- Sequencing
-
- For the sense of "sequencing" used in electronic music, see the music sequencer article. For sequence learning in cognitive science, see sequence learning.
In genetics and biochemistry, sequencing means to determine the primary structure (sometimes falsely called primary sequence) of an unbranched biopolymer. Sequencing results in a symbolic linear depiction known as a sequence which succinctly summarizes much of the atomic-level structure of the sequenced molecule.
Contents
DNA sequencing
Main article: DNA sequencingDNA sequencing is the process of determining the nucleotide order of a given DNA fragment. Thus far, most DNA sequencing has been performed using the chain termination method developed by Frederick Sanger. This technique uses sequence-specific termination of a DNA synthesis reaction using modified nucleotide substrates. However, new sequencing technologies such as Pyrosequencing are gaining an increasing share of the sequencing market. More genome data is now being produced by pyrosequencing than Sanger DNA sequencing. Pyrosequencing has enabled rapid genome sequencing. Bacterial genomes can be sequenced in a single run with several X coverage with this technique. This technique was also used to sequence the genome of James Watson recently.
The sequence of DNA encodes the necessary information for living things to survive and reproduce. Determining the sequence is therefore useful in fundamental research into why and how organisms live, as well as in applied subjects. Because of the key nature of DNA to living things, knowledge of DNA sequence may come in useful in practically any biological research. For example, in medicine it can be used to identify, diagnose and potentially develop treatments for genetic diseases. Similarly, research into pathogens may lead to treatments for contagious diseases. Biotechnology is a burgeoning discipline, with the potential for many useful products and services.
Sanger sequencing
 Part of a radioactively labelled sequencing gel
Part of a radioactively labelled sequencing gel
In chain terminator sequencing (Sanger sequencing), extension is initiated at a specific site on the template DNA by using a short oligonucleotide 'primer' complementary to the template at that region. The oligonucleotide primer is extended using a DNA polymerase, an enzyme that replicates DNA. Included with the primer and DNA polymerase are the four deoxynucleotide bases (DNA building blocks), along with a low concentration of a chain terminating nucleotide (most commonly a di-deoxynucleotide). Limited incorporation of the chain terminating nucleotide by the DNA polymerase results in a series of related DNA fragments that are terminated only at positions where that particular nucleotide is used. The fragments are then size-separated by electrophoresis in a slab polyacrylamide gel, or more commonly now, in a narrow glass tube (capillary) filled with a viscous polymer.
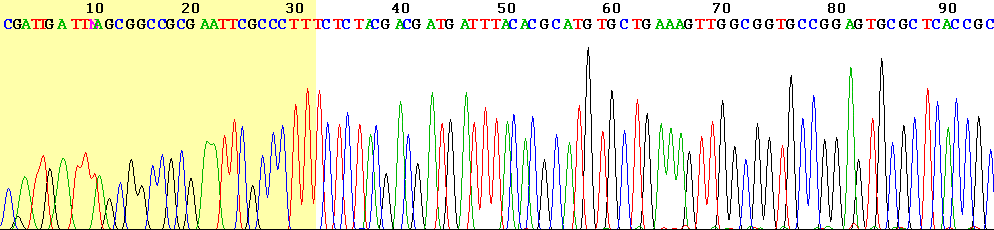
 View of the start of an example dye-terminator read (click to expand)
View of the start of an example dye-terminator read (click to expand)An alternative to the labelling of the primer is to label the terminators instead, commonly called 'dye terminator sequencing'. The major advantage of this approach is the complete sequencing set can be performed in a single reaction, rather than the four needed with the labeled-primer approach. This is accomplished by labelling each of the dideoxynucleotide chain-terminators with a separate fluorescent dye, which fluoresces at a different wavelength. This method is easier and quicker than the dye primer approach, but may produce more uneven data peaks (different heights), due to a template dependent difference in the incorporation of the large dye chain-terminators. This problem has been significantly reduced with the introduction of new enzymes and dyes that minimize incorporation variability.
This method is now used for the vast majority of sequencing reactions as it is both simpler and cheaper. The major reason for this is that the primers do not have to be separately labelled (which can be a significant expense for a single-use custom primer), although this is less of a concern with frequently used 'universal' primers. [This is changing rapidly due to the increasing cost-effectiveness of 2nd and 3rd generation systems from Illumina, 454, ABI, Helicos & Dover.]
Pyrosequencing
Pyrosequencing, which was developed by Pål Nyhren and Mostafa Ronaghi, has been commercialized by Biotage (for low throughput sequencing) and 454 Life Sciences (for high-throughput sequencing). The latter platform sequences roughly 100 megabases [now up to 400 megabases] in a 7-hour run with a single machine. In the array-based method (commercialized by 454 Life Sciences), single-stranded DNA is annealed to beads and amplified via EmPCR. These DNA-bound beads are then placed into wells on a fiber-optic chip along with enzymes which produce light in the presence of ATP. When free nucleotides are washed over this chip, light is produced as ATP is generated when nucleotides join with their complementary base pairs. Addition of one (or more) nucleotide(s) results in a reaction that generates a light signal that is recorded by the CCD camera in the instrument. The signal strength is proportional to the number of nucleotides, for example, homopolymer stretches, incorporated in a single nucleotide flow. [1]
RNA sequencing
RNA is less stable in the cell, and also more prone to nuclease attack experimentally. As RNA is generated by transcription from DNA, the information is already present in the cell's DNA. However, it is sometimes desirable to sequence RNA molecules. In particular, in Eukaryotes RNA molecules are not necessarily co-linear with their DNA template, as introns are excised. To sequence RNA, the usual method is first to reverse transcribe the sample to generate DNA fragments. This can then be sequenced as described above.
For more information on the capabilities of next-generation sequencing applied to whole transcriptomes see: RNA-Seq.
Protein sequencing
Main article: protein sequencingMethods for performing protein sequencing include:
- Edman degradation
- Peptide mass fingerprinting
- Mass spectrometry
- Protease digests
If the gene encoding the protein can be identified it is currently much easier to sequence the DNA and infer the protein sequence. Determining part of a protein's amino-acid sequence (often one end) by one of the above methods may be sufficient to enable the identification of a clone carrying the gene.
Polysaccharide sequencing
Though polysaccharides are also biopolymers, it is not so common to talk of 'sequencing' a polysaccharide, for several reasons. Although many polysaccharides are linear, many have branches. Many different units (individual monosaccharides) can be used, and bonded in different ways. However, the main theoretical reason is that whereas the other polymers listed here are primarily generated in a 'template-dependent' manner by one processive enzyme, each individual join in a polysaccharide may be formed by a different enzyme. In many cases the assembly is not uniquely specified; depending on which enzyme acts, one of several different units may be incorporated. This can lead to a family of similar molecules being formed. This is particularly true for plant polysaccharides. Methods for the structure determination of oligosaccharides and polysaccharides include NMR spectroscopy and methylation analysis.[1]
See also
- Genetic code
- Full Genome Sequencing
- Pathogenomics
- RNA-Seq
- Sequence motif
References
Categories:- Biochemistry methods
- Molecular biology
Wikimedia Foundation. 2010.