- OmegaT
-
OmegaT 
OmegaT 1.6 under Mac OS XOriginal author(s) Keith Godfrey Developer(s) Didier Briel, Alex Buloichik, Zoltan Bartko, Tiago Saboga, etc... Initial release November 28, 2002 Stable release 2.5.0 update 1 / October 25, 2011 Operating system Cross-platform Type Computer-assisted translation License GPL Website omegat.org OmegaT is a computer-assisted translation tool written in the Java programming language. It is free software originally developed by Keith Godfrey in 2000, and is currently developed by a team led by Didier Briel. The name OmegaT is a registered trademark in Germany.
OmegaT is intended for professional translators. Its features include customisable segmentation using regular expressions, translation memory with fuzzy matching and match propagation, glossary matching, dictionary matching, translation memory and reference material searching, and inline spell-checking using Hunspell spelling dictionaries.
OmegaT runs on Linux, Mac OS X and Microsoft Windows 98 SE or higher,[1] and requires Java 1.5. It is available in 27 languages. According to a survey in 2010[2] among 458 professional translators, OmegaT is used 1/3 as much as Wordfast, DejaVu and MemoQ, and 1/8 as much as the market leader Trados.
Contents
History
OmegaT was first developed by Keith Godfrey in 2000. It was originally written in C++.
The first public release in February 2001[3] was written in Java. This version used a proprietary translation memory format. It could translate unformatted text files, and HTML, and perform only block-level segmentation (i.e. paragraphs instead of sentences).
Development and software releases
The development of OmegaT is hosted on SourceForge. The development team is led by Didier Briel. As with many opensource projects, new versions of OmegaT are released frequently, usually with 2-3 bugfixes and feature updates each. There is a "standard" version, which always has a complete user manual and a "latest" version which includes features that are not yet documented in the user manual.[4] The updated sources are always available from the Sourceforge code repository.[5]
How OmegaT works
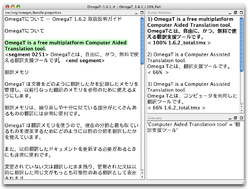
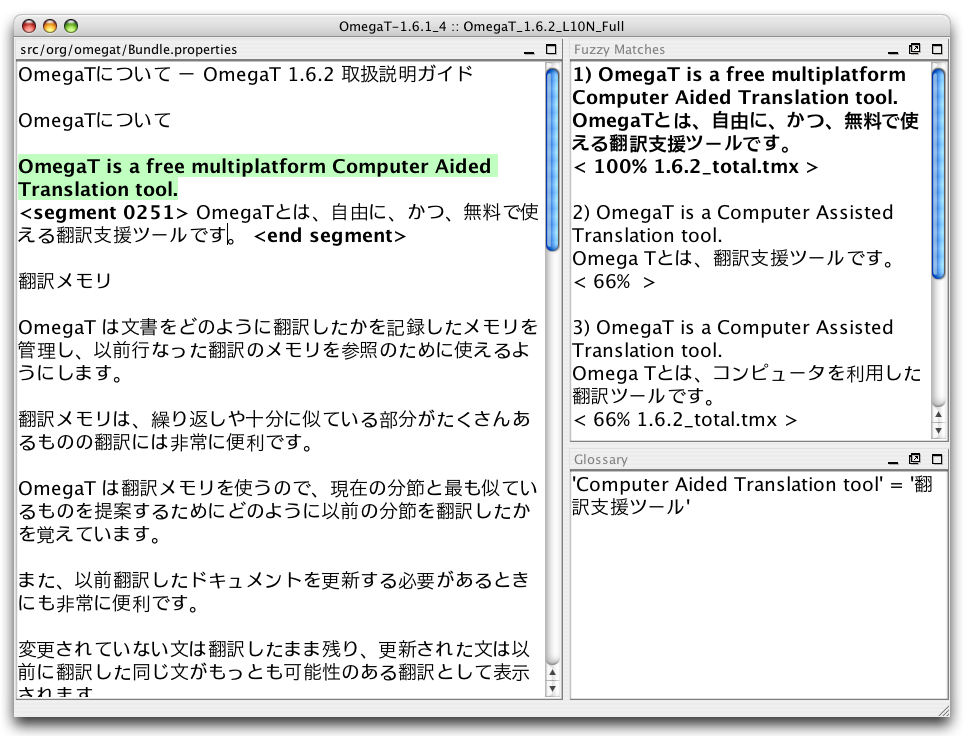
For every translation job, OmegaT creates a set of project folders which contain or can contain specific files. The user copies his non-translated documents into a /source/ subfolder, and at the end of the translation process, the translated documents appear in the /target/ subfolder. OmegaT displays the translatable content of the source documents in a segmented format in an editing pane for the user to translate.
Before commencing translation, the user can also copy old translations into the /tm/ subfolder, glossaries into the /glossary/ folder, and StarDict dictionaries into the /dictionary/ folder, which will all be consulted by OmegaT automatically.
During the translation, OmegaT automatically checks previous translations for similar sentences, which are displayed in the Fuzzy Matches pane. The translator can insert fuzzy matches into the edit pane using a keyboard shortcut. OmegaT also consults glossaries and dictionaries if the user had added them to the project folders beforehand. If machine translation such as Google Translate is enabled, it will appear in a separate Machine Translation pane.
When the translation is finished, OmegaT creates translated versions of the files, and exports the project's current translations to TMX files that can be reused in later translations or optionally exchanged with other translators using OmegaT or other CAT tools.
Features of OmegaT
OmegaT shares many features with mainstream CAT tools. These include creating, importing and exporting translation memories, fuzzy matching from translation memories, glossary look-up, and reference and concordance searching.
OmegaT also has additional features that are not always available in other CAT tools. These include:
- OmegaT can translate multiple files in multiple file formats simultaneously, and consult multiple translation memories,[6] glossaries and dictionaries (limited only by available computer memory).
- With regard to supported file types, OmegaT allows the user to customise file extensions and file encodings. For a number of document types, the user can choose selectively which elements must be translated (e.g. in OpenOffice.org Writer files, choose whether to include bookmarks; in Microsoft Office 2007/2010 files, choose whether to translate footnotes; or in HTML, choose whether to translate ALT text for images). The user can also choose how non-standard elements in third-party translation memories should be handled.
- OmegaT's segmentation rules are based on regular expressions. Segmentation can be configured based on language or based on file format, and successive segmentation rules inherit values from each other.
- In the edit window, the user can jump directly to the next untranslated segment, or go forward or backwards in history. Users can use undo and redo, copy and paste, and switch between uppercase and lowercase in the same way as one would in an advanced text editor. The user can choose to see the source text of segments that have already been translated. The edit pane also has inline spell-checking using Hunspell dictionaries, and interactive spell-checking is done using the mouse.
- Users can insert fuzzy matches using a keyboard shortcut or using the mouse. OmegaT shows the degree of similarity in fuzzy matches using colours. OmegaT can also display the date, time and the name of the user who translated any given segment. Glossary matches can be inserted using the mouse. The user can choose to have the source text copied into the target text field, or to have the highest fuzzy match automatically inserted.
- In the search window, the user can choose to search the current files' source text, target text, other translation memories, and reference files. Searches can be case sensitive, and regular expressions can also be used. Double-clicking a search result takes the user directly to that segment in the edit window.
- After translation, OmegaT can perform tag validation to ensure that there are no accidental tag errors. OmegaT can calculate statistics for the project files and translation memories before the project starts, or during the translation to show the progress of the translation job.
- OmegaT can get machine translations from Apertium, Belazar and Google Translate, and display it in a separate window.
- The various windows in OmegaT's user interface can be moved around, maximised, tiled, tabbed and minimised. When OmegaT starts, a short tutorial called "Instant Start" is displayed.
Document formats support
Several file types can be translated directly in OmegaT. OmegaT determines the file type by the file extension. The file extension handling and preferred encoding can be customised to override default settings.
OmegaT handles formatted documents by converting formatting to tags, similar to other commercial CAT tools.
Directly supported formats
OmegaT can translate the following formats directly:
File format File extension pattern Documentation formats plain text (any text format which Java can handle) encoded in a variety of encodings including Unicode .txt, .txt1, .txt2, .utf8 HTML/XHTML .html, .htm, .xhtml, .xht OpenDocument (ODF),[7] used in LibreOffice, StarOffice, OpenOffice.org .sx?, .st?, .od?, .ot? Microsoft Office Open XML .doc?, .xls?, .ppt? Help & Manual .xml, .hmxp HTML Help Compiler .hhc, .hhk LaTeX .tex, .latex DokuWiki .txt QuarkXPress CopyFlow Gold .tag, .xtg DocBook .xml, .dbk Localization resource formats Android Resource .xml Java properties .properties Typo3 LocManager .xml Mozilla DTD .dtd Windows Resource .rc WiX Localization .wxl ResX .resx files with a “Key=Value” structure .ini, .lng Multilingual localization formats XLIFF .xlf, .sdlxliff Portable Object (PO) .po, .pot Other formats SubRip Subtitles .srt SVG Images .svg Indirectly supported formats
There are two processes that allow OmegaT to handle unsupported formats:
- register the format file extension into the preferred file filter (typically all plain text based formats)
- convert the format to a directly supported format
Support for XLIFF
The program Rainbow from the Okapi Framework can convert certain file formats to an XLIFF format that OmegaT does support. Rainbow can also create complete OmegaT project folders from such documents, for easier handling in OmegaT.[8]
Support for Gettext PO
A number of file formats can be converted to Gettext Portable Object (PO) files, which can be translated in OmegaT. The Debian Linux program po4a can convert formats such as LaTeX, TeX and POD to Gettext PO.[9] The Translate Toolkit can convert Mozilla .properties and dtd files, CSV files, certain Qt .ts files, and certain XLIFF files to Gettext PO.
Support for Office Open XML and ODF
Microsoft Word, Excel and PowerPoint documents from version 97 to 2003 can be converted to Office Open XML (Microsoft Office 2007/2010) or ODF (OpenOffice.org) format. Conversion is not entirely lossless and may lead to loss of formatting.
Support for Trado® .ttx files
Trados® .ttx files can be treated using the Okapi TTX Filter.
Supported memory and glossary formats
Translation memories in TMX format
OmegaT's internal translation memory format is not visible to the user, but every time it autosaves the translation project, all new or updated translation units are automatically exported and added to three external TMX memories: a native OmegaT TMX, a level 1 TMX and a level 2 TMX.
- The native TMX file is for use in OmegaT projects.
- The level 1 TMX file preserves textual information and can be used with TMX level 1 and 2 supporting CAT tools.
- The level 2 file preserves textual information as well as inline tag information and can be used with TMX level 2 supporting CAT tools.
Exported level 2 files include OmegaT's internal tags encapsulated in TMX tags which allows such TMX files to generate matches in TMX level 2 supporting CAT tools. Tests have been positive in Trados and SDLX.
OmegaT can import TMX files up to version 1.4b level 1 as well as level 2. Level 2 files imported in OmegaT will generate matches of the same level since OmegaT converts the TMX level 2 tags of the foreign TMX. Here again, tests have been positive with TMX files created by Transit.
Glossaries
For glossaries, OmegaT mainly uses tab-delimited plain text files in UTF-8 encoding with the .txt extension. The structure of a glossary file is extremely simple: the first column contains the source language word, the second column contains the corresponding target language words, the third column (optional) can contain anything including comments on context etc. Such glossaries can easily be created in a text editor.
Similarly structured files in standard CSV format are also supported, as well as TBX files.
Involvement by community of users
The OmegaT Project
The OmegaT Project is a sort of “computer literacy” group that focus on translators' needs. Users are encouraged to contribute tools written by themselves in response to translators' needs which are not yet addressed by the main OmegaT program itself.[10]
Localization of OmegaT
OmegaT's user interface and documentation have been translated into about 30 languages. Volunteer translators can translate either the user interface, the "Instant Start" short tutorial, or the entire user manual (or all three components). All the language files and all translations of the user manual are included in the standard distribution of OmegaT.
User-created programs
A characteristic of the OmegaT user community is that deficiencies in OmegaT often prompt users to create macros, scripts and programs that perform those functions, although sometimes those features later become available in OmegaT itself. When OmegaT offered only paragraph segmentation, a user created OpenOffice.org macros for segmenting by sentence. When automatic leveraging of TMs in OmegaT still required TMs to be merged, a user created a TMX merging script. When OmegaT offered no spell-checking support, several users created scripts or found solutions to provide spell-checking as part of an OmegaT based translation process.[11]
Current tools that offer features that are not yet built in to OmegaT include a conversion utility for Trados TagEditor files, two simple aligners, an on-the-fly glossary adder, and a tool that treats tags as placeables.[12]
Other software built upon OmegaT
Autshumato translation suite
Autshumato consists a CAT tool, an aligner, a PDF extractor, a TMX editor, and a public TM based on crawled data. The finished version will include a terminology manager and a machine translator. The CAT tool element is built upon OmegaT, and requires OpenOffice.org to run. Development is funded by the South African government's Department of Arts and Culture.[13]
Benten
Benten is an Eclipse based XLIFF editor. It uses OmegaT code to handle the TM matching process. It is partly funded by the Japanese government.[14]
Boltran
Boltran is a standalone web-based CAT tool that mimicks the workflow of an OmegaT project. It is built upon the source code of OmegaT, and consequently is capable of translating anything OmegaT can translate, and has near identical glossary management and fuzzy matching capabilities as OmegaT. At present, the only public Boltran server is that of the developer's web site itself, but in theory anyone can set up a public or private Boltran server.[15]
OmegaT+
OmegaT+ is a CAT tool that was forked from OmegaT version 1.4.5 in 2005. OmegaT+ works in a way similar to OmegaT. It has developed its own features but projects are not compatible with OmegaT.[16]
See also
- Translation memory
- Computer-assisted Translation
- Office Open XML software
- OpenDocument software
References
- ^ http://www.java.com/en/download/help/5000011000.xml
- ^ http://www.translationtribulations.com/2010/07/results-of-june-translation-tools.html
- ^ http://accurapid.com/journal/23linux.htm
- ^ [1] OmegaT's "standard" and "latest" versions
- ^ [2] The latest source files are always available from the Sourceforge code repository
- ^ http://www.articlesbase.com/corporate-articles/free-open-source-translation-memory-software-omegat-vs-anaphraseus-tm-1472085.html
- ^ Open Document Format for Office Applications – ISO/IEC 26300:2006 format
- ^ Okapi Framework – Text Extraction utility can create an OmegaT project folder tree
- ^ po4a – A conversion utility to and from the Portable Object format, perl application packaged under Debian
- ^ OmegaT Getting Involved – Translators are encouraged to write their own supplementary tools
- ^ http://tech.groups.yahoo.com/group/OmegaT/files/
- ^ http://www.omegat.org/en/resources.html
- ^ Autshumato
- ^ Benten
- ^ Boltran
- ^ OmegaT+
External links
User group
- omegat@yahoogroups.com – Multilingual user mailing list (archives searchable without subscription)
Categories:- Translation software
- Free software programmed in Java
- Software-localization tools
Wikimedia Foundation. 2010.