- Serializability
-
In concurrency control of databases,[1][2] transaction processing (transaction management), and various transactional applications (e.g., transactional memory[3] and software transactional memory), both centralized and distributed, a transaction schedule (history) is serializable, has the serializability property, if its outcome (e.g., the resulting database state, the values of the database's data) is equal to the outcome of its transactions executed serially, i.e., sequentially without overlapping in time. Transactions are normally executed concurrently (they overlap), since this is the most efficient way. Serializability is the major correctness criterion for concurrent transactions' executions. It is considered the highest level of isolation between transactions, and plays an essential role in concurrency control. As such it is supported in all general purpose database systems. Strong strict two-phase locking (SS2PL) is a popular serializability mechanism utilized in most of the database systems (in various variants) since their early days in the 1970s.
Distributed serializability is the serializability of a schedule of a transactional distributed system (e.g., a distributed database system). With the proliferation of the Internet, Cloud computing, Grid computing, and small, portable, powerful computing devices (e.g., smartphones) the need for effective distributed serializability techniques to ensure correctness in, and among distributed applications seems to increase. Commitment ordering[4][5][6][7] (or Commit ordering; CO; introduced publicly in 1991) is a general serializability technique that allows to effectively achieve distributed serializability (and Global serializability) across different (any) concurrency control mechanisms, also in a mixed heterogeneous environment with different mechanisms. CO does not interfere with the mechanisms' operations, and also guarantees automatic distributed deadlock resolution. Unlike other distributed serializability mechanisms, CO does not require the (costly) distribution of local concurrency control information (e.g., local precedence relations, locks, timestamps, or tickets), a fact which provides scalability, and typically saves considerable overhead and delays. Thus, CO (including its variants, e.g., SS2PL) is the only known effective general method for distributed serializability (and it is probably the only existing one). It also allows the effective distribution of all other known concurrency control mechanisms. The popular SS2PL, which is a special case of CO and inherits many of CO's qualities, is the de-facto standard for distributed serializability (and Global serializability) across multiple (SS2PL based) database systems since the 1980s.[4] CO has been utilized extensively since 1997 as a solution for distributed serializability in works on transactional processes, [8][9] and more recently an optimistic version of CO has been proposed as a solution for Grid computing[10] and Cloud computing.[11]
Serializability theory provides the formal framework to reason about and analyze serializability and its techniques. Though it is mathematical in nature, its fundamentals are informally (without Mathematics notation) introduced below.
Contents
Database transaction
Main article: Database transactionFor this discussion a database transaction is a specific intended run (with specific parameters, e.g., with transaction identification, at least) of a computer program (or programs) that accesses a database (or databases). Such a program is written with the assumption that it is running in isolation from other executing programs, i.e., when running, its accessed data (after the access) are not changed by other running programs. Without this assumption the transaction's results are unpredictable and can be wrong. The same transaction can be executed in different situations, e.g., in different times and locations, in parallel with different programs. A live transaction (i.e., exists in a computing environment with already allocated computing resources; to distinguish from a transaction request, waiting to get execution resources) can be in one of three states, or phases:
- Running - Its program(s) is (are) executing.
- Ready - Its program's execution has ended, and it is waiting to be Ended (Completed).
- Ended (or Completed) - It is either Committed or Aborted (Rolled-back), depending whether the execution is considered a success or not, respectively . When committed, all its recoverable (i.e., with states that can be controlled for this purpose), durable resources (typically database data) are put in their final states, states after running. When aborted, all its recoverable resources are put back in their initial states, as before running.
A failure in transaction's computing environment before ending typically results in its abort. However, a transaction may be aborted also for other reasons as well (e.g., see below).
Upon being ended (completed), transaction's allocated computing resources are released and the transaction disappears from the computing environment. However, the effects of a committed transaction remain in the database, while the effects of an aborted (rolled-back) transaction disappear from the database. The concept of atomic transaction ("all or nothing" semantics) was designed to exactly achieve this behavior, in order to control correctness in complex faulty systems.
Correctness
Correctness - serializability
Serializability is a property of a transaction schedule (history). It relates to the isolation property of a database transaction.
- Serializability of a schedule means equivalence (in the outcome, the database state, data values) to a serial schedule (i.e., sequential with no transaction overlap in time) with the same transactions. It is the major criterion for the correctness of concurrent transactions' schedule, and thus supported in all general purpose database systems.
- The rationale behind serializability is the following:
- If each transaction is correct by itself, i.e., meets certain integrity conditions, then a schedule that comprises any serial execution of these transactions is correct (its transactions still meet their conditions): "Serial" means that transactions do not overlap in time and cannot interfere with each other, i.e, complete isolation between each other exists. Any order of the transactions is legitimate, if no dependencies among them exist, which is assumed (see comment below). As a result, a schedule that comprises any execution (not necessarily serial) that is equivalent (in its outcome) to any serial execution of these transactions, is correct.
Schedules that are not serializable are likely to generate erroneous outcomes. Well known examples are with transactions that debit and credit accounts with money: If the related schedules are not serializable, then the total sum of money may not be preserved. Money could disappear, or be generated from nowhere. This and violations of possibly needed other invariant preservations are caused by one transaction writing, and "stepping on" and erasing what has been written by another transaction before it has become permanent in the database. It does not happen if serializability is maintained.
If any specific order between some transactions is requested by an application, then it is enforced independently of the underlying serializability mechanisms. These mechanisms are typically indifferent to any specific order, and generate some unpredictable partial order that is typically compatible with multiple serial orders of these transactions. This partial order results from the scheduling orders of concurrent transactions' data access operations, which depend on many factors.
Correctness - recoverability
A major characteristic of a database transaction is atomicity, which means that it either commits, i.e., all its operations' results take effect in the database, or aborts (rolled-back), all its operations' results do not have any effect on the database ("all or nothing" semantics of a transaction). In all real systems transactions can abort for many reasons, and serializability by itself is not sufficient for correctness. Schedules also need to possess the recoverability (from abort) property. Recoverability means that committed transactions have not read data written by aborted transactions (whose effects do not exist in the resulting database states). While serializability is currently compromised on purpose in many applications for better performance (only in cases when application's correctness is not harmed), compromising recoverability would quickly violate the database's integrity, as well as that of transactions' results external to the database. A schedule with the recoverability property (a recoverable schedule) "recovers" from aborts by itself, i.e., aborts do not harm the integrity of its committed transactions and resulting database. This is untrue without recoverability where the likely integrity violations (resulting incorrect database data) need special, typically manual, corrective actions in the database.
Implementing recoverability in its general form may result in cascading aborts: Aborting one transaction may result in a need to abort a second transaction, and then a third, and so on. This results in a waste of already partially executed transactions, and may result also in a performance penalty. Avoiding cascading aborts (ACA, or Cascadelessness) is a special case of recoverability that exactly prevents such phenomenon. Often in practice a special case of ACA is utilized: Strictness. Strictness allows an efficient database recovery from failure.
Note that the recoverability property is needed even if no database failure occurs and no database recovery from failure is needed. It is rather needed to correctly automatically handle aborts, which may be unrelated to database failure and recovery from failure.
Relaxing serializability
In many applications, unlike with finances, absolute correctness is not needed. For example, when retrieving a list of products according to specification, in most cases it does not matter much if a product, whose data was updated a short time ago, does not appear in the list, even if it meets the specification. It will typically appear in such a list when tried again a short time later. Commercial databases provide concurrency control with a whole range of isolation levels which are in fact (controlled) serializability violations in order to achieve higher performance. Higher performance means better transaction execution rate and shorter average transaction response time (transaction duration). Snapshot isolation is an example of a popular, widely utilized efficient relaxed serializability method with many characteristics of full serializability, but still short of some, and unfit in many situations.
Another common reason nowadays for (distributed; see below) serializability relaxation is the requirement of availability of internet products and services. This requirement is typically answered by large scale data replication. The straightforward solution for synchronizing replicas' updates of a same database object is including all these updates in a single atomic distributed transaction. However, with many replicas such a transaction is very large, and may span several computers and networks that some of them are likely to be unavailable. Thus such a transaction is likely to end with abort and miss its purpose.[12] Consequently Optimistic replication (Lazy replication) is often utilized (e.g., in many products and services by Google, Amazon, Yahoo, and alike), while serializability is relaxed and compromised for Eventual consistency. Again in this case, relaxation is done only for applications that are not expected to be harmed by this.
Classes of schedules defined by relaxed serializability properties either contain the serializability class, or are incomparable with it.
View and conflict serializability
Mechanisms that enforce serializability need to execute in real time, or almost in real time, while transactions are running at high rates. In order to meet this requirement special cases of serializability, sufficient conditions for serializability which can be enforced effectively, are utilized.
Two major types of serializability exist: view-serializability, and conflict-serializability. View-serializability matches the general definition of serializability given above. Conflict-serializability is a broad special case, i.e., any schedule that is conflict-serializable is also view-serializable, but not necessarily the opposite. Conflict-serializability is widely utilized because it is easier to determine and covers a substantial portion of the view-serializable schedules. Determining view-serializability of a schedule is an NP-complete problem (a class of problems with only difficult-to-compute, excessively time-consuming known solutions).
- View-serializability of a schedule is defined by equivalence to a serial schedule (no overlapping transactions) with the same transactions, such that respective transactions in the two schedules read and write the same data values ("view" the same data values).
- Conflict-serializability is defined by equivalence to a serial schedule (no overlapping transactions) with the same transactions, such that both schedules have the same sets of respective chronologically-ordered pairs of conflicting operations (same precedence relations of respective conflicting operations).
Operations upon data are read or write (a write: either insert or modify or delete). Two operations are conflicting, if they are of different transactions, upon the same datum (data item), and at least one of them is write. Each such pair of conflicting operations has a conflict type: It is either a read-write, or write-read, or a write-write conflict. The transaction of the second operation in the pair is said to be in conflict with the transaction of the first operation. A more general definition of conflicting operations (also for complex operations, which may consist each of several "simple" read/write operations) requires that they are noncommutative (changing their order also changes their combined result). Each such operation needs to be atomic by itself (by proper system support) in order to be considered an operation for a commutativity check. For example, read-read operations are commutative (unlike read-write and the other possibilities) and thus rear-read is not a conflict. Another more complex example: the operations increment and decrement of a counter are both write operations (both modify the counter), but do not need to be considered conflicting (write-write conflict type) since they are commutative (thus increment-decrement is not a conflict; e.g., already has been supported in the old IBM's IMS "fast path"). Only precedence (time order) in pairs of conflicting (non-commutative) operations is important when checking equivalence to a serial schedule, since different schedules consisting of the same transactions can be transformed from one to another by changing orders between different transactions' operations (different transactions' interleaving), and since changing orders of commutative operations (non-conflicting) does not change an overall operation sequence result, i.e., a schedule outcome (the outcome is preserved through order change between non-conflicting operations, but typically not when conflicting operations change order). This means that if a schedule can be transformed to any serial schedule without changing orders of conflicting operations (but changing orders of non-conflicting, while preserving operation order inside each transaction), then the outcome of both schedules is the same, and the schedule is conflict-serializable by definition.
Conflicts are the reason for blocking transactions and delays (non-materialized conflicts), or for aborting transactions due to serializability violations prevention. Both possibilities reduce performance. Thus reducing the number of conflicts, e.g., by commutativity (when possible), is a way to increase performance.
A transaction can issue/request a conflicting operation and be in conflict with another transaction while its conflicting operation is delayed and not executed (e.g., blocked by a lock). Only executed (materialized) conflicting operations are relevant to conflict serializability (see more below).
Enforcing conflict serializability
Testing conflict serializability
Schedule compliance with conflict serializability can be tested with the precedence graph (serializability graph, serialization graph, conflict graph) for committed transactions of the schedule. It is the directed graph representing precedence of transactions in the schedule, as reflected by precedence of conflicting operations in the transactions.
- In the precedence graph transactions are nodes and precedence relations are directed edges. There exists an edge from a first transaction to a second transaction, if the second transaction is in conflict with the first (see Conflict serializability above), and the conflict is materialized (i.e., if the requested conflicting operation is actually executed: in many cases a requested/issued conflicting operation by a transaction is delayed and even never executed, typically by a lock on the operation's object, held by another transaction, or when writing to a transaction's temporary private workspace and materializing, copying to the database itself, upon commit; as long as a requested/issued conflicting operation is not executed upon the database itself, the conflict is non-materialized; non-materialized conflicts are not represented by an edge in the precedence graph).
- Comment: In many text books only committed transactions are included in the precedence graph. Here all transactions are included for convenience in later discussions.
The following observation is a key characterization of conflict serializability:
- A schedule is conflict-serializable if and only if its precedence graph of committed transactions (when only committed transactions are considered) is acyclic. This means that a cycle consisting of committed transactions only is generated in the (general) precedence graph, if and only if conflict-serializability is violated.
Cycles of committed transactions can be prevented by aborting an undecided (neither committed, nor aborted) transaction on each cycle in the precedence graph of all the transactions, which can otherwise turn into a cycle of committed transactions (and a committed transaction cannot be aborted). One transaction aborted per cycle is both required and sufficient number to break and eliminate the cycle (more aborts are possible, and can happen in some mechanisms, but unnecessary for serializability). The probability of cycle generation is typically low, but nevertheless, such a situation is carefully handled, typically with a considerable overhead, since correctness is involved. Transactions aborted due to serializability violation prevention are restarted and executed again immediately.
Serializability enforcing mechanisms typically do not maintain a precedence graph as a data structure, but rather prevent or break cycles implicitly (e.g., SS2PL below).
Common mechanism - SS2PL
Main article: Two-phase lockingStrong strict two phase locking (SS2PL) is a common mechanism utilized in database systems since their early days in the 1970s (the "SS" in the name SS2PL is newer though) to enforce both conflict serializability and strictness (a special case of recoverability which allows effective database recovery from failure) of a schedule. In this mechanism each datum is locked by a transaction before accessing it (any read or write operation): The item is marked by, associated with a lock of a certain type, depending on operation (and the specific implementation; various models with different lock types exist; in some models locks may change type during the transaction's life). As a result access by another transaction may be blocked, typically upon a conflict (the lock delays or completely prevents the conflict from being materialized and be reflected in the precedence graph by blocking the conflicting operation), depending on lock type and the other transaction's access operation type. Employing an SS2PL mechanism means that all locks on data on behalf of a transaction are released only after the transaction has ended (either committed or aborted).
SS2PL is the name of the resulting schedule property as well, which is also called rigorousness. SS2PL is a special case (proper subset) of both Two-phase locking (2PL) and Commitment ordering (CO; see Other enforcing techniques below).
Mutual blocking between transactions results in a deadlock, where execution of these transactions is stalled, and no completion can be reached. Thus deadlocks need to be resolved to complete these transactions' execution and release related computing resources. A deadlock is a reflection of a potential cycle in the precedence graph, that would occur without the blocking when conflicts are materialized. A deadlock is resolved by aborting a transaction involved with such potential cycle, and breaking the cycle. It is often detected using a wait-for graph (a graph of conflicts blocked by locks from being materialized; it can be also defined as the graph of non-materialized conflicts; conflicts not materialized are not reflected in the precedence graph and do not affect serializability), which indicates which transaction is "waiting for" lock release by which transaction, and a cycle means a deadlock. Aborting one transaction per cycle is sufficient to break the cycle. Transactions aborted due to deadlock resolution are restarted and executed again immediately.
Other enforcing techniques
Other known mechanisms include:
- Precedence graph (or Serializability graph, Conflict graph) cycle elimination
- Two-phase locking (2PL)
- Timestamp ordering (TO)
- (Local) commitment ordering[4] (CO)
- Serializable snapshot isolation[13] (SerializableSI)
The above (conflict) serializability techniques in their general form do not provide recoverability. Special enhancements are needed for adding recoverability.
Optimistic versus pessimistic techniques
Concurrency control techniques are of three major types:
- Pessimistic: In Pessimistic concurrency control a transaction blocks data access operations of other transactions upon conflicts, and conflicts are non-materialized until blocking is removed. This to ensure that operations that may violate serializability (and in practice also recoverability) do not occur.
- Optimistic: In Optimistic concurrency control data access operations of other transactions are not blocked upon conflicts, and conflicts are immediately materialized. When the transaction reaches the ready state, i.e., its running state has been completed, possible serializability (and in practice also recoverability) violation by the transaction's operations (relatively to other running transactions) is checked: If violation has occurred, the transaction is typically aborted (sometimes aborting another transaction to handle serializability violation is preferred). Otherwise it is committed.
- Semi-optimistic: Mechanisms that mix blocking in certain situations with not blocking in other situations and employ both materialized and non-materialized conflicts (e.g., Strict CO (SCO)).
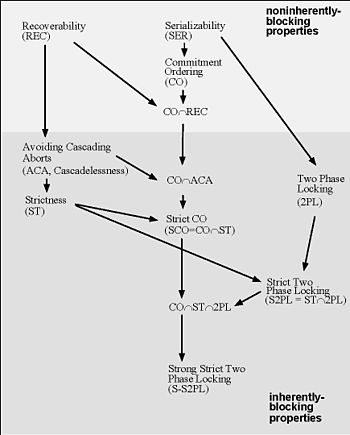 Schedule classes containment: An arrow from class A to class B indicates that class A strictly contains B; a lack of a directed path between classes means that the classes are incomparable. A property is inherently-blocking, if it can be enforced only by blocking transaction’s data access operations until certain events occur in other transactions (Raz 1992).[4]
Schedule classes containment: An arrow from class A to class B indicates that class A strictly contains B; a lack of a directed path between classes means that the classes are incomparable. A property is inherently-blocking, if it can be enforced only by blocking transaction’s data access operations until certain events occur in other transactions (Raz 1992).[4]
The main differences between the technique types is the conflict types that are generated by them. A pessimistic method blocks a transaction operation upon conflict and generates a non-materialized conflict, while an optimistic method does not block and generates a materialized conflict. A semi-optimistic method generates both conflict types. Both conflict types are generated by the chronological orders transaction operations are invoked, independently of the type of conflict. A cycle of committed transactions (with materialized conflicts) in the precedence graph (conflict graph) represents a serializability violation, and should be avoided for maintaining serializability. A cycle of (non-materialized) conflicts in the wait-for graph represents a deadlock situation, which should be resolved by breaking the cycle. Both cycle types result from conflicts, and should be broken. At any technique type conflicts should be detected and considered, with similar overhead for both materialized and non-materialized conflicts (typically by using mechanisms like locking, while either blocking for locks, or not blocking but recording conflict for materialized conflicts). In a blocking method typically a context switching occurs upon conflict, with (additional) incurred overhead. Otherwise blocked transactions' related computing resources remain idle, unutilized, which may be a worse alternative. When conflicts do not occur frequently, optimistic methods typically have an advantage. With different transactions loads (mixes of transaction types) one technique type (i.e., either optimistic or pessimistic) may provide better performance than the other.
Unless schedule classes are inherently blocking (i.e., they cannot be implemented without data-access operations blocking; e.g., 2PL, SS2PL and SCO above; see chart), they can be implemented also using optimistic techniques (e.g., Serializability, Recoverability, and Commitment ordering).
Serializable multi-version concurrency control
- See also Multiversion concurrency control (partial coverage)
- and Making Snapshot Isolation Serializable in Snapshot isolation
Multi-version concurrency control (MVCC) is a common way today to increase concurrency and performance by generating a new version of a database object each time the object is written, and allowing transactions' read operations of several last relevant versions (of each object), depending on scheduling method. MVCC can be combined with all the serializability techniques listed above (except SerializableSI which is originally MVCC based). It is utilized in most general-purpose DBMS products.
MVCC is especially popular nowadays through the relaxed serializability (see above) method Snapshot isolation (SI) which provides better performance than most known serializability mechanisms (at the cost of possible serializability violation in certain cases). SerializableSI, which is an efficient enhancement of SI to make it serializable, is intended to provide an efficient serializable solution. SerializableSI has been analyzed[13][14] via a general theory of MVCC[15] developed for properly defining Multi-version Commitment ordering (MVCO). This theory (different from previous MVCC theories) includes single-version concurrency control theory (the usual) as a special case when the maximum number of versions of each database object is limited to one.
Multi-version Commitment ordering (MVCO),[15] the multi-version variant of Commitment ordering (CO), is another multi-version serializability technique (e.g., combining MVCO with SI results in COSI; performance of COSI has not yet been compared with that of SerializableSI) with the advantage of providing efficient Distributed serializability (see below; unlike SerializableSI for which efficient distribution is unknown and probably does not exist, since it is not MVCO compliant which is a necessary condition for guaranteeing global serializability across autonomous transactional objects).
Distributed serializability
Overview
Distributed serializability is the serializability of a schedule of a transactional distributed system (e.g., a distributed database system). Such system is characterized by distributed transactions (also called global transactions), i.e., transactions that span computer processes (a process abstraction in a general sense, depending on computing environment; e.g., operating system's thread) and possibly network nodes. A distributed transaction comprises more than one local sub-transactions that each has states as described above for a database transaction. A local sub-transaction comprises a single process, or more processes that typically fail together (e.g., in a single processor core). Distributed transactions imply a need in Atomic commitment protocol to reach consensus among its local sub-transactions on whether to commit or abort. Such protocols can vary from a simple (one-phase) hand-shake among processes that fail together, to more sophisticated protocols, like Two-phase commit, to handle more complicated cases of failure (e.g., process, node, communication, etc. failure). Distributed serializability is a major goal of distributed concurrency control for correctness. With the proliferation of the Internet, Cloud computing, Grid computing, and small, portable, powerful computing devices (e.g., smartphones) the need for effective distributed serializability techniques to ensure correctness in and among distributed applications seems to increase.
Distributed serializability is achieved by implementing distributed versions of the known centralized techniques.[1][2] Typically all such distributed versions require utilizing conflict information (either of materialized or non-materialized conflicts, or equivalently, transaction precedence or blocking information; conflict serializability is usually utilized) that is not generated locally, but rather in different processes, and remote locations. Thus information distribution is needed (e.g., precedence relations, lock information, timestamps, or tickets). When the distributed system is of a relatively small scale, and message delays across the system are small, the centralized concurrency control methods can be used unchanged, while certain processes or nodes in the system manage the related algorithms. However, in a large-scale system (e.g., Grid and Cloud), due to the distribution of such information, substantial performance penalty is typically incurred, even when distributed versions of the methods (Vs. centralized) are used, primarily due to computer and communication latency. Also, when such information is distributed, related techniques typically do not scale well. A well known example with scalability problems is a distributed lock manager, which distributes lock (non-materialized conflict) information across the distributed system to implement locking techniques. The only known exception, which needs only local information for its distributed version (to reach distributed serializability), and thus scales with no penalty and avoids concurrency control information distribution delays, is Commitment ordering (CO; including its many variants, e.g., SS2PL). CO can provide unbounded scalability within a single distributed database system, and also in a heterogeneous multidatabase system. It allows the effective distribution of all known concurrency control mechanisms, and also is effective in new experimental distributed database systems architectures, where local sub-transactions in each processor core are one-threaded and serial (i.e., with no concurrency), but the overall (distributed) schedule is serializable (e.g., as in H-Store[16] and VoltDB; see also Hypothetical Multi Single-Threaded Core (MuSiC) environment).
Distributed serializability and Commitment ordering
Main article: Commitment orderingCommitment ordering[4][5] (CO; or commit ordering, or commit-order-serializability) is a serializability technique, both centralized and distributed. CO is also the name of the resulting schedule property, defining a broad subclass of the Conflict serializability class of schedules. The most significant aspects of CO that make it a uniquely effective general distributed serializability solution are:
- Seamless, low overhead integration with any concurrency control mechanism, with neither changing or blocking any transaction's operation scheduling (thus allowing and keeping optimistic implementations), nor adding any new operation (like "Take timestamp" or "Take ticket"); but CO is also a standalone serializability mechanism.
- No need of conflict or equivalent information distribution (e.g., local precedence relations, locks, timestamps, or tickets).
- Automatic distributed deadlock resolution, and
- Scalability.
All these aspects, except the first, are also possessed by the popular SS2PL (see above), which is a special case of CO, but blocking and constrained.
Under certain general conditions distributed CO can be used effectively for guaranteeing distributed serializability without paying the penalty of distributing conflict information. This is a major distinguishing characteristic of distributed CO from other distributed serializability techniques. CO's net effect may be some commit delays (but no more added delay than that with its special cases, e.g., SS2PL, and on the average less). Instead of distributing conflict information, distributed CO utilizes (unmodified) messages of an atomic commitment protocol (e.g., the Two-phase commit protocol (2PC)), which are used at any case, also without CO. Such protocol is used to coordinate atomicity of distributed transactions, and is an essential component of any distributed transaction environment.
CO can be applied to many distributed transactional systems for guaranteeing distributed serializability. Three conditions should be met (which can be enforced in the design of most distributed transactional systems):
- Data partition: Recoverable data (transactional data, i.e., data under transactions' control (not to be confused with the Recoverability property of a schedule)) are partitioned among (possibly distributed) transactional data managers (also called resource managers) that the distributed system comprises, i.e., each recoverable datum (data item) is controlled by a single data manager (e.g., as common in a Shared nothing architecture).
- Participants in atomic commitment protocol: These data managers are the participants of the system's atomic commitment protocol(s) (this requirement is not necessarily met in general, but is quite common and not difficult to be imposed), and
- CO compliance: Each such data manager guarantees CO locally (i.e., has a CO compliant local schedule, which can be quite easily achieved, possibly alongside with any relevant concurrency control mechanism; nesting is possible: each data manager may be distributed with its own private, separate atomic commitment protocol).
These are conditions applied to the distributed system's transactional data managers (resource managers). Each data manager may implement (in principle, but not necessarily) a different concurrency control mechanism (combined with CO).
Distributed CO utilizes the (unmodified) atomic commitment protocol (ACP) messages without any additional information communicated. This applies also to SS2PL (see above), which is a locking based special case of CO, typically utilized also for distributed serializability, and thus, can be implemented in a distributed transactional system without a distributed lock manager, a fact that in many cases has been overlooked.
An important side-benefit of distributed CO is that distributed deadlocks (deadlocks which span each two or more transactional data managers) are automatically resolved by atomic commitment (including the special case of a completely SS2PL based distributed system; also this has not been noticed in any research article except the CO articles until today (2009)).
See more on distributed CO in Commitment ordering, especially in Distributed serializability and CO there, and below in the next sections.
Global serializability and Commitment ordering
Main article: Global serializabilityGuaranteeing distributed serializability in a heterogeneous system that comprises several transactional objects (i.e., with states controlled by atomic transactions; e.g., database systems) with different concurrency controls has been considered a difficult problem. In such system distributed serializability is usually called Global serializability (or Modular serializability: Also each object maintains serializability). For example, in a federated database system or any other more loosely defined multidatabase system, which are typically distributed in a communication network, transactions span multiple (and possibly distributed) databases. The database systems involved may utilize different concurrency control mechanism for serializability. However, even if every local schedule of a single database is serializable, the global schedule of the whole system is not necessarily serializable. The massive communication exchanges of conflict information needed between database systems to reach conflict serializability would lead to unacceptable performance, primarily due to computer and communication latency. The problem of achieving global serializability effectively in such heterogeneous systems had been characterized as open until the introduction of Commitment ordering (CO) in 1991. Even years after CO's introduction the problem has been considered unsolvable, due to misunderstanding of the CO solution (see Global serializability). On the other hand, later, for years CO has been extensively utilized in research articles (which is evident by the simple definition of CO) without mentioning the name "Commitment ordering", and without providing satisfactory correctness proofs (i.e., why global serializability is guaranteed; e.g., see Grid computing, Cloud computing, and Commitment ordering below[8][9][10][11]).
CO provides an effective solution since when each database system in a heterogeneous multidatabase system is CO compliant, the entire system obeys the three conditions for distributed CO given in the previous section. Thus global serializability is guaranteed, as well as automatic global deadlock (a deadlock over two or more transactional objects) resolution.
SS2PL implies CO, and any SS2PL-compliant database can participate in multidatabase systems that utilize the CO solution for global serializability without any modification or addition of a CO algorithm component. As a matter of fact global serializability has been achieved in all-SS2PL multidatabase environments with the Two-phase commit (2PC) protocol since the eighties, and SS2PL in conjunction with 2PC is the de facto standard to reach global serializability across (the common, SS2PL-compliant) databases. Also the following is true: any CO-compliant database system can transparently join any such existing SS2PL based solution for global serializability.
Grid computing, Cloud computing, and Commitment ordering
Commitment ordering (CO; including its variants, e.g., SS2PL), being an attractive solution for Distributed serializability in general and Global serializability in particular, seems to be an ideal solution for guaranteeing serializability in Grid computing and Cloud computing. Serializability is a must for many applications within such environments. CO being a necessary condition for guaranteeing global serializability across autonomous transactional objects is actually the only general solution for distributed serializability in such environments, which typically include many autonomous transactional objects (without CO serializability is very likely to be quickly violated, even if a single autonomous object, uncompliant with CO, participates).
To support CO, the Grid and Cloud infrastructures need to provide Atomic commitment protocol (e.g., 2PC) services only. Each participating transactional object (e.g., a database system) needs to support some variant of CO by itself, in order to enjoy global serializability while inter-operating with other transactional objects (all CO variants transparently inter-operate). Each object can choose any proper CO variant, in order to optimize performance, from implementing CO with Strictness (e.g., SCO and SS2PL), to Optimistic CO, generic (optimistic) ECO, and MVCO (together with any local variant of recoverability). Thus the infrastructure support for CO (i.e., atomic commitment protocol) is minimal and already common. Utilizing CO in an environment with Grid and Cloud characteristics is described in (Raz 1992,[4] page 304).
Re:GRIDiT[10][11] is a proposed approach to support transaction management with data replication in the Grid and the Cloud. Its concurrency control is based on CO. This approach extends the DSGT protocol,[9] which has been proposed for Transactional processes[8][9] earlier and utilizes CO as well. Re:GRIDit utilizes an optimistic version of CO. It uses internal system transactions for replication, which makes replication for high availability transparent to a user. The approach does not suggest to use an external atomic commitment protocol, but rather uses an integrated solution, which must include some form of atomic commitment protocol to achieve atomicity of distributed transactions. No benefit of an integrated atomic commitment protocol seems to exist. Correctness arguments regarding global serializability are unsatisfactory: Correctness arguments, which must use voting deadlock resolution to eliminate unavoidable global cycles in the precedence graph, are not given. Such arguments are detailed by the CO publications which are referenced by neither the Re:GRIDiT nor the DSGT articles (see also explanation about CO below). Also, no concurrency control alternatives for different transactional objects (which exist in the general CO solution) are suggested by Re:GRIDiT. See more details on Re:GRIDiT in The History of Commitment Ordering.
Commitment ordering and how it works in a distributed environment
Main article: Commitment orderingA schedule has the Commitment ordering (CO) property, if the order in time of its transactions' commitment events is compatible with the precedence (partial) order of the respective transactions, as determined by their local conflict graph (precedence graph, serializability graph). Any conflict serializable schedule can be made a CO compliant one, without aborting any transaction in the schedule, by delaying commitment events to comply with the needed partial order.
Enforcing the CO property in each local schedule is an effective way to enforce conflict serializability globally: CO is a broad special case of conflict serializability, and enforcing it locally in each local schedule also enforces it, and hence serializability, globally. The only needed communication between the databases for this purpose is that of the atomic commitment protocol (such as the Two-phase commit protocol (2PC)), which exists in most distributed environments and already must be utilized for the atomicity of each distributed transaction, independently of concurrency control and CO. Thus CO incurs no communication overhead. In each single database, a local CO algorithm can run alongside any local concurrency control mechanism (serializability enforcing mechanism) without interfering with its resource access scheduling strategy, and without adding any access operations to transactions (like acquiring timestamps or tickets) which reduces performance. As such CO provides a general, high performance, fully distributed solution. Neither central processing component nor central data structure are needed. Moreover, CO works also in heterogeneous environments with different database system types and other multiple transactional objects that may employ different serializability mechanisms. The CO solution scales up effectively with network size and the number of databases without any negative impact on performance (assuming the statistics of a single distributed transaction, e.g., the average number of databases involved with such transaction, are unchanged). This makes CO instrumental for global concurrency control.
CO implementation by itself is not sufficient as a concurrency control mechanism, since it lacks the important recoverability property.
The commitment event of a distributed transaction is always generated by some atomic commitment protocol, utilized to reach consensus among its processes on whether to commit or abort it. This procedure is always carried out for distributed transactions, independently of CO. The atomic commitment protocol plays a central role in the distributed CO algorithm. In case of incompatible local commitment orders in two or more databases (no global partial order can embed the respective local partial orders together), which implies a global cycle (a cycle that spans two or more databases) in the global conflict graph, CO generates a voting-deadlock for the atomic commitment protocol (resulting in missing votes), and the protocol resolves that deadlock by aborting a transaction with a missing vote on the cycle and breaking the cycle. Furthermore: with CO, the global augmented conflict graph provides a complete characterization of voting-deadlocks. In this graph also being blocked by a lock to prevent a conflict from being materialized is represented by an edge as a materialized conflict. It is the union of the regular precedence graph with the (reversed edge, for time-order compatibility of conflicting operations) regular wait-for graph, and reflects both materialized and non-materialized conflicts. This graph is a (reversed edge) wait-for graph for voting (an edge from a first transaction to a second transaction indicates that either the voting or local commit of the first is waiting to the second to end), and a global cycle means a voting-deadlock. Thus also global deadlocks due to locking (when at least one edge for lock blocking exists on a global cycle) generate voting-deadlocks and are resolved automatically by the same mechanism (such locking based global deadlocks are resolved automatically also in the common, completely SS2PL based environments, but no research article besides the CO articles is known to notice this fact). No implementation of such global graph is needed, and it is used only to explain the behavior of CO and its effectiveness in both guaranteeing global serializability and resolving locking-based global deadlocks.
See also
- Strong strict two-phase locking (SS2PL or Rigorousness).
- Making snapshot isolation serializable[13] in Snapshot isolation.
- Global serializability, where the Global serializability problem and its proposed solutions are described.
- Commitment ordering,[4] where examples and proof outlines to claims are provided.
- The History of Commitment Ordering, where the evolvement of CO and its utilization are described.
Notes
- ^ a b Philip A. Bernstein, Vassos Hadzilacos, Nathan Goodman (1987): Concurrency Control and Recovery in Database Systems (free PDF download), Addison Wesley Publishing Company, ISBN 0-201-10715-5
- ^ a b Gerhard Weikum, Gottfried Vossen (2001): Transactional Information Systems, Elsevier, ISBN 1-55860-508-8
- ^ Maurice Herlihy and J. Eliot B. Moss. Transactional memory: architectural support for lock-free data structures. Proceedings of the 20th annual international symposium on Computer architecture (ISCA '93). Volume 21, Issue 2, May 1993.
- ^ a b c d e f g Yoav Raz (1992): "The Principle of Commitment Ordering, or Guaranteeing Serializability in a Heterogeneous Environment of Multiple Autonomous Resource Managers Using Atomic Commitment" (PDF), Proceedings of the Eighteenth International Conference on Very Large Data Bases (VLDB), pp. 292-312, Vancouver, Canada, August 1992, ISBN 1-55860-151-1 (also DEC-TR 841, Digital Equipment Corporation, November 1990)
- ^ a b Yoav Raz (2009): Theory of Commitment Ordering - Summary GoogleSites - Site of Yoav Raz. Retrieved 1 Feb, 2011.
- ^ Yoav Raz (1990): On the Significance of Commitment Ordering - Call for patenting, Memorandum, Digital Equipment Corporation, November 1990.
- ^ Yoav Raz (1991-2): US patents for Commitment ordering 5,504,899 5,504,900 5,701,480
- ^ a b c Heiko Schuldt, Hans-Jörg Schek, and Gustavo Alonso (1999): "Transactional Coordination Agents for Composite Systems", In Proceedings of the 3rd International Database Engineering and Applications Symposium (IDEAS’99), IEEE Computer Society Press, Montrteal, Canada, pp. 321–331.
- ^ a b c d Klaus Haller, Heiko Schuldt, Can Türker (2005): "Decentralized coordination of transactional processes in peer-to-peer environments", Proceedings of the 2005 ACM CIKM, International Conference on Information and Knowledge Management, pp. 28-35, Bremen, Germany, October 31 - November 5, 2005, ISBN 1-59593-140-6
- ^ a b c Laura Cristiana Voicu, Heiko Schuldt, Fuat Akal, Yuri Breitbart, Hans Jörg Schek (2009a): "Re:GRIDiT – Coordinating Distributed Update Transactions on Replicated Data in the Grid", 10th IEEE/ACM International Conference on Grid Computing (Grid 2009), Banff, Canada, 2009/10.
- ^ a b c Laura Cristiana Voicu and Heiko Schuldt (2009b): "How Replicated Data Management in the Cloud can benefit from a Data Grid Protocol — the Re:GRIDiT Approach", Proceedings of the 1st International Workshop on Cloud Data Management (CloudDB 2009), Hong Kong, China, 2009/11.
- ^ Gray, J.; Helland, P.; O’Neil, P.; Shasha, D. (1996). "The dangers of replication and a solution". Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data. pp. 173–182. doi:10.1145/233269.233330. ftp://ftp.research.microsoft.com/pub/tr/tr-96-17.pdf.
- ^ a b c Michael J. Cahill, Uwe Röhm, Alan D. Fekete (2008): "Serializable isolation for snapshot databases", Proceedings of the 2008 ACM SIGMOD international conference on Management of data, pp. 729-738, Vancouver, Canada, June 2008, ISBN 978-1-60558-102-6 (SIGMOD 2008 best paper award)
- ^ Alan Fekete (2009), "Snapshot Isolation and Serializable Execution", Presentation, Page 4, 2009, The university of Sydney (Australia). Retrieved 16 September 2009
- ^ a b Yoav Raz (1993): "Commitment Ordering Based Distributed Concurrency Control for Bridging Single and Multi Version Resources." Proceedings of the Third IEEE International Workshop on Research Issues on Data Engineering: Interoperability in Multidatabase Systems (RIDE-IMS), Vienna, Austria, pp. 189-198, April 1993. (also DEC-TR 853 (PDF), Digital Equipment Corporation, July 1992)
- ^ Robert Kallman, Hideaki Kimura, Jonathan Natkins, Andrew Pavlo, Alex Rasin, Stanley Zdonik, Evan Jones, Yang Zhang, Samuel Madden, Michael Stonebraker, John Hugg, Daniel Abadi (2008): "H-Store: A High-Performance, Distributed Main Memory Transaction Processing System", Proceedings of the 2008 VLDB, pages 1496 - 1499, Auckland, New-Zealand, August 2008.
References
- Philip A. Bernstein, Vassos Hadzilacos, Nathan Goodman (1987): Concurrency Control and Recovery in Database Systems, Addison Wesley Publishing Company, ISBN 0-201-10715-5
- Gerhard Weikum, Gottfried Vossen (2001): Transactional Information Systems, Elsevier, ISBN 1-55860-508-8
Categories:- Data management
- Databases
- Concurrency control
- Transaction processing
- Distributed computing problems
Wikimedia Foundation. 2010.