- DNA-binding domain
-
A DNA-binding domain (DBD) is an independently folded protein domain that contains at least one motif that recognizes double- or single-stranded DNA. A DBD can recognize a specific DNA sequence (a recognition sequence) or have a general affinity to DNA.[1] Some DNA-binding domains may also include nucleic acids in their folded structure.
Contents
Function
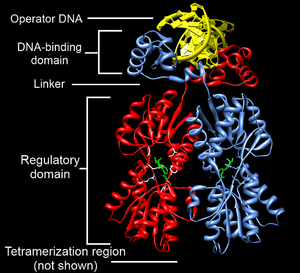 Example of a DNA-binding domain in the context of a protein. The N-terminal DNA-bindng domain (labeled) of Lac repressor is regulated by a C-terminal regulatory domain (labeled). The regulatory domain binds an allosteric effector molecule (green). The allosteric response of the protein is communicated from the regulatory domain to the DNA binding domain through the linker region. [2].
Example of a DNA-binding domain in the context of a protein. The N-terminal DNA-bindng domain (labeled) of Lac repressor is regulated by a C-terminal regulatory domain (labeled). The regulatory domain binds an allosteric effector molecule (green). The allosteric response of the protein is communicated from the regulatory domain to the DNA binding domain through the linker region. [2].
One or more DNA-binding domains are often part of a larger protein consisting of additional domains with differing function. The additional domains often regulate the activity of the DNA-binding domain. The function of DNA binding is either structural or involving transcription regulation, with the two roles sometimes overlapping.
DNA-binding domains with functions involving DNA structure have biological roles in the replication, repair, storage, and modification of DNA, such as methylation.
Many proteins involved in the regulation of gene expression contain DNA-binding domains. For example, proteins that regulate transcription by binding DNA are called transcription factors. The final output of most cellular signaling cascades is gene regulation.
The DBD interacts with the nucleotides of DNA in a DNA sequence-specific or non-sequence-specific manner, but even non-sequence-specific recognition involves some sort of molecular complementarity between protein and DNA. DNA recognition by the DBD can occur at the major or minor groove of DNA, or at the sugar-phosphate DNA backbone (see the structure of DNA). Each specific type of DNA recognition is tailored to the protein's function. For example, the DNA-cutting enzyme DNAse I cuts DNA almost randomly and so must bind to DNA in a non-sequence-specific manner. But, even so, DNAse I recognizes a certain 3-D DNA structure, yielding a somewhat specific DNA cleavage pattern that can be useful for studying DNA recognition by a technique called DNA footprinting.
Many DNA-binding domains must recognize specific DNA sequences, such as DBDs of transcription factors that activate specific genes, or those of enzymes that modify DNA at specific sites, like restriction enzymes and telomerase. The hydrogen bonding pattern in the DNA major groove is less degenerate than that of the DNA minor groove, providing a more attractive site for sequence-specific DNA recognition.
The specificity of DNA-binding proteins can be studied using many biochemical and biophysical techniques, such as gel electrophoresis, analytical ultracentrifugation, calorimetry, DNA mutation, protein structure mutation or modification, nuclear magnetic resonance, x-ray crystallography, surface plasmon resonance, electron paramagnetic resonance, cross-linking and Microscale Thermophoresis (MST).
Types of DNA-binding domains
Helix-turn-helix
Originally discovered in bacteria, the helix-turn-helix motif is commonly found in repressor proteins and is about 20 amino acids long. In eukaryotes, the homeodomain comprises 2 helices, one of which recognizes the DNA (aka recognition helix). They are common in proteins that regulate developmental processes (PROSITE HTH).
Zinc finger
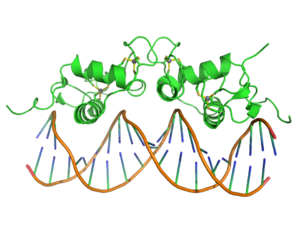 Crystallographic structure (PDB 1R4O) of a dimer of the zinc finger containing DBD of the glucocorticoid receptor (top) bound to DNA (bottom). Zinc atoms are represented by grey spheres and the coordinating cysteine sidechains are depicted as sticks.
Crystallographic structure (PDB 1R4O) of a dimer of the zinc finger containing DBD of the glucocorticoid receptor (top) bound to DNA (bottom). Zinc atoms are represented by grey spheres and the coordinating cysteine sidechains are depicted as sticks.The zinc finger This domain is generally between 23 and 28 amino acids long and is stabilized by coordinating Zinc ions with regularly spaced zinc-coordinating residues (either histidines or cysteines). The most common class of zinc finger (Cys2His2) coordinates a single zinc ion and consists of a recognition helix and a 2-strand beta-sheet.[3] In transcription factors these domains are often found in arrays (usually separated by short linker sequences) and adjacent fingers are spaced at 3 basepair intervals when bound to DNA.
Leucine zipper
The basic leucine zipper (bZIP) domain contains an alpha helix with a leucine at every 7th amino acid. If two such helices find one another, the leucines can interact as the teeth in a zipper, allowing dimerization of two proteins. When binding to the DNA, basic amino acid residues bind to the sugar-phosphate backbone while the helices sit in the major grooves. It regulates gene expression.
Winged helix
Consisting of about 110 amino acids, the winged helix (WH) domain has four helices and a two-strand beta-sheet.
Winged helix turn helix
The winged helix turn helix domain (wHTH) SCOP 46785 is typically 85-90 amino acids long. It is formed by a 3-helical bundle and a 4-strand beta-sheet (wing).
Helix-loop-helix
The Helix-loop-helix domain is found in some transcription factors and is characterized by two α helices connected by a loop. One helix is typically smaller and due to the flexibility of the loop, allows dimerization by folding and packing against another helix. The larger helix typically contains the DNA-binding regions.
HMG-box
HMG-box domains are found in high mobility group proteins which are involved in a variety of DNA-dependent processes like replication and transcription. The domain consists of three alpha helices separated by loops.
Unusual DNA binding domains
Immunoglobulin fold
The immunoglobulin domain (IPR013783) consists of a beta-sheet structure with large connecting loops, which serve to recognize either DNA major grooves or antigens. Usually found in immunoglobulin proteins, they are also present in Stat proteins of the cytokine pathway. This is likely because the cytokine pathway evolved relatively recently and has made use of systems that were already functional, rather than creating its own.
B3 domain
The B3 DBD (IPR003340, SCOP 117343) is found exclusively in transcription factors from higher plants and restriction endonucleases EcoRII and BfiI and typically consists of 100-120 residues. It includes seven beta sheets and two alpha helices, which form a DNA-binding pseudobarrel protein fold.
TAL effector DNA-binding domain
TAL effectors are found in bacterial plant pathogens and are involved in regulating the genes of the host plant in order to facilitate bacterial virulence, proliferation, and dissemination.[4] They contain a central region of tandem 33-35 residue repeats and each repeat region encodes a single DNA base in the TALE's binding site.[5] [6]
See also
- DNA-binding protein
- Nucleic acid simulations
References
- ^ Lilley, David M. J. (1995). DNA-protein: structural interactions. Oxford: IRL Press at Oxford University Press. ISBN 0-19-963453-X.
- ^ Swint-Kruse, L.; Matthews, K. S. (2009). "Allostery in the LacI/GalR Family: Variations on a Theme". Current Opinion in Microbiology 12 (2): 129–137. doi:10.1016/j.mib.2009.01.009. PMC 2688824. PMID 19269243. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2688824.
- ^ C.O. Pabo; E.Peisach; R.A. Grant (2001). "Design and Selection of Novel Cys2His2 Zinc Finger Proteins". Annu. Rev. Biochem. 70 (1): 313–40. doi:10.1146/annurev.biochem.70.1.313. PMID 11395410. http://arjournals.annualreviews.org/doi/abs/10.1146%2Fannurev.biochem.70.1.313.
- ^ Boch J, Bonas U (September 2010). "Xanthomonas AvrBs3 family-type III effectors: discovery and function". Annu Rev Phytopathol 48 (1): 419–36. doi:10.1146/annurev-phyto-080508-081936. PMID 19400638.
- ^ Moscou MJ, Bogdanove AJ (December 2009). "A simple cipher governs DNA recognition by TAL effectors". Science 326 (5959): 1501. Bibcode 2009Sci...326.1501M. doi:10.1126/science.1178817. PMID 19933106.
- ^ Boch J, Scholze H, Schornack S, et al. (December 2009). "Breaking the code of DNA binding specificity of TAL-type III effectors". Science 326 (5959): 1509–12. Bibcode 2009Sci...326.1509B. doi:10.1126/science.1178811. PMID 19933107.
External links
- DBD database of predicted transcription factors Kummerfeld SK, Teichmann SA. (2006). "DBD: a transcription factor prediction database". Nucleic Acids Res. 34 (Database issue): D74–81. doi:10.1093/nar/gkj131. PMC 1347493. PMID 16381970. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1347493. Uses a curated set of DNA-binding domains to predict transcription factors in all completely sequenced genomes
- Table of DNA-binding motifs
- MeSH DNA+Footprinting
- MeSH DNA-Binding+Proteins
- DNA-binding domains in PROSITE
Categories:- Proteins
- Molecular genetics

Wikimedia Foundation. 2010.