- Concept-oriented model
-
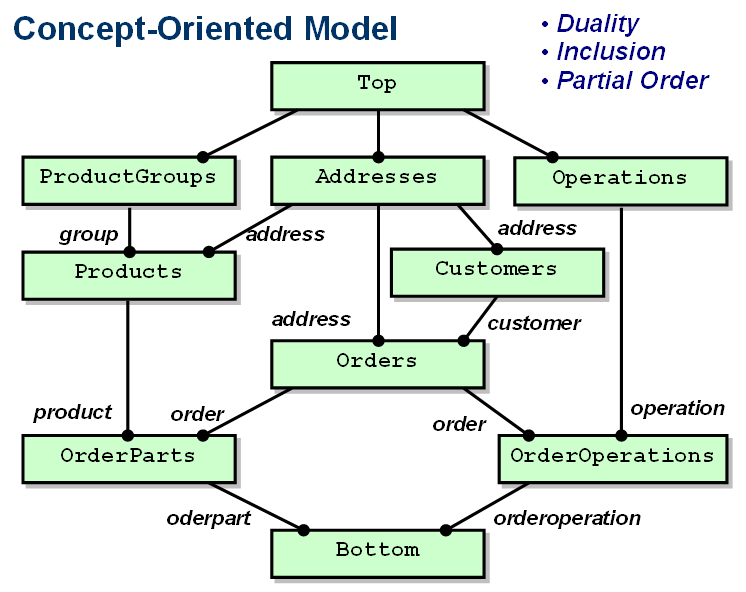
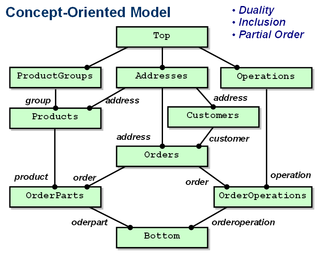 Example of a concept-oriented model.
Example of a concept-oriented model.
The concept-oriented model (COM) is a data model based on the following three principles:
- Duality principle postulates that any element consists of two parts, called identity and entity. Accordingly, data modelling is divided into two orthogonal branches: identity modelling and entity modelling.
- Inclusion principle postulates that elements exist within a hierarchy where each of them has a super-element specified via inclusion relation. All elements are identified via hierarchical domain-specific addresses.
- Order principle postulates that elements exist within a partially ordered set where each of them has a number of greater and lesser elements. It is assumed that a reference stored in this element represents a greater element.
A data element in the concept-oriented model is defined as a couple consisting of one identity and one entity both having domain-specific structure. This model uses two orthogonal relations for data organization and manipulation: inclusion and partial order. Thus any element participates in two structures simultaneously: it is a member of a hierarchy (tree) and it is a member of a partially ordered set. The main purpose of the hierarchical structure consists in modelling hierarchical address spaces where each element has a unique domain-specific identity. The main purpose of the partial order consists in describing data semantics.
The name of this model originates from the main data modelling construct, concept, which generalizes conventional classes. This new approach to data modelling has been developed by Alexandr Savinov[1] since 2004 along with a novel approach to programming, called concept-oriented programming.
Contents
Overview
Concepts
In COM, types of elements are described by a novel data modelling construct, called concept. Concept is defined as a couple of two classes: identity class and entity class. Concept fields are referred to as dimensions to emphasize their role in describing multi-dimensional structure. For example, a customer could be described by the following concept:
CONCEPT Customer IDENTITY CHAR(10) SSN ENTITY CHAR(64) name DATE dobA concept instance consists of one identity and one entity. Identity is a domain-specific address or reference representing the entity. It is important that identities are not analogous to primary keys. Rather, they can be thought of as domain-specific surrogates.
Concepts generalize conventional classes and are used where classes are normally used to declare the type of elements. In particular, concepts are used to declare the type of elements of collections. For example, we could create a table for storing customers using the following SQL-like query:
CREATE TABLE Customers CONCEPT Customer
This table will contain only entity part of customers while identity part defines its address space. In terms of tables, entity class describes the horizontal structure (columns) and identity class describes the vertical structure (row addresses).
Concept Inclusion
Each concept has a super-concept which is declared via inclusion relation which generalizes inheritance. Concept instances are identified relative to their parent instance so that elements have unique hierarchical addresses which are analogous to the conventional postal addresses. For example, if streets are identified relative to cities then we use inclusion to describe this hierarchical relationship:
CONCEPT City IDENTITY CHAR(10) name ENTITY DOUBLE population CONCEPT Street IN City IDENTITY CHAR(10) name ENTITY DOUBLE lengthParent and child elements are stored in different tables and one parent may have many children. After such declaration streets will be represented by two segments: the first segment is the city and the second segment is the street itself.
Concept Ordering
Each concept has a number of greater concepts specified via its dimension (field) types and this structure must be a partially ordered set. For example, assume that bank account concept has a dimension referencing its owner:
CONCEPT Customer // It is a greater concept IDENTITY CHAR(10) SSN ENTITY CHAR(64) name DATE dob CONCEPT Account // It is a lesser concept IDENTITY CHAR(10) accNo ENTITY Customer owner // Dimension type is a greater concept DOUBLE balanceHere the fact that an account stores a reference to a customer entails the fact that accounts are less than customers in the partially ordered set (in a diagram Account is positioned under Customer).
Projection and De-Projection
Operation of projection, denoted by right arrow, is applied to a set of elements and returns a set of their greater elements along the specified dimension. For example, given a set of accounts we can find their owners:
AllOwners = Accounts -> owner -> Customers
Operation of de-projection, denoted by left arrow, is applied to a set of elements and returns a set of their lesser elements along the specified dimension. For example, given a set of customers we can find their accounts:
AllAccounts = Customers <- owner <- Accounts
A sequence of projections and de-projections is referred to as an access path. Intermediate collections can involve constraints which can contain internal projections/de-projections with aggregation operations. For example, the following query returns accounts with small balance belonging to young customers who also have an account with big balance:
ResultSet = (Accounts WHERE balance > 1000) -> owner -> (Customers WHERE age < 25) <- owner <- (Accounts WHERE balance < 100)First, we select accounts with large balance (line 1). Then these accounts are projected to young customers by selecting their owners (line 2). Finally, these young rich customers (who may have also other accounts) are de-projected down to accounts with small balance (line 3).
Example
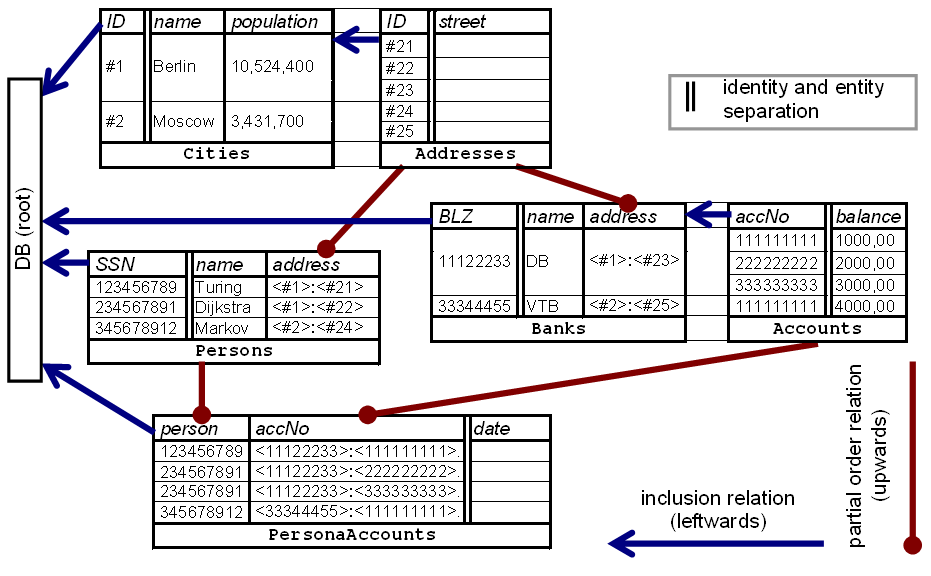
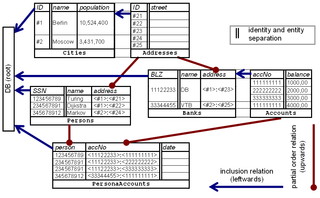 Concept-oriented model.
Concept-oriented model.The database schema shown in the diagram consists of 6 tables. Each table has two parts: identity and entity. (Note that identity part is not a primary key - it can be thought of as a domain-specific surrogate.) For example, banks are identified by their BLZ which acts as a domain-specific reference to the bank entity.
Each table is an element of the inclusion hierarchy, that is, each table has one super-table which is always positioned on the left. This relation is shown by dark blue leftward arrows. Tables which do not have an explicitly specified super-table are supposed to be included in the root which is the database. The basic idea behind inclusion is that any row of this table is always identified relative to some row of the super-table. For example, table Addresses is included in table Cities which means that any address is within some city and hence a fully qualified identifier of an address consists of two segments: a city id and the address itself. In the same way table Accounts is included in table Banks and hence any bank account is identifined by (i) the bank where it has been created, and (ii) account number. Such complex references are then stored as values in other tables by uniquely identifying the rows. For example, complex reference <11122233>:<111111111> represents account number 111111111 created in bank 11122233. If accounts could have internal savings accounts then a new sub-table SavingsAccounts had to be included in table Accounts. In this case one savings account would be identified by a complex reference consisting of three segments: bank, account, savings account number.
Each table in the database schema is an element of the partially ordered set where it has lesser and greater tables. Partial order relation among tables is shown by dark red upward arrows, that is, each upward arrow leads from the lesser table to a greater table. Here the main principle is that column types determine greater tables. For example, table Persons has a column which stores the person address and hence table Addresses is a greater table for Persons. Note that table Addresses is also greater than table Banks because banks also have an address. Tables Persons and Accounts have one common lesser table PersonsAccounts. It is used to implement a many-to-many relationship between them by storing account ownership information. It is also the most specific table in the model which is also called bottom table.
See also
- Database
- Entity-relationship model
- Formal concept analysis
- Inverse dimension
- Object database
- OLAP
- Ontology (information science)
- Relational model
References
- ^ Alexandr A. Savinov List of publications from the DBLP Bibliography Server. Retrieved 9 Oktober 2008.
Further reading
- Alexandr Savinov (2009). "Concept-Oriented Model". Handbook of Research on Innovations in Database Technologies and Applications: Current and Future Trends, Editors: Viviana E. Ferraggine, Jorge H. Doorn, Laura C. Rivero, IGI Global, 2009.
- Alexandr Savinov (2008). "Concepts and Concept-Oriented Programming". Journal of Object Technology, vol. 7, no. 3, March-April 2008, pp. 91-106. PDF
- Alexandr Savinov (2006). "Query by Constraint Propagation in the Concept-Oriented Data Model". Computer Science Journal of Moldova, Vol. 14, No. 2, 219-238, 2006. PDF
- Alexandr Savinov (2006). "Grouping and Aggregation in the Concept-Oriented Data Model". ACM Symposium on Applied Computing (SAC 2006), April 23-27, 2006, Dijon, France, 482-486.
- Alexandr Savinov (2005). "Hierarchical Multidimensional Modelling in the Concept-Oriented Data Model". In: Proceedings of the CLA 2005 International Workshop on Concept Lattices and their Applications Olomouc, Czech Republic, September 7-9, 2005. Edited by Radim Belohlavek and Vaclav Snasel. PDF
External links
- Informal introduction into the Concept-Oriented Data Model Alexandr Savinov at conceptoriented.org, 24.10.2005. (PDF)
- Informal Introduction into the Concept-Oriented Programming Alexandr Savinov at conceptoriented.org, 19.11.2007 (PDF)
Database models Models - Flat
- Hierarchical
- Dimensional model
- Network
- Relational
- Graph
- Object-oriented
- Entity-attribute-value model
Other models - Associative
- Concept-oriented
- Multidimensional
- Semantic
- Star schema
- XML database
Implementations Categories:
Wikimedia Foundation. 2010.