- Depth-first search
-
Depth-first search Order in which the nodes are visited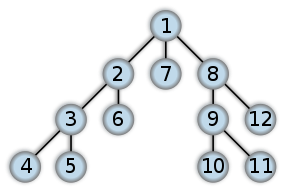
Class Search algorithm Data structure Graph Worst case performance O( | V | + | E | ) for explicit graphs traversed without repetition, O(bd) for implicit graphs with branching factor b searched to depth d Worst case space complexity O( | V | ) if entire graph is traversed without repetition, O(longest path length searched) for implicit graphs without elimination of duplicate nodes Graph and tree
search algorithmsAlpha-beta pruning
A*
B*
Beam
Bellman–Ford algorithm
Best-first
Bidirectional
Breadth-first
D*
Depth-first
Depth-limited
Dijkstra's algorithm
Floyd–Warshall algorithm
Hill climbing
Iterative deepening depth-first Johnson's algorithm
Lexicographic breadth-first
Uniform-cost
moreRelated topics Dynamic programming
Search gamesDepth-first search (DFS) is an algorithm for traversing or searching a tree, tree structure, or graph. One starts at the root (selecting some node as the root in the graph case) and explores as far as possible along each branch before backtracking.
A version of depth-first search was investigated in the 19th century by French mathematician Charles Pierre Trémaux as a strategy for solving mazes.[1][2]
Contents
Formal definition
Formally, DFS is an uninformed search that progresses by expanding the first child node of the search tree that appears and thus going deeper and deeper until a goal node is found, or until it hits a node that has no children. Then the search backtracks, returning to the most recent node it hasn't finished exploring. In a non-recursive implementation, all freshly expanded nodes are added to a stack for exploration.
Properties
The time and space analysis of DFS differs according to its application area. In theoretical computer science, DFS is typically used to traverse an entire graph, and takes time O(|V| + |E|), linear in the size of the graph. In these applications it also uses space O(|V|) in the worst case to store the stack of vertices on the current search path as well as the set of already-visited vertices. Thus, in this setting, the time and space bounds are the same as for breadth-first search and the choice of which of these two algorithms to use depends less on their complexity and more on the different properties of the vertex orderings the two algorithms produce.
For applications of DFS to search problems in artificial intelligence, however, the graph to be searched is often either too large to visit in its entirety or even infinite, and DFS may suffer from non-termination when the length of a path in the search tree is infinite. Therefore, the search is only performed to a limited depth, and due to limited memory availability one typically does not use data structures that keep track of the set of all previously visited vertices. In this case, the time is still linear in the number of expanded vertices and edges (although this number is not the same as the size of the entire graph because some vertices may be searched more than once and others not at all) but the space complexity of this variant of DFS is only proportional to the depth limit, much smaller than the space needed for searching to the same depth using breadth-first search. For such applications, DFS also lends itself much better to heuristic methods of choosing a likely-looking branch. When an appropriate depth limit is not known a priori, iterative deepening depth-first search applies DFS repeatedly with a sequence of increasing limits; in the artificial intelligence mode of analysis, with a branching factor greater than one, iterative deepening increases the running time by only a constant factor over the case in which the correct depth limit is known due to the geometric growth of the number of nodes per level.
Example
For the following graph:
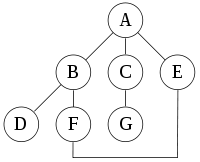
a depth-first search starting at A, assuming that the left edges in the shown graph are chosen before right edges, and assuming the search remembers previously-visited nodes and will not repeat them (since this is a small graph), will visit the nodes in the following order: A, B, D, F, E, C, G. The edges traversed in this search form a Trémaux tree, a structure with important applications in graph theory.
Performing the same search without remembering previously visited nodes results in visiting nodes in the order A, B, D, F, E, A, B, D, F, E, etc. forever, caught in the A, B, D, F, E cycle and never reaching C or G.
Iterative deepening is one technique to avoid this infinite loop and would reach all nodes.
Output of a depth-first search
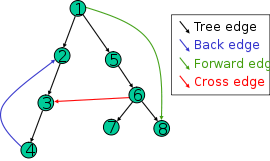 The four types of edges defined by a spanning tree
The four types of edges defined by a spanning tree
The most natural result of a depth first search of a graph (if it is considered as a function rather than a procedure) is a spanning tree of the vertices reached during the search. Based on this spanning tree, the edges of the original graph can be divided into three classes: forward edges (or "discovery edges"), which point from a node of the tree to one of its descendants, back edges, which point from a node to one of its ancestors, and cross edges, which do neither. Sometimes tree edges, edges which belong to the spanning tree itself, are classified separately from forward edges. It can be shown that if the original graph is undirected then all of its edges are tree edges or back edges.
Vertex orderings
It is also possible to use the depth-first search to linearly order the vertices of the original graph (or tree). There are three common ways of doing this:
- A preordering is a list of the vertices in the order that they were first visited by the depth-first search algorithm. This is a compact and natural way of describing the progress of the search, as was done earlier in this article. A preordering of an expression tree is the expression in Polish notation.
- A postordering is a list of the vertices in the order that they were last visited by the algorithm. A postordering of an expression tree is the expression in reverse Polish notation.
- A reverse postordering is the reverse of a postordering, i.e. a list of the vertices in the opposite order of their last visit. Reverse postordering is not the same as preordering. For example, when searching the directed graph
- beginning at node A, one visits the nodes in sequence, to produce lists either A B D B A C A, or A C D C A B A (depending upon whether the algorithm chooses to visit B or C first). Note that repeat visits in the form of backtracking to a node, to check if it has still unvisited neighbours, are included here (even if it is found to have none). Thus the possible preorderings are A B D C and A C D B (order by node's leftmost occurrence in above list), while the possible reverse postorderings are A C B D and A B C D (order by node's rightmost occurrence in above list). Reverse postordering produces a topological sorting of any directed acyclic graph. This ordering is also useful in control flow analysis as it often represents a natural linearization of the control flow. The graph above might represent the flow of control in a code fragment like
if (A) then { B } else { C } D- and it is natural to consider this code in the order A B C D or A C B D, but not natural to use the order A B D C or A C D B.
Pseudocode
Input: A graph G and a vertex v of G
Output: A labeling of the edges in the connected component of v as discovery edges and back edges
1 procedure DFS(G,v): 2 label v as explored 3 for all edges e in G.incidentEdges(v) do 4 if edge e is unexplored then 5 w ← G.opposite(v,e) 6 if vertex w is unexplored then 7 label e as a discovery edge 8 recursively call DFS(G,w) 9 else 10 label e as a back edge
Applications
Randomized algorithm similar to depth-first search used in generating a maze.Algorithms that use depth-first search as a building block include:
- Finding connected components.
- Topological sorting.
- Finding 2-(edge or vertex)-connected components.
- Finding 3-(edge or vertex)-connected components.
- Finding the bridges of a graph.
- Finding strongly connected components.
- Planarity Testing[3][4]
- Solving puzzles with only one solution, such as mazes. (DFS can be adapted to find all solutions to a maze by only including nodes on the current path in the visited set.)
- Maze generation may use a randomized depth-first search.
- Finding biconnectivity in graphs.
See also
- Breadth-first search
- Search games
Notes
- ^ Even, Shimon (2011), Graph Algorithms (2nd ed.), Cambridge University Press, pp. 46–48, ISBN 9780521736534, http://books.google.com/books?id=m3QTSMYm5rkC&pg=PA46.
- ^ Sedgewick, Robert (2002), Algorithms in C++: Graph Algorithms (3rd ed.), Pearson Education, ISBN 9780201361186.
- ^ Hopcroft, John; Tarjan, Robert E. (1974), "Efficient planarity testing", Journal of the Association for Computing Machinery 21 (4): 549–568, doi:10.1145/321850.321852.
- ^ de Fraysseix, H.; Ossona de Mendez, P.; Rosenstiehl, P. (2006), "Trémaux Trees and Planarity", International Journal of Foundations of Computer Science 17 (5): 1017–1030, doi:10.1142/S0129054106004248.
References
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Section 22.3: Depth-first search, pp. 540–549.
- Knuth, Donald E. (1997), The Art Of Computer Programming Vol 1. 3rd ed, Boston: Addison-Wesley, ISBN 0-201-89683-4, OCLC 155842391, http://www-cs-faculty.stanford.edu/~knuth/taocp.html
- Goodrich, Michael T. (2001), Algorithm Design: Foundations, Analysis, and Internet Examples, Wiley, ISBN 0471383651
External links
- Depth-First Explanation and Example
- C++ Boost Graph Library: Depth-First Search
- Depth-First Search Animation (for a directed graph)
- Depth First and Breadth First Search: Explanation and Code
- QuickGraph, depth first search example for .Net
- Depth-first search algorithm illustrated explanation (Java and C++ implementations)
- YAGSBPL - A template-based C++ library for graph search and planning
Categories:- Graph algorithms
- Search algorithms




Wikimedia Foundation. 2010.