- Hash table
-
"Unordered map" redirects here. For the proposed C++ class, see unordered_map (C++).
Hash Table Type unsorted dictionary Invented 1953 Time complexity
in big O notationAverage Worst case Space O(n)[1] O(n) Search O(1) O(n) Insert O(1) O(1) Delete O(1) O(n)  A small phone book as a hash table.
A small phone book as a hash table.
In computer science, a hash table or hash map is a data structure that uses a hash function to map identifying values, known as keys (e.g., a person's name), to their associated values (e.g., their telephone number). Thus, a hash table implements an associative array. The hash function is used to transform the key into the index (the hash) of an array element (the slot or bucket) where the corresponding value is to be sought.
Ideally, the hash function should map each possible key to a unique slot index, but this ideal is rarely achievable in practice (unless the hash keys are fixed; i.e. new entries are never added to the table after it is created). Instead, most hash table designs assume that hash collisions—different keys that map to the same hash value—will occur and must be accommodated in some way.
In a well-dimensioned hash table, the average cost (number of instructions) for each lookup is independent of the number of elements stored in the table. Many hash table designs also allow arbitrary insertions and deletions of key-value pairs, at constant average (indeed, amortized[2]) cost per operation.[3][4]
In many situations, hash tables turn out to be more efficient than search trees or any other table lookup structure. For this reason, they are widely used in many kinds of computer software, particularly for associative arrays, database indexing, caches, and sets.
Contents
Hash function
Main article: Hash functionAt the heart of the hash table algorithm is a simple array of items; this is often simply called the hash table. Hash table algorithms calculate an index from the data item's key and use this index to place the data into the array. The implementation of this calculation is the hash function, f:
index = f(key, arrayLength)
The hash function calculates an index within the array from the data key. arrayLength is the size of the array. For assembly language or other low-level programs, a trivial hash function can often create an index with just one or two inline machine instructions.
Choosing a good hash function
A good hash function and implementation algorithm are essential for good hash table performance, but may be difficult to achieve. Poor hashing usually degrades hash table performance by a constant factor,[citation needed] but hashing is often only a small part of the overall computation.
A basic requirement is that the function should provide a uniform distribution of hash values. A non-uniform distribution increases the number of collisions, and the cost of resolving them. Uniformity is sometimes difficult to ensure by design, but may be evaluated empirically using statistical tests, e.g. a Pearson's chi-squared test for uniform distributions [5] .[6]
The distribution needs to be uniform only for table sizes s that occur in the application. In particular, if one uses dynamic resizing with exact doubling and halving of s, the hash function needs to be uniform only when s is a power of two. On the other hand, some hashing algorithms provide uniform hashes only when s is a prime number.[7]
For open addressing schemes, the hash function should also avoid clustering, the mapping of two or more keys to consecutive slots. Such clustering may cause the lookup cost to skyrocket, even if the load factor is low and collisions are infrequent. The popular multiplicative hash[3] is claimed to have particularly poor clustering behavior.[7]
Cryptographic hash functions are believed to provide good hash functions for any table size s, either by modulo reduction or by bit masking. They may also be appropriate, if there is a risk of malicious users trying to sabotage a network service by submitting requests designed to generate a large number of collisions in the server's hash tables.[citation needed] However, these presumed qualities are hardly worth their much larger computational cost and algorithmic complexity, and the risk of sabotage can be avoided by cheaper methods (such as applying a secret salt to the data, or using a universal hash function).
Some authors claim that good hash functions should have the avalanche effect; that is, a single-bit change in the input key should affect, on average, half the bits in the output. Some popular hash functions do not have this property.[citation needed]
Perfect hash function
If all keys are known ahead of time, a perfect hash function can be used to create a perfect hash table that has no collisions. If minimal perfect hashing is used, every location in the hash table can be used as well.
Perfect hashing allows for constant time lookups in the worst case. This is in contrast to most chaining and open addressing methods, where the time for lookup is low on average, but may be very large (proportional to the number of entries) for some sets of keys.
Collision resolution
Hash collisions are practically unavoidable when hashing a random subset of a large set of possible keys. For example, if 2,500 keys are hashed into a million buckets, even with a perfectly uniform random distribution, according to the birthday problem there is a 95% chance of at least two of the keys being hashed to the same slot.
Therefore, most hash table implementations have some collision resolution strategy to handle such events. Some common strategies are described below. All these methods require that the keys (or pointers to them) be stored in the table, together with the associated values.
Load factor
The performance of most collision resolution methods does not depend directly on the number n of stored entries, but depends strongly on the table's load factor, the ratio n/s between n and the size s of its array of buckets. Sometimes this is referred to as the fill factor, as it represents the portion of the s buckets in the structure that are filled with one of the n stored entries. With a good hash function, the average lookup cost is nearly constant as the load factor increases from 0 up to 0.7(about 2/3 full) or so.[citation needed] Beyond that point, the probability of collisions and the cost of handling them increases.
On the other hand, as the load factor approaches zero, the proportion of the unused areas in the hash table increases but there is not necessarily any improvement in the search cost, resulting in wasted memory.
Separate chaining
 Hash collision resolved by separate chaining.
Hash collision resolved by separate chaining.In the strategy known as separate chaining, direct chaining, or simply chaining, each slot of the bucket array is a pointer to a linked list that contains the key-value pairs that hashed to the same location. Lookup requires scanning the list for an entry with the given key. Insertion requires adding a new entry record to either end of the list belonging to the hashed slot. Deletion requires searching the list and removing the element. (The technique is also called open hashing or closed addressing, which should not be confused with 'open addressing' or 'closed hashing'.)
Chained hash tables with linked lists are popular because they require only basic data structures with simple algorithms, and can use simple hash functions that are unsuitable for other methods.
The cost of a table operation is that of scanning the entries of the selected bucket for the desired key. If the distribution of keys is sufficiently uniform, the average cost of a lookup depends only on the average number of keys per bucket—that is, on the load factor.
Chained hash tables remain effective even when the number of table entries n is much higher than the number of slots. Their performance degrades more gracefully (linearly) with the load factor. For example, a chained hash table with 1000 slots and 10,000 stored keys (load factor 10) is five to ten times slower than a 10,000-slot table (load factor 1); but still 1000 times faster than a plain sequential list, and possibly even faster than a balanced search tree.
For separate-chaining, the worst-case scenario is when all entries were inserted into the same bucket, in which case the hash table is ineffective and the cost is that of searching the bucket data structure. If the latter is a linear list, the lookup procedure may have to scan all its entries; so the worst-case cost is proportional to the number n of entries in the table.
The bucket chains are often implemented as ordered lists, sorted by the key field; this choice approximately halves the average cost of unsuccessful lookups, compared to an unordered list[citation needed]. However, if some keys are much more likely to come up than others, an unordered list with move-to-front heuristic may be more effective. More sophisticated data structures, such as balanced search trees, are worth considering only if the load factor is large (about 10 or more), or if the hash distribution is likely to be very non-uniform, or if one must guarantee good performance even in the worst-case. However, using a larger table and/or a better hash function may be even more effective in those cases.
Chained hash tables also inherit the disadvantages of linked lists. When storing small keys and values, the space overhead of the
nextpointer in each entry record can be significant. An additional disadvantage is that traversing a linked list has poor cache performance, making the processor cache ineffective.Separate chaining with list heads
 Hash collision by separate chaining with head records in the bucket array.
Hash collision by separate chaining with head records in the bucket array.Some chaining implementations store the first record of each chain in the slot array itself.[4] The purpose is to increase cache efficiency of hash table access. To save memory space, such hash tables often have about as many slots as stored entries, meaning that many slots have two or more entries.
Separate chaining with other structures
Instead of a list, one can use any other data structure that supports the required operations. For example, by using a self-balancing tree, the theoretical worst-case time of common hash table operations (insertion, deletion, lookup) can be brought down to O(log n) rather than O(n). However, this approach is only worth the trouble and extra memory cost if long delays must be avoided at all costs (e.g. in a real-time application), or if one expects to have many entries hashed to the same slot (e.g. if one expects extremely non-uniform or even malicious key distributions).
The variant called array hash table uses a dynamic array to store all the entries that hash to the same slot.[8][9][10] Each newly inserted entry gets appended to the end of the dynamic array that is assigned to the slot. The dynamic array is resized in an exact-fit manner, meaning it is grown only by as many bytes as needed. Alternative techniques such as growing the array by block sizes or pages were found to improve insertion performance, but at a cost in space. This variation makes more efficient use of CPU caching and the translation lookaside buffer (TLB), because slot entries are stored in sequential memory positions. It also dispenses with the
nextpointers that are required by linked lists, which saves space. Despite frequent array resizing, space overheads incurred by operating system such as memory fragmentation, were found to be small.An elaboration on this approach is the so-called dynamic perfect hashing,[11] where a bucket that contains k entries is organized as a perfect hash table with k2 slots. While it uses more memory (n2 slots for n entries, in the worst case), this variant has guaranteed constant worst-case lookup time, and low amortized time for insertion.
Open addressing
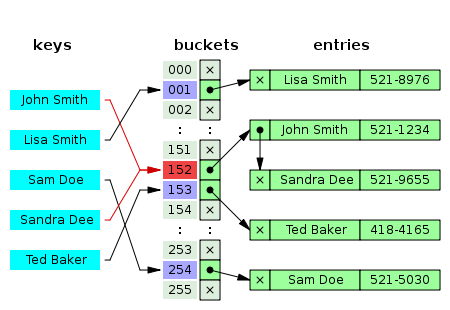
 Hash collision resolved by open addressing with linear probing (interval=1). Note that "Ted Baker" has a unique hash, but nevertheless collided with "Sandra Dee" that had previously collided with "John Smith".
Hash collision resolved by open addressing with linear probing (interval=1). Note that "Ted Baker" has a unique hash, but nevertheless collided with "Sandra Dee" that had previously collided with "John Smith".In another strategy, called open addressing, all entry records are stored in the bucket array itself. When a new entry has to be inserted, the buckets are examined, starting with the hashed-to slot and proceeding in some probe sequence, until an unoccupied slot is found. When searching for an entry, the buckets are scanned in the same sequence, until either the target record is found, or an unused array slot is found, which indicates that there is no such key in the table.[12] The name "open addressing" refers to the fact that the location ("address") of the item is not determined by its hash value. (This method is also called closed hashing; it should not be confused with "open hashing" or "closed addressing" that usually mean separate chaining.)
Well-known probe sequences include:
- Linear probing, in which the interval between probes is fixed (usually 1)
- Quadratic probing, in which the interval between probes is increased by adding the successive outputs of a quadratic polynomial to the starting value given by the original hash computation
- Double hashing, in which the interval between probes is computed by another hash function
A drawback of all these open addressing schemes is that the number of stored entries cannot exceed the number of slots in the bucket array. In fact, even with good hash functions, their performance dramatically degrades when the load factor grows beyond 0.7 or so. Thus a more aggressive resize scheme is needed. Separate linking works correctly with any load factor, although performance is likely to be reasonable if it is kept below 2 or so. For many applications, these restrictions mandate the use of dynamic resizing, with its attendant costs.
Open addressing schemes also put more stringent requirements on the hash function: besides distributing the keys more uniformly over the buckets, the function must also minimize the clustering of hash values that are consecutive in the probe order. Using separate chaining, the only concern is that too many objects map to the same hash value; whether they are adjacent or nearby is completely irrelevant.
Even experienced programmers may find such clustering hard to avoid.
Open addressing only saves memory if the entries are small (less than 4 times the size of a pointer) and the load factor is not too small. If the load factor is close to zero (that is, there are far more buckets than stored entries), open addressing is wasteful even if each entry is just two words.
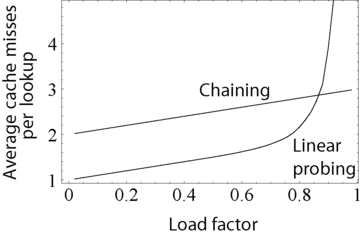 This graph compares the average number of cache misses required to lookup elements in tables with chaining and linear probing. As the table passes the 80%-full mark, linear probing's performance drastically degrades.
This graph compares the average number of cache misses required to lookup elements in tables with chaining and linear probing. As the table passes the 80%-full mark, linear probing's performance drastically degrades.Open addressing avoids the time overhead of allocating each new entry record, and can be implemented even in the absence of a memory allocator. It also avoids the extra indirection required to access the first entry of each bucket (that is, usually the only one). It also has better locality of reference, particularly with linear probing. With small record sizes, these factors can yield better performance than chaining, particularly for lookups.
Hash tables with open addressing are also easier to serialize, because they do not use pointers.
On the other hand, normal open addressing is a poor choice for large elements, because these elements fill entire CPU cache lines (negating the cache advantage), and a large amount of space is wasted on large empty table slots. If the open addressing table only stores references to elements (external storage), it uses space comparable to chaining even for large records but loses its speed advantage.
Generally speaking, open addressing is better used for hash tables with small records that can be stored within the table (internal storage) and fit in a cache line. They are particularly suitable for elements of one word or less. If the table is expected to have a high load factor, the records are large, or the data is variable-sized, chained hash tables often perform as well or better.
Ultimately, used sensibly, any kind of hash table algorithm is usually fast enough; and the percentage of a calculation spent in hash table code is low. Memory usage is rarely considered excessive. Therefore, in most cases the differences between these algorithms are marginal, and other considerations typically come into play.
Coalesced hashing
A hybrid of chaining and open addressing, coalesced hashing links together chains of nodes within the table itself.[12] Like open addressing, it achieves space usage and (somewhat diminished) cache advantages over chaining. Like chaining, it does not exhibit clustering effects; in fact, the table can be efficiently filled to a high density. Unlike chaining, it cannot have more elements than table slots.
Robin Hood hashing
One interesting variation on double-hashing collision resolution is Robin Hood hashing.[13] The idea is that a new key may displace a key already inserted, if its probe count is larger than that of the key at the current position. The net effect of this is that it reduces worst case search times in the table. This is similar to Knuth's ordered hash tables except that the criterion for bumping a key does not depend on a direct relationship between the keys. Since both the worst case and the variation in the number of probes is reduced dramatically, an interesting variation is to probe the table starting at the expected successful probe value and then expand from that position in both directions.[14] External Robin Hashing is an extension of this algorithm where the table is stored in an external file and each table position corresponds to a fixed-sized page or bucket with B records.[15]
Cuckoo hashing
Another alternative open-addressing solution is cuckoo hashing, which ensures constant lookup time in the worst case, and constant amortized time for insertions and deletions. It uses two or more hash functions, which means any key/value pair could be in two or more locations. For lookup, the first hash function is used; if the key/value is not found, then the second hash function is used, and so on. If a collision happens during insertion, then the key is re-hashed with the second hash function to map it to another bucket. If all hash functions are used and there is still a collision, then the key it collided with is removed to make space for the new key, and the old key is re-hashed with one of the other hash functions, which maps it to another bucket. If that location also results in a collision, then the process repeats until there is no collision or the process traverses all the buckets, at which point the table is resized. By combining multiple hash functions with multiple cells per bucket, very high space utilisation can be achieved.
Hopscotch hashing
Another alternative open-addressing solution is hopscotch hashing,[16] which combines the approaches of cuckoo hashing and linear probing, yet seems in general to avoid their limitations. In particular it works well even when the load factor grows beyond 0.9. The algorithm is well suited for implementing a resizable concurrent hash table.
The hopscotch hashing algorithm works by defining a neighborhood of buckets near the original hashed bucket, where a given entry is always found. Thus, search is limited to the number of entries in this neighborhood, which is logarithmic in the worst case, constant on average, and with proper alignment of the neighborhood typically requires one cache miss. When inserting an entry, one first attempts to add it to a bucket in the neighborhood. However, if all buckets in this neighborhood are occupied, the algorithm traverses buckets in sequence until an open slot (an unoccupied bucket) is found (as in linear probing). At that point, since the empty bucket is outside the neighborhood, items are repeatedly displaced in a sequence of hops. (This is similar to cuckoo hashing, but with the difference that in this case the empty slot is being moved into the neighborhood, instead of items being moved out with the hope of eventually finding an empty slot.) Each hop brings the open slot closer to the original neighborhood, without invalidating the neighborhood property of any of the buckets along the way. In the end, the open slot has been moved into the neighborhood, and the entry being inserted can be added to it.
Dynamic resizing
To keep the load factor under a certain limit, e.g. under 3/4, many table implementations expand the table when items are inserted. For example, in Java's HashMap class the default load factor threshold for table expansion is 0.75. Since buckets are usually implemented on top of a dynamic array and any constant proportion for resizing greater than 1 will keep the load factor under the desired limit, the exact choice of the constant is determined by the same space-time tradeoff as for dynamic arrays.
Resizing is accompanied by a full or incremental table rehash whereby existing items are mapped to new bucket locations.
To limit the proportion of memory wasted due to empty buckets, some implementations also shrink the size of the table—followed by a rehash—when items are deleted. From the point of space-time tradeoffs, this operation is similar to the deallocation in dynamic arrays.
Resizing by copying all entries
A common approach is to automatically trigger a complete resizing when the load factor exceeds some threshold rmax. Then a new larger table is allocated, all the entries of the old table are removed and inserted into this new table, and the old table is returned to the free storage pool. Symmetrically, when the load factor falls below a second threshold rmin, all entries are moved to a new smaller table.
If the table size increases or decreases by a fixed percentage at each expansion, the total cost of these resizings, amortized over all insert and delete operations, is still a constant, independent of the number of entries n and of the number m of operations performed.
For example, consider a table that was created with the minimum possible size and is doubled each time the load ratio exceeds some threshold. If m elements are inserted into that table, the total number of extra re-insertions that occur in all dynamic resizings of the table is at most m−1. In other words, dynamic resizing roughly doubles the cost of each insert or delete operation.
Incremental resizing
Some hash table implementations, notably in real-time systems, cannot pay the price of enlarging the hash table all at once, because it may interrupt time-critical operations. If one cannot avoid dynamic resizing, a solution is to perform the resizing gradually:
- During the resize, allocate the new hash table, but keep the old table unchanged.
- In each lookup or delete operation, check both tables.
- Perform insertion operations only in the new table.
- At each insertion also move r elements from the old table to the new table.
- When all elements are removed from the old table, deallocate it.
To ensure that the old table is completely copied over before the new table itself needs to be enlarged, it is necessary to increase the size of the table by a factor of at least (r + 1)/r during resizing.
Monotonic keys
If it is known that key values will always increase monotonically, then a variation of consistent hashing can be achieved by keeping a list of the single most recent key value at each hash table resize operation. Upon lookup, keys that fall in the ranges defined by these list entries are directed to the appropriate hash function—and indeed hash table—both of which can be different for each range. Since it is common to grow the overall number of entries by doubling, there will only be O(lg(N)) ranges to check, and binary search time for the redirection would be O(lg(lg(N))).
Other solutions
Linear hashing [17] is a hash table algorithm that permits incremental hash table expansion. It is implemented using a single hash table, but with two possible look-up functions.
Another way to decrease the cost of table resizing is to choose a hash function in such a way that the hashes of most values do not change when the table is resized. This approach, called consistent hashing, is prevalent in disk-based and distributed hashes, where rehashing is prohibitively costly.
Performance analysis
In the simplest model, the hash function is completely unspecified and the table does not resize. For the best possible choice of hash function, a table of size n with open addressing has no collisions and holds up to n elements, with a single comparison for successful lookup, and a table of size n with chaining and k keys has the minimum max(0, k-n) collisions and O(1 + k/n) comparisons for lookup. For the worst choice of hash function, every insertion causes a collision, and hash tables degenerate to linear search, with Ω(k) amortized comparisons per insertion and up to k comparisons for a successful lookup.
Adding rehashing to this model is straightforward. As in a dynamic array, geometric resizing by a factor of b implies that only k/bi keys are inserted i or more times, so that the total number of insertions is bounded above by bk/(b-1), which is O(k). By using rehashing to maintain k < n, tables using both chaining and open addressing can have unlimited elements and perform successful lookup in a single comparison for the best choice of hash function.
In more realistic models, the hash function is a random variable over a probability distribution of hash functions, and performance is computed on average over the choice of hash function. When this distribution is uniform, the assumption is called "simple uniform hashing" and it can be shown that hashing with chaining requires Θ(1 + k/n) comparisons on average for an unsuccessful lookup, and hashing with open addressing requires Θ(1/(1 - k/n)).[18] Both these bounds are constant, if we maintain k/n < c using table resizing, where c is a fixed constant less than 1.
Features
Advantages
The main advantage of hash tables over other table data structures is speed. This advantage is more apparent when the number of entries is large (thousands or more). Hash tables are particularly efficient when the maximum number of entries can be predicted in advance, so that the bucket array can be allocated once with the optimum size and never resized.
If the set of key-value pairs is fixed and known ahead of time (so insertions and deletions are not allowed), one may reduce the average lookup cost by a careful choice of the hash function, bucket table size, and internal data structures. In particular, one may be able to devise a hash function that is collision-free, or even perfect (see below). In this case the keys need not be stored in the table.
Drawbacks
Although operations on a hash table take constant time on average, the cost of a good hash function can be significantly higher than the inner loop of the lookup algorithm for a sequential list or search tree. Thus hash tables are not effective when the number of entries is very small. (However, in some cases the high cost of computing the hash function can be mitigated by saving the hash value together with the key.)
For certain string processing applications, such as spell-checking, hash tables may be less efficient than tries, finite automata, or Judy arrays. Also, if each key is represented by a small enough number of bits, then, instead of a hash table, one may use the key directly as the index into an array of values. Note that there are no collisions in this case.
The entries stored in a hash table can be enumerated efficiently (at constant cost per entry), but only in some pseudo-random order. Therefore, there is no efficient way to locate an entry whose key is nearest to a given key. Listing all n entries in some specific order generally requires a separate sorting step, whose cost is proportional to log(n) per entry. In comparison, ordered search trees have lookup and insertion cost proportional to log(n), but allow finding the nearest key at about the same cost, and ordered enumeration of all entries at constant cost per entry.
If the keys are not stored (because the hash function is collision-free), there may be no easy way to enumerate the keys that are present in the table at any given moment.
Although the average cost per operation is constant and fairly small, the cost of a single operation may be quite high. In particular, if the hash table uses dynamic resizing, an insertion or deletion operation may occasionally take time proportional to the number of entries. This may be a serious drawback in real-time or interactive applications.
Hash tables in general exhibit poor locality of reference—that is, the data to be accessed is distributed seemingly at random in memory. Because hash tables cause access patterns that jump around, this can trigger microprocessor cache misses that cause long delays. Compact data structures such as arrays searched with linear search may be faster, if the table is relatively small and keys are integers or other short strings. According to Moore's Law, cache sizes are growing exponentially and so what is considered "small" may be increasing. The optimal performance point varies from system to system.
Hash tables become quite inefficient when there are many collisions. While extremely uneven hash distributions are extremely unlikely to arise by chance, a malicious adversary with knowledge of the hash function may be able to supply information to a hash that creates worst-case behavior by causing excessive collisions, resulting in very poor performance (e.g., a denial of service attack). In critical applications, either universal hashing can be used or a data structure with better worst-case guarantees may be preferable.[19]
Uses
Associative arrays
Hash tables are commonly used to implement many types of in-memory tables. They are used to implement associative arrays (arrays whose indices are arbitrary strings or other complicated objects), especially in interpreted programming languages like AWK, Perl, and PHP.
When storing a new item into a multimap and a hash collision occurs, the multimap unconditionally stores both items.
When storing a new item into a typical associative array and a hash collision occurs, but the actual keys themselves are different, the associative array likewise stores both items. However, if the key of the new item exactly matches the key of an old item, the associative array typically erases the old item and overwrites it with the new item, so every item in the table has a unique key.
Database indexing
Hash tables may also be used as disk-based data structures and database indices (such as in dbm) although B-trees are more popular in these applications.
Caches
Hash tables can be used to implement caches, auxiliary data tables that are used to speed up the access to data that is primarily stored in slower media. In this application, hash collisions can be handled by discarding one of the two colliding entries—usually erasing the old item that is currently stored in the table and overwriting it with the new item, so every item in the table has a unique hash value.
Sets
Besides recovering the entry that has a given key, many hash table implementations can also tell whether such an entry exists or not.
Those structures can therefore be used to implement a set data structure, which merely records whether a given key belongs to a specified set of keys. In this case, the structure can be simplified by eliminating all parts that have to do with the entry values. Hashing can be used to implement both static and dynamic sets.
Object representation
Several dynamic languages, such as Perl, Python, JavaScript, and Ruby, use hash tables to implement objects. In this representation, the keys are the names of the members and methods of the object, and the values are pointers to the corresponding member or method.
Unique data representation
Hash tables can be used by some programs to avoid creating multiple character strings with the same contents. For that purpose, all strings in use by the program are stored in a single hash table, which is checked whenever a new string has to be created. This technique was introduced in Lisp interpreters under the name hash consing, and can be used with many other kinds of data (expression trees in a symbolic algebra system, records in a database, files in a file system, binary decision diagrams, etc.)
String interning
Main article: String interningImplementations
In programming languages
Many programming languages provide hash table functionality, either as built-in associative arrays or as standard library modules. In C++11, for example, the
unordered_mapclass provides hash tables for keys and values of arbitrary type.In PHP 5, the Zend 2 engine uses one of the hash functions from Daniel J. Bernstein to generate the hash values used in managing the mappings of data pointers stored in a HashTable. In the PHP source code, it is labelled as "DJBX33A" (Daniel J. Bernstein, Times 33 with Addition).
Python's built-in hash table implementation, in the form of the
dicttype, as well as Perl's hash type (%) are highly optimized as they are used internally to implement namespaces.In the .NET Framework, support for hash tables is provided via the non-generic
Hashtableand genericDictionaryclasses, which store key-value pairs, and the genericHashSetclass, which stores only values.Independent packages
- Google Sparse Hash The Google SparseHash project contains several C++ hash-map implementations in use at Google, with different performance characteristics, including an implementation that optimizes for memory use and one that optimizes for speed. The memory-optimized one is extremely memory-efficient with only 2 bits/entry of overhead.
- SunriseDD An open source C library for hash table storage of arbitrary data objects with lock-free lookups, built-in reference counting and guaranteed order iteration. The library can participate in external reference counting systems or use its own built-in reference counting. It comes with a variety of hash functions and allows the use of runtime supplied hash functions via callback mechanism. Source code is well documented.
- uthash This is an easy-to-use hash table for C structures.
History
The idea of hashing arose independently in different places. In January 1953, H. P. Luhn wrote an internal IBM memorandum that used hashing with chaining.[20] G. N. Amdahl, E. M. Boehme, N. Rochester, and Arthur Samuel implemented a program using hashing at about the same time. Open addressing with linear probing (relatively prime stepping) is credited to Amdahl, but Ershov (in Russia) had the same idea.[20]
See also
- Rabin–Karp string search algorithm
- Stable hashing
- Consistent hashing
- Extendible hashing
- Lazy deletion
- Pearson hashing
Related data structures
There are several data structures that use hash functions but cannot be considered special cases of hash tables:
- Bloom filter, a structure that implements an enclosing approximation of a set, allowing insertions but not deletions.
- Distributed hash table (DHT), a resilient dynamic table spread over several nodes of a network.
- Hash array mapped trie, a trie structure, similar to the array mapped trie, but where each key is hashed first.
References
- ^ Thomas H. Corman [et al.] (2009). 'Introduction to Algorithms' (3rd ed.). Massachusetts Institute of Technology. pp. 253–280. ISBN 978-0-262-03384-8.
- ^ Charles E. Leiserson, Amortized Algorithms, Table Doubling, Potential Method Lecture 13, course MIT 6.046J/18.410J Introduction to Algorithms—Fall 2005
- ^ a b Donald Knuth (1998). The Art of Computer Programming'. 3: Sorting and Searching (2nd ed.). Addison-Wesley. pp. 513–558. ISBN 0-201-89685-0.
- ^ a b Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001). Introduction to Algorithms (second ed.). MIT Press and McGraw-Hill. 221–252. ISBN 978-0-262-53196-2.
- ^ Karl Pearson (1900). "On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling". Philosophical Magazine, Series 5 50 (302): pp. 157–175.
- ^ Robin Plackett (1983). "Karl Pearson and the Chi-Squared Test". International Statistical Review (International Statistical Institute (ISI)) 51 (1): pp. 59–72.
- ^ a b Thomas Wang (1997), Prime Double Hash Table. Accessed April 11, 2009
- ^ Askitis, Nikolas; Zobel, Justin (2005). Cache-conscious Collision Resolution in String Hash Tables. 3772. 91–102. doi:10.1007/11575832_11. ISBN 1721172558. http://www.springerlink.com/content/b61721172558qt03/.
- ^ Askitis, Nikolas; Sinha, Ranjan (2010). Engineering scalable, cache and space efficient tries for strings. doi:10.1007/s00778-010-0183-9. ISBN 1066-8888 (Print) 0949-877X (Online). http://www.springerlink.com/content/86574173183j6565/.
- ^ Askitis, Nikolas (2009). Fast and Compact Hash Tables for Integer Keys. 91. 113–122. ISBN 978-1-920682-72-9. http://crpit.com/confpapers/CRPITV91Askitis.pdf.
- ^ Erik Demaine, Jeff Lind. 6.897: Advanced Data Structures. MIT Computer Science and Artificial Intelligence Laboratory. Spring 2003. http://courses.csail.mit.edu/6.897/spring03/scribe_notes/L2/lecture2.pdf
- ^ a b Tenenbaum, Aaron M.; Langsam, Yedidyah; Augenstein, Moshe J. (1990). Data Structures Using C. Prentice Hall. pp. 456–461, pp. 472. ISBN 0-13-199746-7.
- ^ Celis, Pedro (1986). Robin Hood hashing (Technical report). Computer Science Department, University of Waterloo. CS-86-14.
- ^ Viola, Alfredo (October 2005). "Exact distribution of individual displacements in linear probing hashing". Transactions on Algorithms (TALG) (ACM) 1 (2,): 214–242. doi:10.1145/1103963.1103965.
- ^ Celis, Pedro (March, 1988). External Robin Hood Hashing (Technical report). Computer Science Department, Indiana University. TR246.
- ^ Herlihy, Maurice and Shavit, Nir and Tzafrir, Moran (2008). "Hopscotch Hashing". DISC '08: Proceedings of the 22nd international symposium on Distributed Computing. Arcachon, France: Springer-Verlag. pp. 350–364.
- ^ Litwin, Witold (1980). "Linear hashing: A new tool for file and table addressing". Proc. 6th Conference on Very Large Databases. pp. 212–223.
- ^ Doug Dunham. CS 4521 Lecture Notes. University of Minnesota Duluth. Theorems 11.2, 11.6. Last modified 21 April 2009.
- ^ Crosby and Wallach's Denial of Service via Algorithmic Complexity Attacks.
- ^ a b Mehta, Dinesh P.; Sahni, Sartaj. Handbook of Datastructures and Applications. pp. 9–15. ISBN 1584884355.
Further reading
- "9: Maps and Dictionaries". Data Structures and Algorithms in Java (4th ed.). Wiley. pp. 369–418. ISBN 0-471-73884-0.
External links
- A Hash Function for Hash Table Lookup by Bob Jenkins.
- Hash Tables by SparkNotes—explanation using C
- Hash functions by Paul Hsieh
- Design of Compact and Efficient Hash Tables for Java
- Libhashish hash library
- NIST entry on hash tables
- Open addressing hash table removal algorithm from ICI programming language, ici_set_unassign in set.c (and other occurrences, with permission).
- A basic explanation of how the hash table works by Reliable Software
- Lecture on Hash Tables
- Hash-tables in C—two simple and clear examples of hash tables implementation in C with linear probing and chaining
- MIT's Introduction to Algorithms: Hashing 1 MIT OCW lecture Video
- MIT's Introduction to Algorithms: Hashing 2 MIT OCW lecture Video
- How to sort a HashMap (Java) and keep the duplicate entries
- Concurrent Data Structures (libcds) - a C++ template library of various lock-free hash table containers
Data structures Types Abstract Arrays - Dynamic array
- Sparse array
- Circular buffer
- Bit array
- Hash table
Linked Trees Graphs Categories:- Hashing
- Search algorithms




Wikimedia Foundation. 2010.