- Web search engine
-
"Search engine" redirects here. For other uses, see Search engine (disambiguation).
 The three most widely used web search engines and their approximate share as of late 2010.[1]
The three most widely used web search engines and their approximate share as of late 2010.[1]
A web search engine is designed to search for information on the World Wide Web and FTP servers. The search results are generally presented in a list of results often referred to as SERPS, or "search engine results pages". The information may consist of web pages, images, information and other types of files. Some search engines also mine data available in databases or open directories. Unlike web directories, which are maintained only by human editors, search engines also maintain real-time information by running an algorithm on a web crawler.
Contents
History
Timeline (full list) Year Engine Current status 1993 W3Catalog Active Aliweb Closed JumpStation Closed 1994 WebCrawler Active Go.com Active Lycos Active 1995 AltaVista Bought and operated by Yahoo! Daum Active Magellan Active Excite Active SAPO Active Yahoo! Active, Launched as a directory 1996 Dogpile Active Inktomi Active HotBot Active Ask Jeeves Active 1997 Northern Light Closed Yandex Active 1998 Google Active MSN Search Active as Bing 1999 AlltheWeb Closed (URL redirected to Yahoo!) GenieKnows Active Naver Active Teoma Active Vivisimo Active 2000 Baidu Active Exalead Active 2002 Inktomi Acquired by Yahoo! 2003 Info.com Active 2004 Yahoo! Search Active, Launched own web search
(see Yahoo! Directory, 1995)A9.com Closed Sogou Active 2005 AOL Search Active Ask.com Active GoodSearch Active SearchMe Active 2006 wikiseek Active Quaero Active Ask.com Active Live Search Active as Bing, Launched as
rebranded MSN SearchChaCha Active Guruji.com Active 2007 wikiseek Closed Sproose Closed Wikia Search Closed Blackle.com Active 2008 Powerset Acquired by Microsoft Picollator Closed Viewzi Closed Boogami Active LeapFish Active Forestle Active VADLO Active Duck Duck Go Active 2009 Bing Active, Launched as
rebranded Live SearchYebol Active Mugurdy Closed due to a lack of funding Goby Active 2010 Yandex Active, Launched global
(English) searchCuil Closed Blekko Active Yummly Active Solusee Active 2011 Exalead Acquired by Dassault Systèmes Interred Active During the early development of the web, there was a list of webservers edited by Tim Berners-Lee and hosted on the CERN webserver. One historical snapshot from 1992 remains.[2] As more webservers went online the central list could not keep up. On the NCSA site new servers were announced under the title "What's New!"[3]
The very first tool used for searching on the Internet was Archie.[4] The name stands for "archive" without the "v". It was created in 1990 by Alan Emtage, Bill Heelan and J. Peter Deutsch, computer science students at McGill University in Montreal. The program downloaded the directory listings of all the files located on public anonymous FTP (File Transfer Protocol) sites, creating a searchable database of file names; however, Archie did not index the contents of these sites since the amount of data was so limited it could be readily searched manually.
The rise of Gopher (created in 1991 by Mark McCahill at the University of Minnesota) led to two new search programs, Veronica and Jughead. Like Archie, they searched the file names and titles stored in Gopher index systems. Veronica (Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) provided a keyword search of most Gopher menu titles in the entire Gopher listings. Jughead (Jonzy's Universal Gopher Hierarchy Excavation And Display) was a tool for obtaining menu information from specific Gopher servers. While the name of the search engine "Archie" was not a reference to the Archie comic book series, "Veronica" and "Jughead" are characters in the series, thus referencing their predecessor.
In the summer of 1993, no search engine existed yet for the web, though numerous specialized catalogues were maintained by hand. Oscar Nierstrasz at the University of Geneva wrote a series of Perl scripts that would periodically mirror these pages and rewrite them into a standard format which formed the basis for W3Catalog, the web's first primitive search engine, released on September 2, 1993.[5]
In June 1993, Matthew Gray, then at MIT, produced what was probably the first web robot, the Perl-based World Wide Web Wanderer, and used it to generate an index called 'Wandex'. The purpose of the Wanderer was to measure the size of the World Wide Web, which it did until late 1995. The web's second search engine Aliweb appeared in November 1993. Aliweb did not use a web robot, but instead depended on being notified by website administrators of the existence at each site of an index file in a particular format.
JumpStation (released in December 1993[6]) used a web robot to find web pages and to build its index, and used a web form as the interface to its query program. It was thus the first WWW resource-discovery tool to combine the three essential features of a web search engine (crawling, indexing, and searching) as described below. Because of the limited resources available on the platform on which it ran, its indexing and hence searching were limited to the titles and headings found in the web pages the crawler encountered.
One of the first "full text" crawler-based search engines was WebCrawler, which came out in 1994. Unlike its predecessors, it let users search for any word in any webpage, which has become the standard for all major search engines since. It was also the first one to be widely known by the public. Also in 1994, Lycos (which started at Carnegie Mellon University) was launched and became a major commercial endeavor.
Soon after, many search engines appeared and vied for popularity. These included Magellan (search engine), Excite, Infoseek, Inktomi, Northern Light, and AltaVista. Yahoo! was among the most popular ways for people to find web pages of interest, but its search function operated on its web directory, rather than full-text copies of web pages. Information seekers could also browse the directory instead of doing a keyword-based search.
In 1996, Netscape was looking to give a single search engine an exclusive deal to be the featured search engine on Netscape's web browser. There was so much interest that instead a deal was struck with Netscape by five of the major search engines, where for $5 million per year each search engine would be in rotation on the Netscape search engine page. The five engines were Yahoo!, Magellan, Lycos, Infoseek, and Excite.[7][8]
Search engines were also known as some of the brightest stars in the Internet investing frenzy that occurred in the late 1990s.[9] Several companies entered the market spectacularly, receiving record gains during their initial public offerings. Some have taken down their public search engine, and are marketing enterprise-only editions, such as Northern Light. Many search engine companies were caught up in the dot-com bubble, a speculation-driven market boom that peaked in 1999 and ended in 2001.
Around 2000, Google's search engine rose to prominence.[citation needed] The company achieved better results for many searches with an innovation called PageRank. This iterative algorithm ranks web pages based on the number and PageRank of other web sites and pages that link there, on the premise that good or desirable pages are linked to more than others. Google also maintained a minimalist interface to its search engine. In contrast, many of its competitors embedded a search engine in a web portal.
By 2000, Yahoo! was providing search services based on Inktomi's search engine. Yahoo! acquired Inktomi in 2002, and Overture (which owned AlltheWeb and AltaVista) in 2003. Yahoo! switched to Google's search engine until 2004, when it launched its own search engine based on the combined technologies of its acquisitions.
Microsoft first launched MSN Search in the fall of 1998 using search results from Inktomi. In early 1999 the site began to display listings from Looksmart blended with results from Inktomi except for a short time in 1999 when results from AltaVista were used instead. In 2004, Microsoft began a transition to its own search technology, powered by its own web crawler (called msnbot).
Microsoft's rebranded search engine, Bing, was launched on June 1, 2009. On July 29, 2009, Yahoo! and Microsoft finalized a deal in which Yahoo! Search would be powered by Microsoft Bing technology.
How web search engines work
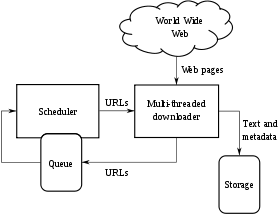 High-level architecture of a standard Web crawler
High-level architecture of a standard Web crawlerA search engine operates in the following order:
Web search engines work by storing information about many web pages, which they retrieve from the html itself. These pages are retrieved by a Web crawler (sometimes also known as a spider) — an automated Web browser which follows every link on the site. Exclusions can be made by the use of robots.txt. The contents of each page are then analyzed to determine how it should be indexed (for example, words are extracted from the titles, headings, or special fields called meta tags). Data about web pages are stored in an index database for use in later queries. A query can be a single word. The purpose of an index is to allow information to be found as quickly as possible. Some search engines, such as Google, store all or part of the source page (referred to as a cache) as well as information about the web pages, whereas others, such as AltaVista, store every word of every page they find. This cached page always holds the actual search text since it is the one that was actually indexed, so it can be very useful when the content of the current page has been updated and the search terms are no longer in it. This problem might be considered to be a mild form of linkrot, and Google's handling of it increases usability by satisfying user expectations that the search terms will be on the returned webpage. This satisfies the principle of least astonishment since the user normally expects the search terms to be on the returned pages. Increased search relevance makes these cached pages very useful, even beyond the fact that they may contain data that may no longer be available elsewhere.
When a user enters a query into a search engine (typically by using key words), the engine examines its index and provides a listing of best-matching web pages according to its criteria, usually with a short summary containing the document's title and sometimes parts of the text. The index is built from the information stored with the data and the method by which the information is indexed. Unfortunately, there are currently no known public search engines that allow documents to be searched by date. Most search engines support the use of the boolean operators AND, OR and NOT to further specify the search query. Boolean operators are for literal searches that allow the user to refine and extend the terms of the search. The engine looks for the words or phrases exactly as entered. Some search engines provide an advanced feature called proximity search which allows users to define the distance between keywords. There is also concept-based searching where the research involves using statistical analysis on pages containing the words or phrases you search for. As well, natural language queries allow the user to type a question in the same form one would ask it to a human. A site like this would be ask.com.
The usefulness of a search engine depends on the relevance of the result set it gives back. While there may be millions of web pages that include a particular word or phrase, some pages may be more relevant, popular, or authoritative than others. Most search engines employ methods to rank the results to provide the "best" results first. How a search engine decides which pages are the best matches, and what order the results should be shown in, varies widely from one engine to another. The methods also change over time as Internet usage changes and new techniques evolve. There are two main types of search engine that have evolved: one is a system of predefined and hierarchically ordered keywords that humans have programmed extensively. The other is a system that generates an "inverted index" by analyzing texts it locates. This second form relies much more heavily on the computer itself to do the bulk of the work.
Most Web search engines are commercial ventures supported by advertising revenue and, as a result, some employ the practice of allowing advertisers to pay money to have their listings ranked higher in search results. Those search engines which do not accept money for their search engine results make money by running search related ads alongside the regular search engine results. The search engines make money every time someone clicks on one of these ads.
Search engine Market share in May 2011 Market share in December 2010[10] Google 82.80% 84.65% Yahoo! 6.42% 6.69% Baidu 4.89% 3.39% Bing 3.91% 3.29% Ask 0.52% 0.56% AOL 0.36% 0.42% Google's worldwide market share peaked at 86.3% in April 2010.[11] Yahoo!, Bing and other search engines are more popular in the US than in Europe.
In the People's Republic of China, Baidu held a 61.6% market share for web search in July 2009.[12]
An Experian Hitwise report released in August 2011 gave the "success rate" of searches sampled in July. Over 80 percent of Yahoo! and Bing searches resulted in the users visiting a web site, while Google's rate was just under 68 percent.[13]
Search engine bias
Although search engines are programmed to rank websites based on their popularity and relevancy, empirical studies indicate various political, economic, and social biases in the information they provide.[14][15] These biases could be a direct result of economic and commercial processes (e.g., companies that advertise with a search engine can become also more popular in its organic search results), and political processes (e.g., the removal of search results in order to comply with local laws).[16] Google Bombing is one example of an attempt to manipulate search results for political, social or commercial reasons.
See also
- List of search engines
- Answer engine (question answering)
- Quora
- True Knowledge
- Wolfram Alpha
- Collaborative search engine
- Enterprise search
- Google effect
- Internet Search Engines and Libraries
- Metasearch engine
- Natural language search engine
- OpenSearch
- Search directory
- Search engine marketing
- Search engine optimization
- Search oriented architecture
- Selection-based search
- Semantic Web
- Social engine
- Social search
- Spell checker
- Web indexing
- Web search query
- Website Parse Template
References
- ^ "Top 5 Search Engines from Oct to Dec 10". StatCounter. http://gs.statcounter.com/#search_engine-ww-monthly-201010-201012. Retrieved 17 January 2011.
- ^ World-Wide Web Servers
- ^ What's New! February 1994
- ^ "Internet History - Search Engines" (from Search Engine Watch), Universiteit Leiden, Netherlands, September 2001, web: LeidenU-Archie.
- ^ Oscar Nierstrasz (2 September 1993). "Searchable Catalog of WWW Resources (experimental)". http://groups.google.com/group/comp.infosystems.www/browse_thread/thread/2176526a36dc8bd3/2718fd17812937ac?hl=en&lnk=gst&q=Oscar+Nierstrasz#2718fd17812937ac.
- ^ Archive of NCSA what's new in December 1993 page
- ^ "Yahoo! And Netscape Ink International Distribution Deal". http://files.shareholder.com/downloads/YHOO/701084386x0x27155/9a3b5ed8-9e84-4cba-a1e5-77a3dc606566/YHOO_News_1997_7_8_General.pdf
- ^ Browser Deals Push Netscape Stock Up 7.8%. Los Angeles Times. 1 April 1996. http://articles.latimes.com/1996-04-01/business/fi-53780_1_netscape-home
- ^ Gandal, Neil (2001). "The dynamics of competition in the internet search engine market". International Journal of Industrial Organization 19 (7): 1103–1117. doi:10.1016/S0167-7187(01)00065-0.
- ^ Net Marketshare - World
- ^ Net Marketshare - Google
- ^ Search Engine Market Share July 2009 | Rise to the Top Blog
- ^ "Google Remains Ahead of Bing, But Relevance Drops". August 12, 2011. http://news.yahoo.com/google-remains-ahead-bing-relevance-drops-210457139.html.
- ^ Segev, Elad (2010). Google and the Digital Divide: The Biases of Online Knowledge, Oxford: Chandos Publishing.
- ^ Vaughan, L. & Thelwall, M. (2004). Search engine coverage bias: evidence and possible causes, Information Processing & Management, 40(4), 693-707.
- ^ Berkman Center for Internet & Society (2002), “Replacement of Google with Alternative Search Systems in China: Documentation and Screen Shots”, Harvard Law School.
- GBMW: Reports of 30-day punishment, re: Car maker BMW had its German website bmw.de delisted from Google, such as: Slashdot-BMW (05-Feb-2006).
- INSIZ: Maximum size of webpages indexed by MSN/Google/Yahoo! ("100-kb limit"): Max Page-size (28-Apr-2006).
Further reading
- For a more detailed history of early search engines, see Search Engine Birthdays (from Search Engine Watch), Chris Sherman, September 2003.
- Steve Lawrence; C. Lee Giles (1999). "Accessibility of information on the web". Nature 400 (6740): 107–9. doi:10.1038/21987. PMID 10428673.
- Bing Liu (2007), Web Data Mining: Exploring Hyperlinks, Contents and Usage Data. Springer, ISBN 3540378812
- Bar-Ilan, J. (2004). The use of Web search engines in information science research. ARIST, 38, 231-288.
- Levene, Mark (2005). An Introduction to Search Engines and Web Navigation. Pearson.
- Hock, Randolph (2007). The Extreme Searcher's Handbook. ISBN 978-0-910965-76-7
- Javed Mostafa (February 2005). "Seeking Better Web Searches". Scientific American Magazine. http://www.sciam.com/article.cfm?articleID=0006304A-37F4-11E8-B7F483414B7F0000.[dead link]
- Ross, Nancy; Wolfram, Dietmar (2000). "End user searching on the Internet: An analysis of term pair topics submitted to the Excite search engine". Journal of the American Society for Information Science 51 (10): 949–958. doi:10.1002/1097-4571(2000)51:10<949::AID-ASI70>3.0.CO;2-5.
- Xie, M. et al. (1998). "Quality dimensions of Internet search engines". Journal of Information Science 24 (5): 365–372. doi:10.1177/016555159802400509.
- Information Retrieval: Implementing and Evaluating Search Engines. MIT Press. 2010. http://www.ir.uwaterloo.ca/book/.
External links
Tools Local search · Vertical search · Search engine marketing · Search engine optimization · Search oriented architecture · Selection-based search · Social search · Document retrieval · Text mining · Web crawler · Multisearch · Federated search · Search aggregator · Index/Web indexing · Focused crawler · Spider trap · Robots exclusion standard · Distributed web crawling · Web archiving · Website mirroring software · Web search query · Voice search · Human flesh search engine · Natural language search engine · Web query classificationApplications Protocols and standards Z39.50 · Search/Retrieve Web Service · Search/Retrieve via URL · OpenSearch · Representational State Transfer · Website Parse Template · Wide Area Information ServersSee also Categories:- Information retrieval
- Internet search engines
- Internet terminology
- History of the Internet


Wikimedia Foundation. 2010.