- Oncogenomics
-
Oncogenomics is relatively new sub-field of genomics, which applies high throughput technologies to characterize genes associated with cancer. Oncogenomics is synonymous with "cancer genomics". Cancer is a genetic disease caused by accumulation of mutations to DNA leading to unrestrained cell proliferation and neoplasm formation. The goal of oncogenomics is to identify new oncogenes or tumor suppressor genes that may provide new insights into cancer diagnosis, predicting clinical outcome of cancers, and new targets for cancer therapies. The success of targeted cancer therapies such as Gleevec, Herceptin, and Avastin raised the hope for oncogenomics to elucidate new targets for cancer treatment[1].
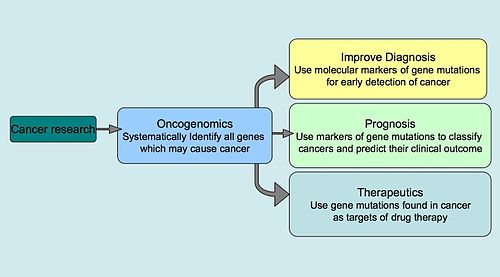 Overall goals of oncogenomics
Overall goals of oncogenomics
Besides understanding the underlying genetic mechanisms that initiates or drives cancer progression, one of the main goals of oncogenomics is to allow for the development of personalized cancer treatment. Cancer develops due to an accumulation of mutations in DNA. These mutations accumulate randomly, and thus, different DNA mutations and mutation combinations exist between different individuals with the same type of cancer. Thus, identifying and targeting specific mutations which have occurred in an individual patient may lead to increased efficacy of cancer therapy.
The completion of the Human Genome Project has greatly facilitated the field of oncogenomics and increased abilities of researchers to find cancer causing genes. In addition, the sequencing technologies now available for sequence generation and data analysis have been applied and greatly contributed to the study of oncogenomics. With the amount of research conducted on cancer genomes and the accumulation of databases documenting the mutational changes, it has been predicted that the most important cancer-causing mutations, rearrangements, and altered expression levels will be catalogued and well characterized within the next decade. Cancer research may look either on the genomic level at DNA mutations, the epigenetic level at methylation or histone modification changes, the transcription level at altered levels of gene expression, or the protein level at altered levels of protein abundance and function in cancer cells. Oncogenomics focuses on the genomic, epigenomic, and transcript level alterations in cancer.
Contents
History
The genomics era became established with much success in the 1990s, with the DNA sequences of many organisms being generated. In the 21st century, the completion of the Human Genome Project at the Wellcome Trust Sanger Institute has paved the way for many new endeavors for studying the functional genomics and examining the genomes which characterize different diseases. Cancer has been one of the main focuses.
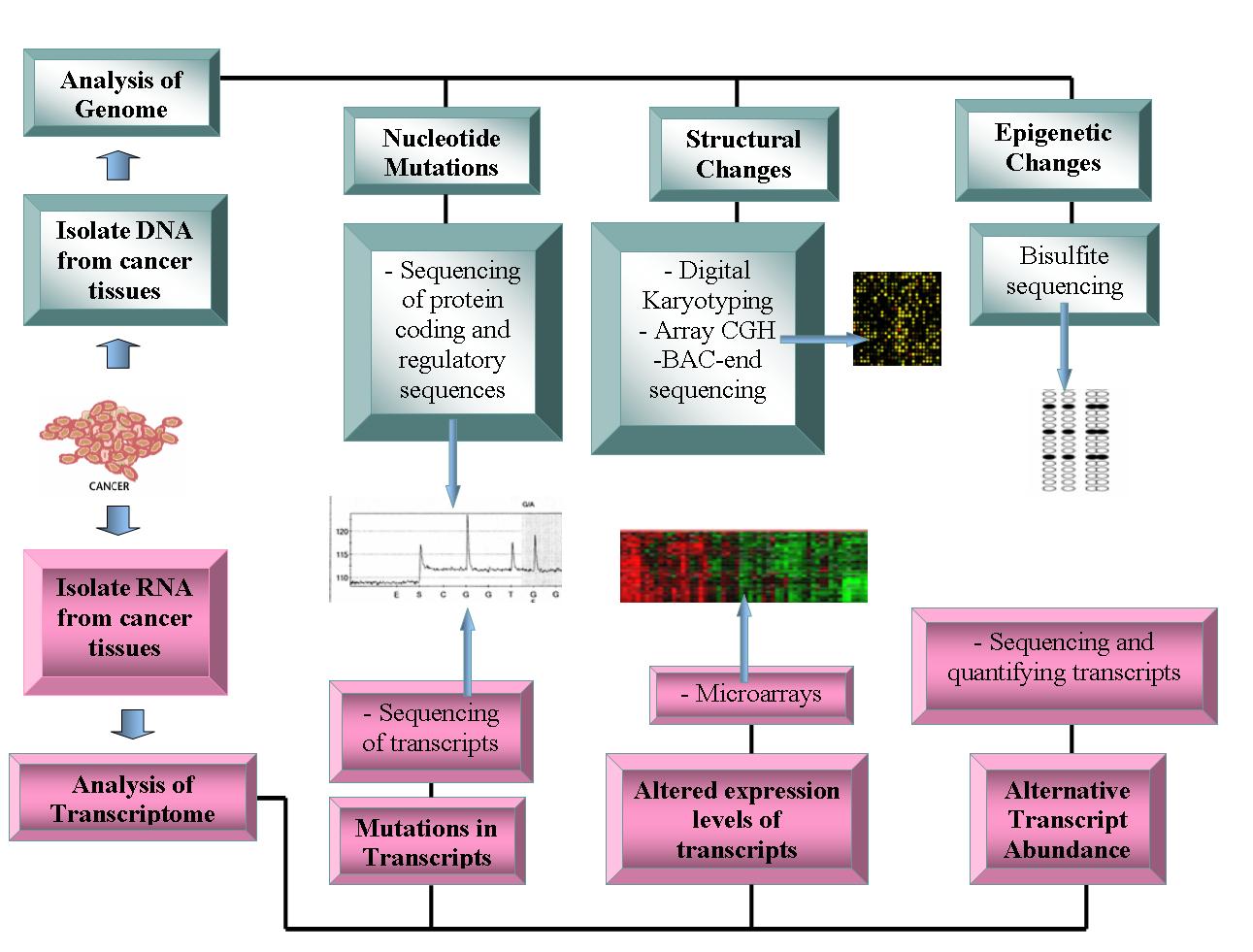
 Current technologies being used in Oncogenomics.
Current technologies being used in Oncogenomics.Technologies
Research examining the genomes and transcriptomes of cancer cells are currently extensively complemented by state of the art technologies.
Cancer Genomes
- High-throughput DNA sequencing technologies: The development of high-throughput DNA sequencing platforms,which utilize pyrosequencing, have greatly altered the field of genomics within only a few years. These systems allow for a relatively low-cost method to generate sequence data, and have been employed by many researchers in the oncogenomics field[1][2][3].
- Array Comparative Genome Hybridization: This technique measures the DNA copy number differences between genomes. This method has been used to study the gain or loss of genes in cancer genomes compared to normal genomes. It uses the fluorescence intensity from two fluorescently labeled sample DNA, which are hybridized to known probes on a microarray chip. The ratio of fluorescence intensities allows quantification of copy number changes in the cancerous genomes [4][5].
- Representational oligotide microarray analysis: This techniques also detects copy number variation using the microarray format, using amplified restriction digested genomic fragments to represent cancerous genomes. These fragments are then hybridized to oligonucleotides of the human genome on an array, with a resolution between 30 and 35 kbit/s [6].
- Digital Karyotyping: Another method that provides a high resolution and high-throughput technology to quantify copy number of genes in samples. This technique involves using genomics tags which have been obtained via restriction enzyme digests on a sample of DNA. These genomic tags are then linked to into ditags, concatenated, cloned, and sequenced. These sequence tags are then mapped back to the reference genome to evaluate tag density and quantify DNA amplification or deletions of regions of genomes[7][8].
- Bacterial Artificial Chromosome (BAC)-end sequencing: This is another method used in oncogenomics, which identifies chromosomal breakpoints in a high-resolution manner. This technique involves generating a BAC library from a cancer genome, and sequencing the ends of these sequences. The BAC clones which contain chromosome aberrations will have end sequences that do not map to a similar region of reference genome, thus identifying a chromosomal breakpoint present in cancerous genomes. By sequencing these BACs, the breakpoints and genes involved may be identified [9].
Cancer Transcriptomes
- Microarrays: These have been and continue to be extremely informative in assessing transcript abundance in cancerous cells. The transcription profiles have provided different means of classification for different types of cancers, predicting prognosis of cancer, and raising the possibility of differential treatment approaches to different types of cancer. The ability to directly sequence transcriptomes of cancerous tissues with high-throughput sequencing technologies also aids in the identification of mutations which have occurred in the coding regions of the proteins[10][11]
As well, the identification of the relative abundance of alternative transcripts has become an important component of the study of cancer. It has been shown that particular alternative transcript forms are correlated with specific types of cancer. With this impact, generation of exon-array technologies which are able to quantify alternate splice forms, and other transcript sequencing technologies, have become an important part of oncogenomics [12].
Bionformatics and functional analysis of oncogenes
With the amounts of sequencing data and expression profiling data being generated, the development of bioinformatics technologies to statistically analyze this data is essential. As well, after the identification of these oncogenes, much research still remains to be done to analyze the functional characteristics of these genes and how they contribute to the cancer phenotype. For example, examination of transformational capabilities of discovered oncogenes are important for confirming their impact in tumour formation. In addition, in cancerous cells, many DNA mutations accumulate. It is important to identify genes which are important in the early stages of cancer progression and in cancer development. Identification of mutations in these genes will be most helpful in diagnosis and in finding new targets for cancer therapy.
Operomics
Operomics is an approach that aims to integrate genomics, transcriptomics, and proteomics in order to achieve a complete understanding of the molecular mechanisms which underlie the development of cancer [13]. This involves simultaneous molecular analysis of DNA, RNA, and protein of tumor tissue samples. With increasing advances in technologies to analyze cancer cells, operomics will be an overall goal of cancer research.
Comparative Oncogenomics
Comparative Oncogenomics is a branch of oncogenomics which uses cross-species comparisons to identify oncogenes. This research involves studying cancer genomes, transcriptomes, and proteomes in other model organisms, such as mice, identifying potential oncogenes, and referring back to human cancer samples to see whether homologues of these oncogenes are also important in causing cancer in humans[14]. Recent research has found that the genetic alterations in mouse models have been found to be exceptionally similar to those found in human cancers. This branch of oncogenomics useful in that different types of cancer may be studied in animal models. These models are generated by various methods, including retroviral insertion mutagenesis or graft transplantation of cancerous cells. Comparative oncogenomics is a powerful approach to oncogene identification.
Synthetic Lethality/Conditional Genetics
One approach to studying oncogenomics, which shows great promise in producing useful cancer therapies by taking advantage of mutational aberrations in cancer cells, is the strategic exploitation of synthetic lethality interactions between multiple genes. Frequently, known oncogenes may be essential for survival of all cells (not only cancer cells). Thus, drugs intended to knock out these oncogenes (and thereby kill cancer cells) may also cause serious negative effects to normal cells: i.e., significant illness may be directly induced by the cancer therapy. To generate therapies that more specifically target cancer cells, scientists are now working to systematically examine the effect of suppressing every gene in the human genome, one at a time, in combination with the presence of the cancer-associated mutation of some other gene which has previously been identified as an oncogene [15][16]. This type of search can thus identify targets for cancer therapy by exploiting the mutations that are present exclusively in cancer cells; if the knockout of an otherwise nonessential gene has little or no effect on healthy cells, but is lethal to cancerous cells containing the mutated form of a given oncogene, then the system-wide suppression of the normally nonessential gene can destroy cancerous cells while leaving healthy ones intact or relatively undamaged. (The term "synthetic lethality," here, describes this sort of synergistic effect.) Success has been observed with this method both in discovering cancer targets and in developing therapies. One example is the case of PARP-1 inhibitors specifically applied to treat BRCA1/BRCA2-associated cancers [17][18]. In this case, the combined presence of PARP-1 inhibition and of the cancer-associated mutations in BRCA genes is lethal only to the cancerous cells. Phase I clinical trials of this technique suggest that it may show promise in patients with BRCA1 or BRCA2 mutations, and Phase II trials are currently underway
Databases for Cancer Research
Many databases are available to cancer researchers as resources which have banked oncogenomic research data. The Cancer Genome Project is an initiative to map out all the somatic intragenic mutations in cancer. To do this, they are systematically sequencing the exons and flanking splice junctions of all the genes in the genomes of primary tumors and cancerous cell lines. COSMIC is a resource which displays the data generated from these experiments. As of February 2008, the CGP has identified 4746 genes and 2985 mutations in 1848 tumours analyzed.
The Cancer Genome Anatomy Project from National Cancer Institute also has banked much information of research on cancer genome, transcriptome, and proteome. Progenetix is another oncogenomic reference database, presenting cytogenetic and molecular-cytogenetic tumor data. Oncomine has compiled data from cancer transcriptome profiles.
The Integrative Oncogenomics database IntOGen integrates multidimensional human oncogenomic data classified by tissue type using the ICD-O terms.[19] Data mining for different alteration types, such as Gene Expression and CNV are made available in the IntOGen database.
The International Cancer Genome Consortium is so far the biggest project to collect human cancer genome data. The data is accessible through the ICGC website.
Specific databases for model animals also exist, as for example the Retrovirus Tagged Cancer Gene Database (RTCGD) has compiled research on retroviral and transposon insertional mutagenesis in mouse tumors.
Advances from Oncogenomics
Mutational analysis of entire gene families has been a powerful approach to oncogenomics which has been informative. Genes of the same family have similar functions, as predicted by similar coding sequences and protein domains, have been systematically sequenced in cancerous genomes to identify particular pathways which may be associated with cancer progression. One such class of families which has been studied is the kinase family genes, involved in adding phosphate groups to proteins, and phosphatase family genes, involved with removing phosphate groups from proteins[20].These families were first examined because of their apparent role in transducing cellular signals of cell growth or death. In particular, more than 50% of colorectal cancers were found to carry a mutation in a kinase or phosphatase gene. Phosphatidylinositold 3-kinases (PIK3CA) gene encode for lipid kinases which were identified to commonly contain mutations in colorectal, breast, gastric, lung, and various other types of cancer [21][22]. Drug therapies have already been developed to inhibit PIK3CA. Another example is the BRAF gene was identified in 2004, which was one of the first genes ever to be implicated in melanomas [23]. BRAF encodes a serine/threonine kinase which is involved in the RAS-RAF-MAPK growth signaling pathway, and they found that mutations in BRAF causing constitutive phosphorylation and activity were found in 59% of melanomas. Before BRAF, there was very little understanding of the genetic mechanism of the development of melanomas, and therefore, prognosis for patients was poor. Thus, the CGP set out to discover genes involved with melanomas and identified BRAF, which is now a target of new cancer therapies, with clinical data of BRAF inhibiting targets already generated[24]
References
- ^ a b Strausberg, R.L., et al., Oncogenomics and the development of new cancer therapies. Nature, 2004. 429(6990): p. 469-474.
- ^ Bardelli, A. and V.E. Velculescu, Mutational analysis of gene families in human cancer. Current Opinion in Genetics & Development, 2005. 15(1): p.5-12.
- ^ Benvenuti, S., S. Arena, and A. Bardelli, Identification of cancer genes by mutational profiling of tumor genomes. Febs Letters, 2005. 579(8): p. 1884-1890.
- ^ Shih, I.M. and T.L. Wang, Apply innovative technologies to explore cancer genome. Current Opinion in Oncology, 2005. 17(1): p. 33-38.
- ^ Greshock, J., et al., 1-Mb resolution array-based comparative genomic hybridization using a BAC clone set optimized for cancer gene analysis. Genome Research, 2004. 14(1): p. 179-187.
- ^ Lucito, R., et al., Representational oligonucleotide microarray analysis: A high-resolution method to detect genome copy number variation. Genome Research, 2003. 13(10): p. 2291-2305.
- ^ Hu, M., J. Yao, and K. Polyak, Methylation-specific digital karyotyping. Nature Protocols, 2006. 1(3): p. 1621-1636.
- ^ Korner, H., et al., Digital karyotyping reveals frequent inactivation of the Dystrophin/DMD gene in malignant melanoma. Cell Cycle, 2007. 6(2): p. 189-198.
- ^ Volik, S., et al., End-sequence profiling: Sequence-based analysis of aberrant genomes. Proceedings of the National Academy of Sciences of the United States of America, 2003. 100(13): p. 7696-7701.
- ^ van de Vijver, M.J., et al., A gene-expression signature as a predictor of survival in breast cancer. New England Journal of Medicine, 2002. 347(25): p. 1999-2009.
- ^ van 't Veer, L.J., et al., Expression profiling predicts outcome in breast cancer. Breast Cancer Research, 2002. 5(1): p. 57-58.
- ^ Xu, Q. and C. Lee, Discovery of novel splice forms and functional analysis of cancer-specific alternative splicing in human expressed sequences. Nucleic Acids Research, 2003. 31(19): p. 5635-5643.
- ^ Hanash, S.M., Operomics: Molecular analysis of tissues from DNA to RNA to protein. Clinical Chemistry and Laboratory Medicine, 2000. 38(9): p. 805-813.
- ^ Peeper, D. and A. Berns, Cross-species onocogenomics in cancer gene idenfification. Cell, 2006. 125(7): p. 1230-1233.
- ^ Kaelin, W.G., The concept of synthetic lethality in the context of anticancer therapy. Nature Reviews Cancer, 2005. 5(9): p. 689-698.
- ^ O'Connor, M.J., N.M.B. Martin, and G.C.M. Smith, Targeted cancer therapies based on the inhibition of DNA strand break repair. Oncogene, 2007. 26(56): p. 7816-7824.
- ^ Farmer H., McCabe N., Lord C.J. et al. Targeting the DNA repair defect in BRCA mutant cells as a therapeutic strategy. Nature, 2005. 434(7035): p.917-921.
- ^ Bryant, H.E., et al., Specific killing of BRCA2-deficient tumours with inhibitors of poly(ADP-ribose) polymerase. Nature, 2005. 434(7035): p. 913-917.
- ^ Gundem, G., et al., IntOGen: integration and data mining of multidimensional oncogenomic data. Nature Methods, 2010. 300(5621): p. 92-93.
- ^ Blume-Jensen, P. and T. Hunter, Oncogenic kinase signalling. Nature, 2001. 411(6835): p. 355-365.26.
- ^ Bardelli, A., et al., Mutational analysis of the tyrosine kinome in colorectal cancers. Science, 2003. 300(5621): p. 949-949.
- ^ Samuels, Y., et al., High frequency of mutations of the PIK3CA gene in human cancers. Science, 2004. 304(5670): p. 554-554.
- ^ Davies, H., et al., Mutations of the BRAF gene in human cancer. Nature, 2002. 417(6892): p. 949-954.
- ^ Danson, S. and P. Lorigan, Improving outcomes in advanced malignant melanoma - Update on systemic therapy. Drugs, 2005. 65(6): p. 733-743.
External links
- Cancer Genome Project: an oncogenomic reference database from the Wellcome Trust Sanger Institute
- Cancer Genome Anatomy Project: an oncogenomic reference database from the National Cancer Institute
- Progenetix: an oncogenomic reference database, presenting cytogenetic and molecular-cytogenetic tumor data
- Oncomine
- Retrovirus Tagged Cancer Gene Database (RTCGD)
- IntOGen Integration and data mining of multidimensional oncogenomic data
Categories:- Applied genetics
- Biotechnology
- Medical genetics
Wikimedia Foundation. 2010.