- Radix tree
-
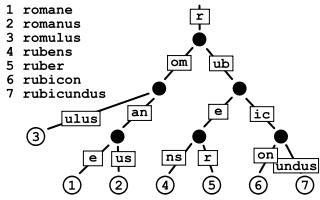
In computer science, a radix tree (also patricia trie or radix trie) is a space-optimized trie data structure where each node with only one child is merged with its child. The result is that every internal node has at least two children. Unlike in regular tries, edges can be labeled with sequences of characters as well as single characters. This makes them much more efficient for small sets (especially if the strings are long) and for sets of strings that share long prefixes.
It supports the following main operations, all of which are O(k), where k is the maximum length of all strings in the set:
- Lookup: Determines if a string is in the set. This operation is identical to tries except that some edges consume multiple characters.
- Insert: Add a string to the tree. We search the tree until we can make no further progress. At this point we either add a new outgoing edge labeled with all remaining characters in the input string, or if there is already an outgoing edge sharing a prefix with the remaining input string, we split it into two edges (the first labeled with the common prefix) and proceed. This splitting step ensures that no node has more children than there are possible string characters.
- Delete: Delete a string from the tree. First, we delete the corresponding leaf. Then, if its parent only has one child remaining, we delete the parent and merge the two incident edges.
- Find predecessor: Locates the largest string less than a given string, by lexicographic order.
- Find successor: Locates the smallest string greater than a given string, by lexicographic order.
A common extension of radix trees uses two colors of nodes, 'black' and 'white'. To check if a given string is stored in the tree, the search starts from the top and follows the edges of the input string until no further progress can be made. If the search-string is consumed and the final node is a black node, the search has failed; if it is white, the search has succeeded. This enables us to add a large range of strings with a common prefix to the tree, using white nodes, then remove a small set of "exceptions" in a space-efficient manner by inserting them using black nodes.
Contents
Applications
As mentioned, radix trees are useful for constructing associative arrays with keys that can be expressed as strings. They find particular application in the area of IP routing, where the ability to contain large ranges of values with a few exceptions is particularly suited to the hierarchical organization of IP addresses.[1] They are also used for inverted indexes of text documents in information retrieval.
History
Donald R. Morrison first described what he called "Patricia trees" in 1968;[2] the name comes from the acronym PATRICIA, which stands for "Practical Algorithm To Retrieve Information Coded In Alphanumeric". Gernot Gwehenberger independently invented and described the data structure at about the same time.[3]
Comparison to other data structures
(In the following comparisons, it is assumed that the keys are of length k and the data structure contains n elements.)
Unlike balanced trees, radix trees permit lookup, insertion, and deletion in O(k) time rather than O(log n). This doesn't seem like an advantage, since normally k ≥ log n, but in a balanced tree every comparison is a string comparison requiring O(k) worst-case time, many of which are slow in practice due to long common prefixes. In a trie, all comparisons require constant time, but it takes m comparisons to look up a string of length m. Radix trees can perform these operations with fewer comparisons and require many fewer nodes.
Radix trees also share the disadvantages of tries, however: as they can only be applied to strings of elements or elements with an efficiently reversible mapping (injection) to strings, they lack the full generality of balanced search trees, which apply to any data type with a total ordering. A reversible mapping to strings can be used to produce the required total ordering for balanced search trees, but not the other way around. This can also be problematic if a data type only provides a comparison operation, but not a (de)serialization operation.
Hash tables are commonly said to have expected O(1) insertion and deletion times, but this is only true when considering computation of the hash of the key to be a constant time operation. When hashing the key is taken into account, hash tables have expected O(k) insertion and deletion times, but may take longer in the worst-case depending on how collisions are handled. Radix trees have worst-case O(k) insertion and deletion. The successor/predecessor operations of radix trees are also not implemented by hash tables.
Variants
The HAT-trie is a radix tree based cache-conscious data structure that offers efficient string storage and retrieval, and ordered iterations. Performance, with respect to both time and space, is comparable to the cache-conscious hashtable.[4][5]
See also
- Prefix tree (also known as a Trie)
- Directed acyclic word graph (aka DAWG)
- Ternary search tries
- Acyclic deterministic finite automata
- Hash trie
- Deterministic finite automata
- Judy array
- Search algorithm
- Extendible hashing
- Hash array mapped trie
- Prefix Hash Tree
- Burstsort
- Luleå algorithm
- Huffman coding
References
- ^ Knizhnik, Konstantin. "Patricia Tries: A Better Index For Prefix Searches", Dr. Dobb's Journal, June, 2008.
- ^ Morrison, Donald R. Practical Algorithm to Retrieve Information Coded in Alphanumeric
- ^ G. Gwehenberger, Anwendung einer binären Verweiskettenmethode beim Aufbau von Listen. Elektronische Rechenanlagen 10 (1968), pp. 223–226
- ^ Askitis, Nikolas; Sinha, Ranjan (2007). HAT-trie: A Cache-conscious Trie-based Data Structure for Strings. 62. 97–105. ISBN 1-920-68243-0. http://portal.acm.org/citation.cfm?id=1273749.1273761&coll=GUIDE&dl=
- ^ Askitis, Nikolas; Sinha, Ranjan (2010). Engineering scalable, cache and space efficient tries for strings. doi:10.1007/s00778-010-0183-9. ISBN 1066-8888 (Print) 0949-877X (Online). http://www.springerlink.com/content/86574173183j6565/.
External links
- Algorithms and Data Structures Research & Reference Material: PATRICIA, by Lloyd Allison, Monash University
- Patricia Tree, NIST Dictionary of Algorithms and Data Structures
- Crit-bit trees, by Daniel J. Bernstein
- Radix Tree API in the Linux Kernel, by Jonathan Corbet
- Kart (key alteration radix tree), by Paul Jarc
Implementations
- GNU C++ Standard library has a trie implementation
- Java implementation of Radix Tree, by Tahseen Ur Rehman
- C# implementation of a Radix Tree
- Practical Algorithm Template Library, a C++ library on PATRICIA tries (VC++ >=2003, GCC G++ 3.x), by Roman S. Klyujkov
- Patricia Trie C++ template class implementation, by Radu Gruian
- Haskell standard library implementation "based on big-endian patricia trees". Web-browsable source code.
- Patricia Trie implementation in Java, by Roger Kapsi and Sam Berlin
- Crit-bit trees forked from C code by Daniel J. Bernstein
- Patricia Trie implementation in C, in libcprops
- Patricia Trees : efficient sets and maps over integers in OCaml, by Jean-Christophe Filliâtre
Trees in computer science Binary trees Self-balancing binary search trees B-trees Tries Binary space partitioning (BSP) trees Non-binary trees Exponential tree · Fusion tree · Interval tree · PQ tree · Range tree · SPQR tree · Van Emde Boas treeSpatial data partitioning trees Other trees Heap · Hash tree · Finger tree · Metric tree · Cover tree · BK-tree · Doubly-chained tree · iDistance · Link-cut tree · Fenwick treeCategories:- Trees (structure)
- String data structures

Wikimedia Foundation. 2010.