- Data integration
-
Data integration involves combining data residing in different sources and providing users with a unified view of these data.[1] This process becomes significant in a variety of situations, which include both commercial (when two similar companies need to merge their databases) and scientific (combining research results from different bioinformatics repositories, for example) domains. Data integration appears with increasing frequency as the volume and the need to share existing data explodes.[2] It has become the focus of extensive theoretical work, and numerous open problems remain unsolved. In management circles, people frequently refer to data integration as "Enterprise Information Integration" (EII).
Contents
History
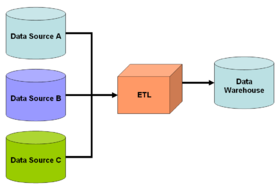 Figure 1: Simple schematic for a data warehouse. The ETL process extracts information from the source databases, transforms it and then loads it into the data warehouse.
Figure 1: Simple schematic for a data warehouse. The ETL process extracts information from the source databases, transforms it and then loads it into the data warehouse.
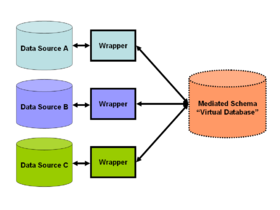 Figure 2: Simple schematic for a data-integration solution. A system designer constructs a mediated schema against which users can run queries. The virtual database interfaces with the source databases via wrapper code if required.
Figure 2: Simple schematic for a data-integration solution. A system designer constructs a mediated schema against which users can run queries. The virtual database interfaces with the source databases via wrapper code if required.Issues with combining heterogeneous data sources under a single query interface have existed for some time. The rapid adoption of databases after the 1960s naturally led to the need to share or to merge existing repositories. This merging can take place at several levels in the database architecture. One popular solution is implemented based on data warehousing (see figure 1). The warehouse system extracts, transforms, and loads data from heterogeneous sources into a single common queriable schema so data becomes compatible with each other. This approach offers a tightly coupled architecture because the data is already physically reconciled in a single repository at query-time, so it usually takes little time to resolve queries. However, problems arise with the "freshness" of data, which means information in warehouse is not always up-to-date. Therefore, when an original data source gets updated, the warehouse still retains outdated data and the ETL process needs re-execution for synchronization. Difficulties also arise in constructing data warehouses when one has only a query interface to summary data sources and no access to the full data. This problem frequently emerges when integrating several commercial query services like travel or classified advertisement web applications.
As of 2009[update] the trend in data integration has favored loosening the coupling between data[citation needed] and providing a unified query-interface to access real time data over a mediated schema (see figure 2), which makes information can be retrieved directly from original databases. This approach may need to specify mappings between the mediated schema and the schema of original sources, and transform a query into specialized queries to match the schema of the original databases. Therefore, this middleware architecture is also termed as "view-based query-answering" because each data source is represented as a view over the (nonexistent) mediated schema. Formally, computer scientists term such an approach "Local As View" (LAV) — where "Local" refers to the local sources/databases. An alternate model of integration has the mediated schema functioning as a view over the sources. This approach, called "Global As View" (GAV) — where "Global" refers to the global (mediated) schema — has attractions owing to the simplicity of answering queries by means of the mediated schema. However, it is necessary to reconstitute the view for the mediated schema whenever a new source gets integrated and/or an already integrated source modifies its schema.
As of 2010[update] some of the work in data integration research concerns the semantic integration problem. This problem addresses not the structuring of the architecture of the integration, but how to resolve semantic conflicts between heterogeneous data sources. For example if two companies merge their databases, certain concepts and definitions in their respective schemas like "earnings" inevitably have different meanings. In one database it may mean profits in dollars (a floating-point number), while in the other it might represent the number of sales (an integer). A common strategy for the resolution of such problems involves the use of ontologies which explicitly define schema terms and thus help to resolve semantic conflicts. This approach represents ontology-based data integration.
Example
Consider a web application where a user can query a variety of information about cities (such as crime statistics, weather, hotels, demographics, etc.). Traditionally, the information must be stored in a single database with a single schema. But any single enterprise would find information of this breadth somewhat difficult and expensive to collect. Even if the resources exist to gather the data, it would likely duplicate data in existing crime databases, weather websites, and census data.
A data-integration solution may address this problem by considering these external resources as materialized views over a virtual mediated schema, resulting in "virtual data integration". This means application-developers construct a virtual schema — the mediated schema — to best model the kinds of answers their users want. Next, they design "wrappers" or adapters for each data source, such as the crime database and weather website. These adapters simply transform the local query results (those returned by the respective websites or databases) into an easily processed form for the data integration solution (see figure 2). When an application-user queries the mediated schema, the data-integration solution transforms this query into appropriate queries over the respective data sources. Finally, the virtual database combines the results of these queries into the answer to the user's query.
This solution offers the convenience of adding new sources by simply constructing an adapter or an application software blade for them. It contrasts with ETL systems or with a single database solution, which require manual integration of entire new dataset into the system. The virtual ETL solutions leverage virtual mediated schema to implement data harmonization; whereby the data is copied from the designated "master" source to the defined targets, field by field. Advanced Data virtualization is also built on the concept of object-oriented modeling in order to construct virtual mediated schema or virtual metadata repository, using hub and spoke architecture.
Theory of data integration
The theory of data integration[1] forms a subset of database theory and formalizes the underlying concepts of the problem in first-order logic. Applying the theories gives indications as to the feasibility and difficulty of data integration. While its definitions may appear abstract, they have sufficient generality to accommodate all manner of integration systems.[citation needed]
Definitions
Data integration systems are formally defined as a triple
 where G is the global (or mediated) schema, S is the heterogeneous set of source schemas, and M is the mapping that maps queries between the source and the global schemas. Both G and S are expressed in languages over alphabets composed of symbols for each of their respective relations. The mapping M consists of assertions between queries over G and queries over S. When users pose queries over the data integration system, they pose queries over G and the mapping then asserts connections between the elements in the global schema and the source schemas.
where G is the global (or mediated) schema, S is the heterogeneous set of source schemas, and M is the mapping that maps queries between the source and the global schemas. Both G and S are expressed in languages over alphabets composed of symbols for each of their respective relations. The mapping M consists of assertions between queries over G and queries over S. When users pose queries over the data integration system, they pose queries over G and the mapping then asserts connections between the elements in the global schema and the source schemas.A database over a schema is defined as a set of sets, one for each relation (in a relational database). The database corresponding to the source schema S would comprise the set of sets of tuples for each of the heterogeneous data sources and is called the source database. Note that this single source database may actually represent a collection of disconnected databases. The database corresponding to the virtual mediated schema G is called the global database. The global database must satisfy the mapping M with respect to the source database. The legality of this mapping depends on the nature of the correspondence between G and S. Two popular ways to model this correspondence exist: Global as View or GAV and Local as View or LAV.
 Figure 3: Illustration of tuple space of the GAV and LAV mappings.[3] In GAV, the system is constrained to the set of tuples mapped by the mediators while the set of tuples expressible over the sources may be much larger and richer. In LAV, the system is constrained to the set of tuples in the sources while the set of tuples expressible over the global schema can be much larger. Therefore LAV systems must often deal with incomplete answers.
Figure 3: Illustration of tuple space of the GAV and LAV mappings.[3] In GAV, the system is constrained to the set of tuples mapped by the mediators while the set of tuples expressible over the sources may be much larger and richer. In LAV, the system is constrained to the set of tuples in the sources while the set of tuples expressible over the global schema can be much larger. Therefore LAV systems must often deal with incomplete answers.GAV systems model the global database as a set of views over S. In this case M associates to each element of G as a query over S. Query processing becomes a straightforward operation due to the well-defined associations between G and S. The burden of complexity falls on implementing mediator code instructing the data integration system exactly how to retrieve elements from the source databases. If any new sources join the system, considerable effort may be necessary to update the mediator, thus the GAV approach appears preferable when the sources seem unlikely to change.
In a GAV approach to the example data integration system above, the system designer would first develop mediators for each of the city information sources and then design the global schema around these mediators. For example, consider if one of the sources served a weather website. The designer would likely then add a corresponding element for weather to the global schema. Then the bulk of effort concentrates on writing the proper mediator code that will transform predicates on weather into a query over the weather website. This effort can become complex if some other source also relates to weather, because the designer may need to write code to properly combine the results from the two sources.
On the other hand, in LAV, the source database is modeled as a set of views over G. In this case M associates to each element of S a query over G. Here the exact associations between G and S are no longer well-defined. As is illustrated in the next section, the burden of determining how to retrieve elements from the sources is placed on the query processor. The benefit of an LAV modeling is that new sources can be added with far less work than in a GAV system, thus the LAV approach should be favored in cases where the mediated schema is more stable and unlikely to change.[1]
In an LAV approach to the example data integration system above, the system designer designs the global schema first and then simply inputs the schemas of the respective city information sources. Consider again if one of the sources serves a weather website. The designer would add corresponding elements for weather to the global schema only if none existed already. Then programmers write an adapter or wrapper for the website and add a schema description of the website's results to the source schemas. The complexity of adding the new source moves from the designer to the query processor.
Query processing
The theory of query processing in data integration systems is commonly expressed using conjunctive queries.[4] One can loosely think of a conjunctive query as a logical function applied to the relations of a database such as "f(A,B) where A < B". If a tuple or set of tuples is substituted into the rule and satisfies it (makes it true), then we consider that tuple as part of the set of answers in the query. While formal languages like Datalog express these queries concisely and without ambiguity, common SQL queries count as conjunctive queries as well.
In terms of data integration, "query containment" represents an important property of conjunctive queries. A query A contains another query B (denoted
 ) if the results of applying B are a subset of the results of applying A for any database. The two queries are said to be equivalent if the resulting sets are equal for any database. This is important because in both GAV and LAV systems, a user poses conjunctive queries over a virtual schema represented by a set of views, or "materialized" conjunctive queries. Integration seeks to rewrite the queries represented by the views to make their results equivalent or maximally contained by our user's query. This corresponds to the problem of answering queries using views (AQUV).[5]
) if the results of applying B are a subset of the results of applying A for any database. The two queries are said to be equivalent if the resulting sets are equal for any database. This is important because in both GAV and LAV systems, a user poses conjunctive queries over a virtual schema represented by a set of views, or "materialized" conjunctive queries. Integration seeks to rewrite the queries represented by the views to make their results equivalent or maximally contained by our user's query. This corresponds to the problem of answering queries using views (AQUV).[5]In GAV systems, a system designer writes mediator code to define the query-rewriting. Each element in the user's query corresponds to a substitution rule just as each element in the global schema corresponds to a query over the source. Query processing simply expands the subgoals of the user's query according to the rule specified in the mediator and thus the resulting query is likely to be equivalent. While the designer does the majority of the work beforehand, some GAV systems such as Tsimmis involve simplifying the mediator description process.
In LAV systems, queries undergo a more radical process of rewriting because no mediator exists to align the user's query with a simple expansion strategy. The integration system must execute a search over the space of possible queries in order to find the best rewrite. The resulting rewrite may not be an equivalent query but maximally contained, and the resulting tuples may be incomplete. As of 2009[update] the MiniCon algorithm[5] is the leading query rewriting algorithm for LAV data integration systems.
In general, the complexity of query rewriting is NP-complete.[5] If the space of rewrites is relatively small this does not pose a problem — even for integration systems with hundreds of sources.
Data Integration in the Life Sciences
Large-scale questions in science, such as global warming, invasive species spread, and resource depletion, are increasingly requiring the collection of disparate data sets for meta-analysis. This type of data integration is especially challenging for ecological and environmental data because metadata standards are not agreed upon and there are many different data types produced in these fields. National Science Foundation initiatives such as Datanet are intended to make data integration easier for scientists by providing cyberinfrastructure and setting standards. The two funded Datanet initiatives are DataONE and the Data Conservancy.
See also
- Business semantics management
- Core data integration
- Customer data integration
- Data curation
- Database model
- Data fusion
- Data mapping
- Dataspaces
- Data virtualization
- Data Warehousing
- Enterprise Architecture framework
- Edge data integration
- Enterprise application integration
- Enterprise Information Integration (EII)
- Enterprise integration
- Extract, transform, load
- Geodi: Geoscientific Data Integration
- Information integration
- Information Server
- Integration Competency Center
- Integration Consortium
- Jitterbit: a open-source software
- JXTA
- Master data management
- Object-relational mapping
- Ontology based data integration
- Open Text
- Schema Matching
- Semantic Integration
- SQL
- Three schema approach
- UDEF
- Web service
References
- ^ a b c Maurizio Lenzerini (2002). "Data Integration: A Theoretical Perspective". PODS 2002. pp. 233–246. http://www.dis.uniroma1.it/~lenzerin/homepagine/talks/TutorialPODS02.pdf.
- ^ Frederick Lane (2006). IDC: World Created 161 Billion Gigs of Data in 2006 "IDC: World Created 161 Billion Gigs of Data in 2006". http://www.toptechnews.com/story.xhtml?story_id=01300000E3D0&full_skip=1 IDC: World Created 161 Billion Gigs of Data in 2006.
- ^ Christoph Koch (2001). Data Integration against Multiple Evolving Autonomous Schemata. http://www.csd.uoc.gr/~hy562/Papers/thesis_final.pdf.
- ^ Jeffrey D. Ullman (1997). "Information Integration Using Logical Views". ICDT 1997. pp. 19–40. http://www-db.stanford.edu/pub/papers/integration-using-views.ps.
- ^ a b c Alon Y. Halevy (2001). "Answering queries using views: A survey". The VLDB Journal. pp. 270–294. http://www.cs.uwaterloo.ca/~david/cs740/answering-queries-using-views.pdf.
Categories:

Wikimedia Foundation. 2010.