Down To Business: It's Past Time To Elevate The Infosec Conversation". InformationWeek (United Business Media). http://www.informationweek.com/news/security/client/showArticle.jhtml?articleID=207100989. Retrieved April 25, 2008.
- ^ Claburn, Thomas (February 6, 2007). "RSA's Coviello Predicts Security Consolidation". InformationWeek (United Business Media). http://www.informationweek.com/news/security/showArticle.jhtml?articleID=197003826. Retrieved April 25, 2008.
- ^ Duffy Marsan, Carolyn (April 9, 2008). "How the iPhone is killing the 'Net". Network World (IDG). http://www.networkworld.com/news/2008/040908-zittrain.html. Retrieved April 17, 2008.
- ^ a b c "Web Accessibility Initiative (WAI)". World Wide Web Consortium. http://www.w3.org/WAI/l. Retrieved April 7, 2009.[dead link]
- ^ "Developing a Web Accessibility Business Case for Your Organization: Overview". World Wide Web Consortium. http://www.w3.org/WAI/bcase/Overview. Retrieved April 7, 2009.[dead link]
- ^ "Legal and Policy Factors in Developing a Web Accessibility Business Case for Your Organization". World Wide Web Consortium. http://www.w3.org/WAI/bcase/pol. Retrieved April 7, 2009.
- ^ "Web Content Accessibility Guidelines (WCAG) Overview". World Wide Web Consortium. http://www.w3.org/WAI/intro/wcag.php. Retrieved April 7, 2009.
- ^ "Internationalization (I18n) Activity". World Wide Web Consortium. http://www.w3.org/International/. Retrieved April 10, 2009.
- ^ Davis, Mark (April 5, 2008). "Moving to Unicode 5.1". Google. http://googleblog.blogspot.com/2008/05/moving-to-unicode-51.html. Retrieved April 10, 2009.
- ^ "World Wide Web Consortium Supports the IETF URI Standard and IRI Proposed Standard" (Press release). World Wide Web Consortium. January 26, 2005. http://www.w3.org/2004/11/uri-iri-pressrelease.html. Retrieved April 10, 2009.
- ^ Lynn, Jonathan (October 19, 2010). "Internet users to exceed 2 billion ...". Reuters. http://www.reuters.com/article/2010/10/19/us-telecoms-internet-idUSTRE69I24720101019. Retrieved Feb 9, 2011.
- ^ "The 'Deep' Web: Surfacing Hidden Value". Brightplanet.com. Archived from the original on 2008-04-04. http://web.archive.org/web/20080404044203/http://www.brightplanet.com/resources/details/deepweb.html. Retrieved July 27, 2009.
- ^ "Distribution of languages on the Internet". Netz-tipp.de. http://www.netz-tipp.de/languages.html. Retrieved July 27, 2009.
- ^ Alessio Signorini. "Indexable Web Size". Cs.uiowa.edu. http://www.cs.uiowa.edu/~asignori/web-size/. Retrieved July 27, 2009.
- ^ "The size of the World Wide Web". Worldwidewebsize.com. http://www.worldwidewebsize.com/. Retrieved July 27, 2009.
- ^ Alpert, Jesse; Hajaj, Nissan (July 25, 2008). "We knew the web was big...". The Official Google Blog. http://googleblog.blogspot.com/2008/07/we-knew-web-was-big.html.
- ^ a b "Domain Counts & Internet Statistics". Name Intelligence. http://www.domaintools.com/internet-statistics/. Retrieved May 17, 2009.
- ^ "World Wide Wait". TechEncyclopedia. United Business Media. http://www.techweb.com/encyclopedia/defineterm.jhtml?term=world+wide+wait. Retrieved April 10, 2009.
- ^ Khare, Rohit and Jacobs, Ian (1999). "W3C Recommendations Reduce 'World Wide Wait'". World Wide Web Consortium. http://www.w3.org/Protocols/NL-PerfNote.html. Retrieved April 10, 2009.
- ^ Nielsen, Jakob (from Miller 1968; Card et al. 1991) (1994). "5". Usability Engineering: Response Times: The Three Important Limits. Morgan Kaufmann. http://www.useit.com/papers/responsetime.html. Retrieved April 10, 2009.
Further reading
- Niels Brügger, ed. Web History (2010) 362 pages; Historical perspective on the World Wide Web, including issues of culture, content, and preservation.
- Fielding, R.; Gettys, J.; Mogul, J.; Frystyk, H.; Masinter, L.; Leach, P.; Berners-Lee, T. (June 1999). Hypertext Transfer Protocol — HTTP/1.1. Request For Comments 2616. Information Sciences Institute. ftp://ftp.isi.edu/in-notes/rfc2616.txt.
- Berners-Lee, Tim; Bray, Tim; Connolly, Dan; Cotton, Paul; Fielding, Roy; Jeckle, Mario; Lilley, Chris; Mendelsohn, Noah; Orchard, David; Walsh, Norman; Williams, Stuart (December 15, 2004). Architecture of the World Wide Web, Volume One. Version 20041215. W3C. http://www.w3.org/TR/webarch/.
- Polo, Luciano (2003). "World Wide Web Technology Architecture: A Conceptual Analysis". New Devices. http://newdevices.com/publicaciones/www/. Retrieved July 31, 2005.
- Skau, H.O. (March 1990). "The World Wide Web and Health Information". New Devices. http://newdevices.com/publicaciones/www/. Retrieved 1989.
External links
- Early archive of the first Web site
- Internet Statistics: Growth and Usage of the Web and the Internet
- Living Internet A comprehensive history of the Internet, including the World Wide Web.
- Web Design and Development at the Open Directory Project
- World Wide Web Consortium
- World Wide Web Size Daily estimated size of the World Wide Web.
- Antonio A. Casilli, Some Elements for a Sociology of Online Interactions
- The Erdős Webgraph Server offers weekly updated graph representation of a constantly increasing fraction of the WWW.
Categories:- World Wide Web
- English inventions
- Human–computer interaction
- Information Age
- 1989 introductions


{kind=link}
Wikimedia Foundation. 2010.