- Mojibake
-
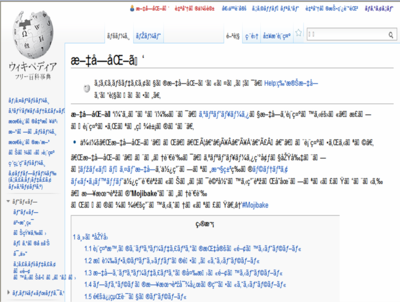 The UTF-8-encoded Japanese Wikipedia article for mojibake, as displayed in the Windows-1252 encoding.
The UTF-8-encoded Japanese Wikipedia article for mojibake, as displayed in the Windows-1252 encoding.
Mojibake (文字化け, IPA: [modʑibake], lit. "unintelligible sequence of characters"), from the Japanese 文字 (moji) "character" + 化け (bake) "change", is the occurrence of incorrect, unreadable characters shown when computer software fails to render text correctly according to its associated character encoding.
Contents
Causes
Mojibake is often caused when a character encoding is not correctly tagged in a document, or when a document is moved to a system with a different default encoding. Such incorrect display occurs when writing systems or character encodings are mistagged or "foreign" to the user's computer system: if a computer does not have the software required to process a foreign language's characters, it will attempt to process them in its default language encoding, usually resulting in gibberish. Messages transferred between different encodings of the same language can also have mojibake problems. Japanese language users, with several different encodings historically employed, encounter this problem relatively often. For example, the intended word "文字化け", encoded in UTF-8, is incorrectly displayed as "æ–‡å—化ã‘" in software that is configured to expect text in the Windows-1252 or ISO-8859-1 encodings, usually labelled Western.
A web browser may not be able to distinguish a page coded in EUC-JP and another in Shift-JIS if the coding scheme is not assigned explicitly using HTTP headers sent along with the documents, or using the HTML document's meta tags that are used to substitute for missing HTTP headers if the server cannot be configured to send the proper HTTP headers; see character encodings in HTML. Heuristics can be applied to guess at the character set, but these are not always successful.
In the mid 1990s, as this problem became common, several websites featured mojibake not as a problem to be tackled but simply for amusement. Words and even sentences were "deciphered" with meanings made up to deliver funny messages.[citation needed]
Mojibake can also occur between what appears to be the same encodings. For example, some software by Microsoft and Eudora for Windows purportedly encoded their output using the ISO-8859-1 encoding while, in reality, used Windows-1252 that contains extra printable characters in the C1 range. These characters were not displayed properly in software complying with the ISO standard; this especially affected software running under other operating systems (e.g. Unix).
Resolutions
Applications using UTF-8 as a default encoding may achieve a greater degree of interoperability due to its widespread use and backwards compatibility with US-ASCII.
The difficulty of resolving an instance of mojibake varies depending on the application within which it occurs and the causes of it. Two of the most common applications in which mojibake may occur are web browsers and word processors. Modern browsers and word processors often support a wide array of character encodings. Browsers often allow a user to change their rendering engine's encoding setting on the fly, while word processors allow the user to select the appropriate encoding when opening a file. It may take some trial and error for users to find the correct encoding.
The problem gets more complicated when it occurs in an application that normally does not support a wide range of character encoding, such as in a non-Unicode computer game. In this case, the user must change the operating system's encoding settings to match that of the game. However, changing the system-wide encoding settings can also cause Mojibake in pre-existing applications. In Windows XP or later, a user also has the option to use Microsoft AppLocale, an application that allows the changing of per-application locale settings. Even so, changing the operating system encoding settings is not possible on earlier operating systems such as Windows 98; to resolve this issue on earlier operating systems, a user would have to use third party font rendering applications.
Problems in specific languages
Commodore brand 8-bit computers used PETSCII encoding, particularly notable for inverting the upper and lower case compared to standard ASCII. PETSCII printers worked fine on other computers of the era, but flipped the case of all letters.
In German, Buchstabensalat (letter salad) and Krähenfüße (crow's feet) are common terms for this phenomenon.
Another affected language is Arabic (see below).
English
Mojibake in English texts generally occurs in punctuation, such as em dashes (—), en dashes (–), and curly quotes (“, ”), but rarely in character text, since most encodings agree with ASCII on the encoding of the English alphabet. For example, the pound sign "£" will appear as "£" if it was encoded by the sender as UTF-8 but interpreted by the recipient as CP1252 or ISO 8859-1. If iterated, this can lead to "£", "£", etc.
Japanese
In Japanese, the phenomenon is, as mentioned, called mojibake 文字化け. It is often encountered by non-Japanese when attempting to run software written for the Japanese market.
Central Europe
Users of Central and Eastern European languages can also be affected. Because most computers were not connected to any network during the mid- to late-1980s, there were different character encodings for every language with diacritical characters.
 Sender's handwritten krakozyabry corrected by a postal employee before delivery.
Sender's handwritten krakozyabry corrected by a postal employee before delivery. Mojibake on a webpage
Mojibake on a webpageRussian and other Cyrillic-based scripts
Mojibake may be called krakozyabry (кракозя́бры) in Russian, which was and remains complicated by several systems for encoding Cyrillic.[1] The Soviet Union and early Russian Federation developed KOI encodings (Kod Obmena Informatsiey, Код Обмена Информацией which translates to "Code for Information Exchange"). This began with Cyrillic-only 7-bit KOI7, based on ASCII but with Latin and some other characters replaced with Cyrillic letters. Then came 8-bit KOI8 encoding that is an ASCII extension which encodes Cyrillic letters only with high-bit set octets corresponding to 7-bit codes from KOI7. That's why KOI8 text, even Russian, remains partially readable after stripping the eighth bit, which was considered as a major advantage in the age of 8BITMIME-unaware email systems. Eventually KOI8 gained different flavors for Russian/Bulgarian (KOI8-R), Ukrainian (KOI8-U), Belarusian (KOI8-RU) and even Tajik (KOI8-T).
Meanwhile in the West, Code page 866 supported Ukrainian and Belarusian as well as Russian/Bulgarian in MS-DOS. For Microsoft Windows, Code Page 1251 added support for Serbian and other Slavic variants of Cyrillic. Most recently, Unicode includes special characters in Old Church Slavonic and non-Slavic minority languages in the Russian Federation. Now Unicode endeavors to replace the confusion with a system whereby any of the world's written languages either displays correctly or tells you which font you need to install, however Unicode still doesn't react transparently to legacy KOI and Code Page encodings.
Before Unicode, it was necessary to match text encoding with a font using the same encoding system. Failure to do this produced unreadable gibberish whose specific appearance varied depending on the exact combination of text encoding and font encoding. Accented vowels were symptomatic of trying to view any Cyrillic encoding with a font limited to the Latin alphabet. In general, Cyrillic gibberish was symptomatic of using the wrong Cyrillic font. Unicode text in an environment that doesn't accommodate Unicode[clarification needed] merely displays strings of question marks.
In Bulgarian, mojibake is often called maymunitsa (маймуница), meaning monkey's alphabet. In Serbian, it is called ђубре (đubre), meaning trash. Unlike the former USSR, South Slavs never used something like KOI8, and Code Page 1251 was the dominant Cyrillic encoding there before Unicode. Therefore these languages experienced fewer encoding incompatibility troubles than Russian. In 1980s, Bulgarian computers used its own MIK encoding, a bit similar (but incompatible with) CP866, though.
Polish
In Poland, every company selling early DOS computers created its own encoding, and simply reprogrammed the EPROMs of the video cards (typically CGA, EGA, or Hercules) with the needed glyphs for Polish — arbitrarily located without reference to where other computer sellers had placed them. Additionally, users of then-popular home computers (such as the Atari ST) invented their own encodings, incompatible with international standards (ISO 8859-2), vendor standards (IBM CP852, Windows CP1250) and locally agreed-upon PC/MS DOS standards (Mazovia). The situation began to improve when, after pressure from academic and user groups, ISO 8859-2 succeeded as the "Internet standard" with limited support of the dominant vendors' software (today largely replaced by Unicode). With the numerous problems caused by the variety of encodings, even today some users tend to refer to Polish diacritical characters as krzaczki[Ksha-Chkee] ("bushes").
Nordic languages and German
Among the Nordic languages, mojibake is not uncommon, but is more of an annoyance than a problem. Finnish and Swedish use the letters of the English alphabet and three more characters: å, ä and ö, and typically these three are the only ones that become corrupted. The situation is similar for Norwegian and Danish, except the three affected letters are æ, ø and å, and German, where the affected letters are ä, ö, ü and ß. In Swedish, Norwegian, Danish and German, vowels are rarely repeated, and it is usually obvious when one character gets corrupted, such as the second letter in "kärlek" (kärlek, "love"). This way, even though the reader has to guess among å, ä and ö, almost all texts remain perfectly readable. However, Finnish does have repeating vowels in words like "Hääyö" (hääyö, "wedding night"), which can sometimes render text very hard to read. Icelandic is worse off, with ten possibly confounding characters: á, ð, é, í, ó, ú, ý, þ, æ and ö.
Asian encodings
Another type of mojibake occurs when text is erroneously parsed in a multi-byte encoding, such as one of the east Asian encodings. With this kind of mojibake more than one (typically two) characters are corrupted at once, e.g. "k舐lek" (kärlek) in Swedish, where "är" is parsed as "舐". Compared to the above mojibake, this is harder to read, since letters unrelated to the problematic å, ä or ö are missing, and is especially problematic for short words starting with å, ä or ö such as "än" (which becomes "舅"). Since two letters are combined, the mojibake also seems more random (over 50 variants compared to the normal three, not counting the rarer capitals). In some rare cases, an entire text string which happens to include a pattern of particular word lengths, such as the sentence "Bush hid the facts", may be misinterpreted.
Countries of the former Yugoslavia
Slavic languages of former Yugoslavia (Croatian, Bosnian, Serbian) add to the basic Latin alphabet the letters š, đ, č, ć, ž, and their capital counterparts Š, Đ, Č, Ć, Ž. All of these letters are defined in Latin-2 and Windows-1250, while only some (š, Š, ž, Ž, Đ) exist in the usual OS-default Western, and are there because of some other languages.
Although even those that exist in extended Western ASCII (Windows-1252) are not immune to errors, the ones that don't are much more prone to errors. Thus, even nowadays, "šđčćž ŠĐČĆŽ" is all too often interpreted as "šðèæž ŠÐÈÆŽ", making the users wonder where ð, è, æ, È, Æ are used.
When confined to basic ASCII (most user names, for example), common replacements are: š→s, đ→dj, č→c, ć→c, ž→z (capital forms analogously, with Đ→Dj or Đ→DJ depending on word case). All of these replacements introduce ambiguities, so reconstructing the original from such a form is usually done manually if required.
Importance of Windows-1252 encoding is high because English versions of operating systems are most widespread, not the localized ones. The reasons for this are
- Relatively small and fragmented market, increasing price of high quality localization.
- High degree of software piracy (in turn caused by high price of software compared to income), thus discouraging localization efforts.
- People prefer English version of OS and other software.
The drive of differentiating Croatian from Serbian, Bosnian from Croatian and Serbian, and now even Montenegrin (a Serbian dialect that was dominant in former Yugoslavia) from the other three creates many problems. There are many different localizations, using different standards, and of different quality. There are no common translations for vast computer terminology originating in English. In the end, people use adopted English words (kompjuter-computer, kompajlirati-compile, etc.), and if they are unaccustomed to the translated terms may not understand what some option in a menu is supposed to do based on the translated phrase. Therefore, the people who understand English, as well as those who are accustomed to English terminology (which are most, because English terminology is also mostly taught in schools due to these problems) regularly choose the original English versions of non-specialist software.
When Cyrillic script is used (for Macedonian and partially Serbian language), the problem indeed is similar to other Cyrillic-based scripts.
Newer versions of English Windows allow ANSI codepage to be changed (older versions like Win95 require special English versions with this support), but this setting can and often were incorrectly set (for example, Windows 98/Me can be set to most non-RTL SBCS codepages including 1250, but only at install time).
Hungarian
Hungarian is another affected language, which uses the 26 basic English characters, plus the accented forms á, é, í, ó, ú, ö, ü (all present in the Latin-1 character set), plus the 2 characters ő and ű, which are not in Latin-1. These 2 characters can be correctly encoded in Latin-2, Windows-1250 and Unicode. Before Unicode became common in e-mail clients, e-mails containing Hungarian text often had the letters ő and ű corrupted, sometimes to the point of unrecognizability. It is common to respond to an e-mail rendered unreadable by character mangling (referred to as "betűszemét", meaning "garbage lettering") with the phrase "Árvíztűrő tükörfúrógép", a nonsense phrase (literally "Flood-resistant mirror-drilling machine") containing all accented characters used in Hungarian.
Indic text
A similar effect can occur in Indic text, even if the character set used is properly recognized by the application. This is because, in many Indic scripts, the rules by which individual letter symbols combine to create symbols for syllables may not be properly understood by a computer missing the appropriate software, even if the glyphs for the individual letter forms are available.
A particularly notable example of this is the old Wikipedia logo, which attempts to show the character analogous to "w" or "wi" (the first letter or syllable of "Wikipedia") on each of many puzzle pieces. Instead, the puzzle piece meant to bear the Devanagari character for "wi" used to show a somewhat nonsensical scribble with a dangling line at the end, easily recognizable as mojibake generated by a computer not configured to display Indic text. That this occurred in the venerable front-page logo and has never been corrected over many years has been seen as humorously emblematic of Wikipedia's alleged accuracy and reliability problems.[2] The recently redesigned logo has fixed these errors.
Some Indic and Indic-derived scripts, most notably Lao, were not officially supported by Windows XP until the release of Vista.[3] However, various sites have made free-to-download fonts.
Spanish
Spanish is another affected language. It is known as deformación (literally deformation). Its problems with Mojibake are similar to Nordic languages. Spanish uses all 26 Latin letters, ñ, acute accents on the five vowels (á, é, í, ó, ú), and rarely ü. Ñ and the accented vowels are regularly corrupted, since they are not available in ASCII.
Example
Output encoding Setting in browser Result Arabic example: الإعلان العالمى لحقوق الإنسان UTF-8 ISO 8859-1 الإعلان العالمى Ù„Øقوق الإنسان KOI8-R О╩©ь╖ы└ь╔ь╧ы└ь╖ы├ ь╖ы└ь╧ь╖ы└ы┘ы┴ ы└ь╜ы┌ы┬ы┌ ь╖ы└ь╔ы├ьЁь╖ы├ ISO 8859-5 яЛПиЇй�иЅиЙй�иЇй� иЇй�иЙиЇй�й�й� й�ий�й�й� иЇй�иЅй�иГиЇй� CP 866 я╗┐╪з┘Д╪е╪╣┘Д╪з┘Ж ╪з┘Д╪╣╪з┘Д┘Е┘Й ┘Д╪н┘В┘И┘В ╪з┘Д╪е┘Ж╪│╪з┘Ж ISO 8859-6 ُ؛؟ظ�ع�ظ�ظ�ع�ظ�ع� ظ�ع�ظ�ظ�ع�ع�ع� ع�ظع�ع�ع� ظ�ع�ظ�ع�ظ�ظ�ع� ISO 8859-2 اŮ�ŘĽŘšŮ�اŮ� اŮ�ؚاŮ�Ů�Ů� Ů�ŘŮ�Ů�Ů� اŮ�ŘĽŮ�ساŮ� References
- ^ p. 141, Control + Alt + Delete: A Dictionary of Cyberslang, Jonathon Keats, Globe Pequot, 2007, ISBN 1599210398.
- ^ Cohen, Noam (June 25, 2007). "Some Errors Defy Fixes: A Typo in Wikipedia’s Logo Fractures the Sanskrit". The New York Times. http://www.nytimes.com/2007/06/25/technology/25wikipedia.html?_r=2&oref=slogin. Retrieved July 17, 2009.
- ^ http://msdn.microsoft.com/en-us/library/ms776260(VS.85).aspx
¶ÔÓÚ½ñÌìÊÇÄãÄãÊÇÄÇôµÄì¶Ü£¬
External links
- Reprinted article from the Japan Times
- Coldfusion Developers Guide article
- Online decoder of Hebrew text – Online decoder converts input into readable Hebrew text
- Translators guide
- Recovery tool – Recovery of Japanese text (Japanese)
- Chinese E-mail Fixer – Recovery of Chinese text
- Chinese Encoding Converter - Convert file encoding of text files
- Decodr.ru - Fast Cyrillic decoder of e-mail and charsets
- Universal Cyrillic decoder – Recovery of Cyrillic text
- Multilingual online text decoder – Online decoder converts scrambled input into readable text. Supported languages are Russian, Bulgarian, Greek, Hebrew and Thai.
- Noto pri ĉapeloj: Resuma tabelo – Covers most cases of Esperanto mojibake.
- Encoding Repair Kit – Fixes mojibake, originally intended for Japanese. Windows freeware, 1998. Not compatible with Windows Vista or 7.
Character encodings  Character sets
Character setsEarly telecommunications ASCII · ISO/IEC 646 · ISO/IEC 6937 · T.61 · sixbit code pages · Baudot code · Morse code · Chinese telegraph codeISO/IEC 8859 Bibliographic use National standards ArmSCII · CNS 11643 · GOST 10859 · GB 2312 · HKSCS · ISCII · JIS X 0201 · JIS X 0208 · JIS X 0212 · JIS X 0213 · KPS 9566 · KS X 1001 · PASCII · TIS-620 · TSCII · VISCII · YUSCIIEUC CN · JP · KR · TWISO/IEC 2022 CN · JP · KR · CCCIIMacOS codepages ("scripts") DOS codepages Windows codepages EBCDIC codepages 37/1140 · 273/1141 · 277/1142 · 278/1143 · 280/1144 · 284/1145 · 285/1146 · 297/1147 · 420/16804 · 424/12712 · 500/1148 · 838/1160 · 871/1149 · 875/9067 · 930/1390 · 933/1364 · 937/1371 · 935/1388 · 939/1399 · 1025/1154 · 1026/1155 · 1047/924 · 1112/1156 · 1122/1157 · 1123/1158 · 1130/1164 · JEF · KEISPlatform specific ATASCII · CDC display code · DEC-MCS · DEC Radix-50 · Fieldata · GSM 03.38 · HP roman8 · PETSCII · TI calculator character sets · WISCII · ZX Spectrum character setUnicode / ISO/IEC 10646 Miscellaneous codepages Related topics control character (C0 C1) · CCSID · Character encodings in HTML · charset detection · Han unification · ISO 6429/IEC 6429/ANSI X3.64 · mojibakeCategories:- Japanese words and phrases
- Character encoding
- Computer errors


Wikimedia Foundation. 2010.