- Randomized algorithm
-
Part of a series on Probabilistic
data structuresBloom filter · Skip list Random trees Random binary tree · Treap
Rapidly-exploring random treeRelated Randomized algorithm Computer science Portal algorithm which employs a degree of randomness as part of its logic. The algorithm typically uses uniformly random bits as an auxiliary input to guide its behavior, in the hope of achieving good performance in the "average case" over all possible choices of random bits. Formally, the algorithm's performance will be a random variable determined by the random bits; thus either the running time, or the output (or both) are random variables. One has to distinguish between algorithms that use the random input to reduce the expected running time or memory usage, but always terminate with a correct result in a bounded amount of time, and probabilistic algorithms, which, depending on the random input, have a chance of producing an incorrect result (Monte Carlo algorithms) or fail to produce a result (Las Vegas algorithms) either by signalling a failure or failing to terminate.
In the second case, random performance and random output, the term "algorithm" for a procedure is somewhat questionable. In the case of random output, it is no longer formally effective.[1] However, in some cases, probabilistic algorithms are the only practical means of solving a problem.[2]
In common practice, randomized algorithms are approximated using a pseudorandom number generator in place of a true source of random bits; such an implementation may deviate from the expected theoretical behavior.
Contents
Motivation
As a motivating example, consider the problem of finding an ' a ' in an array of n elements.
Input: An array of n elements, in which half are ' a 's and the other half are ' b 's.
Output: Find an ' a ' in the array.
We give two versions of the algorithm, one Las Vegas algorithm and one Monte Carlo algorithm.
Las Vegas algorithm:
findingA_LV(array A, n) begin repeat Randomly select one element out of n elements. until 'a' is found end
This algorithm succeeds with probability 1. The running time is random (and arbitrarily large) but its expectation is upper-bounded by O(1). (See Big O notation)
Monte Carlo algorithm:
findingA_MC(array A, n, k) begin i=1 repeat Randomly select one element out of n elements. i = i + 1 until i=k end
If an ' a ' is found, the algorithm succeeds, else the algorithm fails. After k times execution, the probability of finding an ' a ' is:
Pr[find_'a'] = 1 − (1 / 2)k
This algorithm does not guarantee success, but the run time is fixed. The selection is executed exactly k times, therefore the runtime is O(k).
Randomized algorithms are particularly useful when faced with a malicious "adversary" or attacker who deliberately tries to feed a bad input to the algorithm (see worst-case complexity and competitive analysis (online algorithm)) such as in the Prisoner's dilemma. It is for this reason that randomness is ubiquitous in cryptography. In cryptographic applications, pseudo-random numbers cannot be used, since the adversary can predict them, making the algorithm effectively deterministic. Therefore either a source of truly random numbers or a cryptographically secure pseudo-random number generator is required. Another area in which randomness is inherent is quantum computing.
In the example above, the Las Vegas algorithm always outputs the correct answer, but its running time is a random variable. The Monte Carlo algorithm(related to the Monte Carlo method for simulation) completes in a fixed amount of time (as a function of the input size), but allow a small probability of error. Observe that any Las Vegas algorithm can be converted into a Monte Carlo algorithm (via Markov's inequality), by having it output an arbitrary, possibly incorrect answer if it fails to complete within a specified time. Conversely, if an efficient verification procedure exists to check whether an answer is correct, then a Monte Carlo algorithm can be converted into a Las Vegas algorithm by running the Monte Carlo algorithm repeatedly till a correct answer is obtained.
Computational complexity
Computational complexity theory models randomized algorithms as probabilistic Turing machines. Both Las Vegas and Monte Carlo algorithms are considered, and several complexity classes are studied. The most basic randomized complexity class is RP, which is the class of decision problems for which there is an efficient (polynomial time) randomized algorithm (or probabilistic Turing machine) which recognizes NO-instances with absolute certainty and recognizes YES-instances with a probability of at least 1/2. The complement class for RP is co-RP. Problem classes having (possibly nonterminating) algorithms with polynomial time average case running time whose output is always correct are said to be in ZPP.
The class of problems for which both YES and NO-instances are allowed to be identified with some error is called BPP. This class acts as the randomized equivalent of P, i.e. BPP represents the class of efficient randomized algorithms.
History
Historically, the first randomized algorithm was a method developed by Michael O. Rabin for the closest pair problem in computational geometry. The study of randomized algorithms was spurred by the 1977 discovery of a randomized primality test (i.e., determining the primality of a number) by Robert M. Solovay and Volker Strassen. Soon afterwards Michael O. Rabin demonstrated that the 1976 Miller's primality test can be turned into a randomized algorithm. At that time, no practical deterministic algorithm for primality was known.
The Miller-Rabin primality test relies on a binary relation between two positive integers k and n that can be expressed by saying that k "is a witness to the compositeness of" n. It can be shown that
- If there is a witness to the compositeness of n, then n is composite (i.e., n is not prime), and
- If n is composite then at least three-fourths of the natural numbers less than n are witnesses to its compositeness, and
- There is a fast algorithm that, given k and n, ascertains whether k is a witness to the compositeness of n.
Observe that this implies that the primality problem is in Co-RP.
If one randomly chooses 100 numbers less than a composite number n, then the probability of failing to find such a "witness" is (1/4)100 so that for most practical purposes, this is a good primality test. If n is big, there may be no other test that is practical. The probability of error can be reduced to an arbitrary degree by performing enough independent tests.
Therefore, in practice, there is no penalty associated with accepting a small probability of error, since with a little care the probability of error can be made astronomically small. Indeed, even though a deterministic polynomial-time primality test has since been found (see AKS primality test), it has not replaced the older probabilistic tests in cryptographic software nor is it expected to do so for the foreseeable future.
Applications
Quicksort
Quicksort is a familiar, commonly-used algorithm in which randomness can be useful. Any deterministic version of this algorithm requires O(n2) time to sort n numbers for some well-defined class of degenerate inputs (such as an already sorted array), with the specific class of inputs that generate this behavior defined by the protocol for pivot selection. However, if the algorithm selects pivot elements uniformly at random, it has a provably high probability of finishing in O(n log n) time regardless of the characteristics of the input.
Randomized incremental constructions in geometry
In computational geometry, a standard technique to build a structure like a convex hull or Delaunay Triangulation is to randomly permute the input points and then insert them one by one into the existing structure. The randomization ensures that the expected number of changes to the structure caused by an insertion is small, and so the expected running time of the algorithm can be upper bounded. This technique is known as randomized incremental construction.[3]
Verifying matrix multiplication
Input: Matrix A ∈ Rm × p, B ∈ Rp × n, and C ∈ Rm × n.
Output: True if C = A · B; false if C ≠ A · B
We give a Monte Carlo algorithm to solve the problem.[4]
begin i=1 repeat Choose r=(r1,...,rn) ∈ {0,1}n at random. Compute C · r and A · (B · r) if C · r ≠ A · (B · r) return FALSE endif i = i + 1 until i=k return TRUE end
The running time of the algorithm is O(kn2).
Theorem: The algorithm is correct with probability at least
 .
.We will prove that if
 then
then ![Pr[A \cdot B \cdot r=C \cdot r]\leq 1/2](d/1cd1132491846034b9a37471d21a3ef8.png) .
.If
, by definition we have  . Without loss of generality, we assume that
. Without loss of generality, we assume that  .
.On the other hand,
![Pr[A \cdot B \cdot r=C \cdot r] = Pr[(A \cdot B-C) \cdot r=0] = Pr[D \cdot r=0]](1/e11e9f14151083b2d3bd5c3a1d7a04c9.png) .
.If
 , then the first entry of
, then the first entry of  is 0, that is
is 0, that is
Since
, we can solve for r1:
If we fix all rj except r1, the equality holds for at most one of the two choices for
 . Therefore,
. Therefore,![Pr[ABr=Cr]\leq 1/2](5/565d0fd1976bc8fea244b526b9eae9b7.png) .
.We run the loop for k times. If
 , the algorithm is always correct; if
, the algorithm is always correct; if  , the probability of getting the correct answer is at least .
, the probability of getting the correct answer is at least .Min cut
Input: A graph G(V,E)
Output: A cut partitioning the vertices into L and R, with the minimum number of edges between L and R.
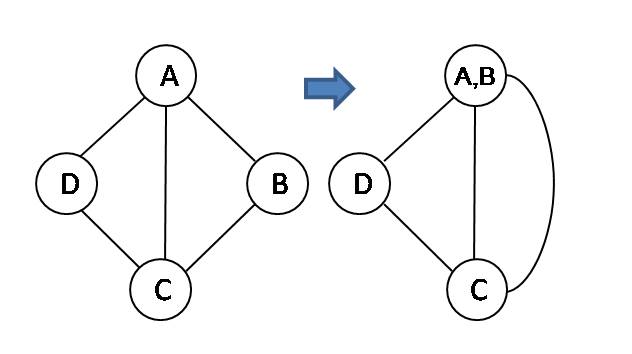
Recall that the contraction of two nodes, u and v, in a (multi-)graph yields a new node u ' with edges that are the union of the edges incident on either u or v, except from any edge(s) connecting u and v. Figure 1 gives an example of contraction of vertex A and B. After contraction, the resulting graph may have parallel edges, but contains no self loops.
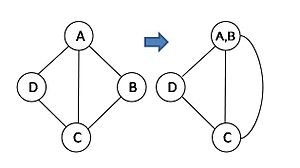 Figure 1: Contraction of vertex A and B
Figure 1: Contraction of vertex A and B
Karger's [5] basic algorithm:
begin i=1 repeat repeat Take a random edge (u,v)∈ E in G replace u and v with the contraction u' until only 2 nodes remain obtain the corresponding cut result Ci i=i+1 until i=m output the minimum cut among C1,C2,...,Cm. end
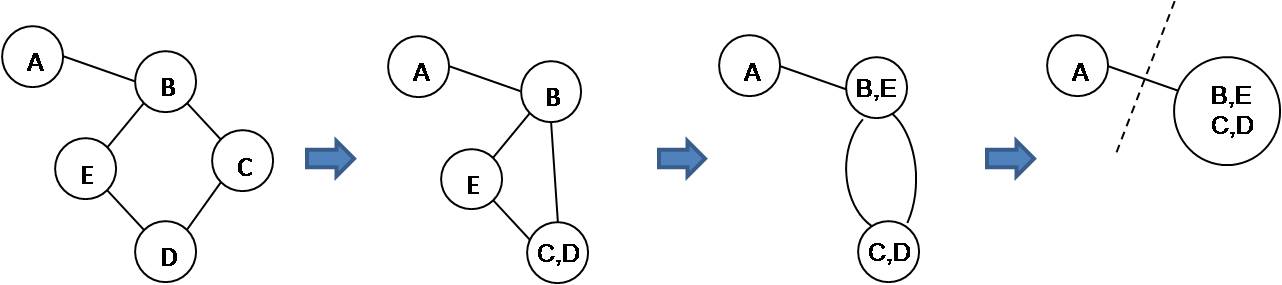
In each execution of the outer loop, the algorithm repeats the inner loop until only 2 nodes remain, the corresponding cut is obtained. The run time of one execution is O(n), and n denotes the number of vertices. After m times executions of the outer loop, we output the minimum cut among all the results. The figure 2 gives an example of one execution of the algorithm. After execution, we get a cut of size 1.
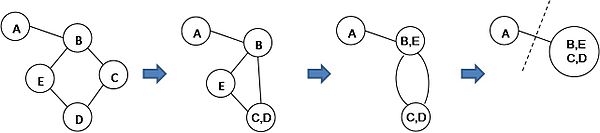 Figure 2: Example of one execution
Figure 2: Example of one executionLemma 1: Let k be the min cut size, and let C={e1,e2,...,ek} be the min cut. If, during iteration i, no edge e ∈ C is selected for contraction, then Ci=C.
Proof: If G is not connected, then G can be partitioned into L and R without any edge between them. So the min cut in a disconnected graph is 0. Now, assume G is connected. Let V=L∪ R be the partition of V induced by C : C={ {u,v} ∈ E : u ∈ L,v ∈ R } (well-defined since G is connected). Consider an edge {u,v} of C. Initially, u,v are distinct vertices. As long as we pick an edge f ≠ e, u and v do not get merged. Thus, at the end of the algorithm, we have two compound nodes covering the entire graph, one consisting of the vertices of L and the other consisting of the vertices of R. As in figure 2, the size of min cut is 1, and C={(A,B)}. If we don't select (A,B) for contraction, we can get the min cut.
Lemma 2: If G is a multigraph with p vertices and whose min cut has size k, then G has at least pk/2 edges.
Proof: Because the min cut is k, every vertex v must satisfy degree(v)≥ k. Therefore, the sum of the degree is at least pk. But it is well known that the sum of vertex degrees equals 2|E|. The lemma follows.
Analysis of algorithm
The probability that the algorithm succeeds is 1- the probability that all attempts fail. By independence, the probability that all attempts fail is

By lemma 1, the probability that Ci=C is the probability that no edge of C is selected during iteration i. Consider the inner loop and let Gj denote the graph after j edge contractions, where j∈{0,1,...,n-3}. Gj has n-j vertices. We use the chain rule of conditional possibilities. The probability that the edge chosen at iteration j is not in C, given that no edge of C has been chosen before, is
 . Note that Gj still has min cut of size k, so by Lemma 2, it still has at least
. Note that Gj still has min cut of size k, so by Lemma 2, it still has at least  edges.
edges.Thus,
 .
.So by the chain rule, the probability of finding the min cut C is
![Pr[C_i=C] \geq (\frac{n-2}{n})(\frac{n-3}{n-1})(\frac{n-4}{n-2})\ldots(\frac{3}{5})(\frac{2}{4})(\frac{1}{3}).](f/4ff9d0d607a15728ee4f750435282204.png)
Cancellation gives
![Pr[C_i=C]\geq \frac{2}{n(n-1)}](c/60c19bf4d7fd6cff85d83bc2baf5a35c.png) . Thus the probability that the algorithm succeeds is at least
. Thus the probability that the algorithm succeeds is at least  . For
. For  , this is equivalent to
, this is equivalent to  . The algorithm finds the min cut with probability , in time O(mn) = O(n3logn).
. The algorithm finds the min cut with probability , in time O(mn) = O(n3logn).Derandomization
Randomness can be viewed as a resource, like space and time. Derandomization is then the process of removing randomness (or using as little of it as possible). From the viewpoint of computational complexity, derandomizing an efficient randomized algorithm is the question, is P = BPP ?
There are also specific methods that can be employed to derandomize particular randomized algorithms:
- the method of conditional probabilities, and its generalization, pessimistic estimators
- discrepancy theory (which is used to derandomize geometric algorithms)
- the exploitation of limited independence in the random variables used by the algorithm, such as the pairwise independence used in universal hashing
- the use of expander graphs (or dispersers in general) to amplify a limited amount of initial randomness (this last approach is also referred to as generating pseudorandom bits from a random source, and leads to the related topic of pseudorandomness)
Where randomness helps
When the model of computation is restricted to Turing machines, it is currently an open question whether the ability to make random choices allows some problems to be solved in polynomial time that cannot be solved in polynomial time without this ability; this is the question of whether P = BPP. However, in other contexts, there are specific examples of problems where randomization yields strict improvements.
- Based on the initial motivating example: given an exponentially-long string of 2k characters, half a's and half b's, a random access machine requires at least 2k-1 lookups in the worst-case to find the index of an a; if it is permitted to make random choices, it can solve this problem in an expected polynomial number of lookups.
- In communication complexity, the equality of two strings can be verified using log n bits of communication with a randomized protocol. Any deterministic protocol requires Θ(n) bits.
- The volume of a convex body can be estimated by a randomized algorithm to arbitrary precision in polynomial time.[6] Bárány and Füredi showed that no deterministic algorithm can do the same.[7] This is true unconditionally, i.e. without relying on any complexity-theoretic assumptions.
- A more complexity-theoretic example of a place where randomness appears to help is the class IP. IP consists of all languages that can be accepted (with high probability) by a polynomially long interaction between an all-powerful prover and a verifier that implements a BPP algorithm. IP = PSPACE.[8] However, if it is required that the verifier be deterministic, then IP = NP.
- In a Chemical Reaction Network (a finite set of reactions like A+B → 2C + D operating on a finite number of molecules), the ability to ever reach a given target state from an initial state is decidable, while even approximating the probability of ever reaching a given target state (using the standard concentration-based probability for which reaction will occur next) is undecidable. More specifically, a Turing machine can be simulated with arbitrarily high probability of running correctly for all time, only if a random CRN is used. With a simple nondeterministic CRN (any possible reaction can happen next), the computational power is limited to primitive recursive functions.
See also
Notes
- ^ "Probabilistic algorithms should not be mistaken with methods (which I refuse to call algorithms), which produce a result which has a high probability of being correct. It is essential that an algorithm produces correct results (discounting human or computer errors), even if this happens after a very long time." Henri Cohen (2000). A Course in Computational Algebraic Number Theory. Springer-Verlag, p. 2.
- ^ "In testing primality of very large numbers chosen at random, the chance of stumbling upon a value that fools the Fermat test is less than the chance that cosmic radiation will cause the computer to make an error in carrying out a 'correct' algorithm. Considering an algorithm to be inadequate for the first reason but not for the second illustrates the difference between mathematics and engineering." Hal Abelson and Gerald J. Sussman (1996). Structure and Interpretation of Computer Programs. MIT Press, section 1.2.
- ^ Seidel R. Backwards Analysis of Randomized Geometric Algorithms.
- ^ Michael Mitzenmacher, Eli Upfal. Probability and Computing:Randomized Algorithms and Probabilistic Analysis, April 2005. Cambridge University Press
- ^ A. A. Tsay, W. S. Lovejoy, David R. Karger, Random Sampling in Cut, Flow, and Network Design Problems, Mathematics of Operations Research, 24(2):383-413, 1999.
- ^ Dyer, M.; Frieze, A.; Kannan, R. (1991), "A random polynomial-time algorithm for approximating the volume of convex bodies", Journal of the ACM 38 (1): 1–17, doi:10.1145/102782.102783
- ^ Füredi, Z.; Bárány, I. (1986), "Computing the volume is difficult", Proc. 18th ACM Symposium on Theory of Computing (Berkeley, California, May 28–30, 1986), New York, NY: ACM, pp. 442–447, doi:10.1145/12130.12176, ISBN 0897911938
- ^ Shamir, A. (1992), "IP = PSPACE", Journal of the ACM 39 (4): 869–877, doi:10.1145/146585.146609
References
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 1990. ISBN 0-262-03293-7. Chapter 5: Probabilistic Analysis and Randomized Algorithms, pp. 91–122.
- Jon Kleinberg and Éva Tardos. Algorithm Design. Chapter 13: "Randomized algorithms".
- Don Fallis. 2000. "The Reliability of Randomized Algorithms." British Journal for the Philosophy of Science 51:255-71.
- M. Mitzenmacher and E. Upfal. Probability and Computing : Randomized Algorithms and Probabilistic Analysis. Cambridge University Press, New York (NY), 2005.
- Rajeev Motwani and P. Raghavan. Randomized Algorithms. Cambridge University Press, New York (NY), 1995.
- Rajeev Motwani and P. Raghavan. Randomized Algorithms. A survey on Randomized Algorithms.
- Christos Papadimitriou (1993), Computational Complexity (1st ed.), Addison Wesley, ISBN 0-201-53082-1 Chapter 11: Randomized computation, pp. 241–278.
- M. O. Rabin. (1980), "Probabilistic Algorithm for Testing Primality." Journal of Number Theory 12:128-38.
- A. A. Tsay, W. S. Lovejoy, David R. Karger, Random Sampling in Cut, Flow, and Network Design Problems, Mathematics of Operations Research, 24(2):383-413, 1999.
Categories:- Randomized algorithms
- Stochastic algorithms
- Analysis of algorithms
- Probabilistic complexity theory
Wikimedia Foundation. 2010.
Look at other dictionaries:
randomized algorithm — noun Any algorithm that uses randomness as part of its logic. Syn: probabilistic algorithm … Wiktionary
Algorithm — Flow chart of an algorithm (Euclid s algorithm) for calculating the greatest common divisor (g.c.d.) of two numbers a and b in locations named A and B. The algorithm proceeds by successive subtractions in two loops: IF the test B ≤ A yields yes… … Wikipedia
Monte Carlo algorithm — In computing, a Monte Carlo algorithm is a randomized algorithm whose running time is deterministic, but whose output may be incorrect with a certain (typically small) probability. The related class of Las Vegas algorithms is also randomized, but … Wikipedia
Adversary (online algorithm) — In computer science, an online algorithm measures its competitiveness against different adversary models. For deterministic algorithms, the adversary is the same, the adaptive offline adversary. For randomized online algorithms competitiveness… … Wikipedia
Sorting algorithm — In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most used orders are numerical order and lexicographical order. Efficient sorting is important for optimizing the use of other… … Wikipedia
In-place algorithm — In place redirects here. For execute in place file systems, see execute in place. In computer science, an in place algorithm (or in Latin in situ) is an algorithm which transforms input using a data structure with a small, constant amount of… … Wikipedia
Las Vegas algorithm — In computing, a Las Vegas algorithm is a randomized algorithm that never gives incorrect results; that is, it always produces the correct result or it informs about the failure. In other words, a Las Vegas algorithm does not gamble with the… … Wikipedia
Freivald's algorithm — is a randomized algorithm used to verify matrix multiplication. Given three n x n matrices A , B , and C , a general problem is to verify whether A x B = C . A naïve algorithm would compute the product A x B explicitly and compare term by term… … Wikipedia
Deutsch–Jozsa algorithm — The Deutsch–Jozsa algorithm is a quantum algorithm, proposed by David Deutsch and Richard Jozsa in 1992[1] with improvements by Richard Cleve, Artur Ekert, Chiara Macchiavello, and Michele Mosca in 1998.[2] Although it is of little practical use … Wikipedia
Deutsch-Jozsa algorithm — The Deutsch Jozsa algorithm is a quantum algorithm, proposed by David Deutsch and Richard Jozsa in 1992 with improvements by R. Cleve, A. Ekert, C. Macchiavello, and M. Mosca in 1998.cite journal author = David Deutsch and Richard Jozsa title =… … Wikipedia
Share the article and excerpts
Direct link
https://en-academic.com/dic.nsf/enwiki/275094 Do a right-click on the link above
and select “Copy Link”
Randomized algorithm
- Randomized algorithm
-
Part of a series on Probabilistic
data structuresBloom filter · Skip list Random trees Random binary tree · Treap
Rapidly-exploring random treeRelated Randomized algorithm Computer science Portal