- String searching algorithm
-
String searching algorithms, sometimes called string matching algorithms, are an important class of string algorithms that try to find a place where one or several strings (also called patterns) are found within a larger string or text.
Let Σ be an alphabet (finite set). Formally, both the pattern and searched text are vectors of elements of Σ. The Σ may be a usual human alphabet (for example, the letters A through Z in the Latin alphabet). Other applications may use binary alphabet (Σ = {0,1}) or DNA alphabet (Σ = {A,C,G,T}) in bioinformatics.
In practice, how the string is encoded can affect the feasible string search algorithms. In particular if a variable width encoding is in use then it is slow (time proportional to N) to find the Nth character. This will significantly slow down many of the more advanced search algorithms. A possible solution is to search for the sequence of code units instead, but doing so may produce false matches unless the encoding is specifically designed to avoid it.
Contents
Basic classification
The various algorithms can be classified by the number of patterns each uses.
Single pattern algorithms
Let m be the length of the pattern and let n be the length of the searchable text.
Algorithm Preprocessing time Matching time1 Naïve string search algorithm 0 (no preprocessing) Θ((n-m+1) m) Rabin–Karp string search algorithm Θ(m) average Θ(n+m),
worst Θ((n-m+1) m)Finite-state automaton based search Θ(m |Σ|) Θ(n) Knuth–Morris–Pratt algorithm Θ(m) Θ(n) Boyer–Moore string search algorithm Θ(m + |Σ|) Ω(n/m), O(n) Bitap algorithm (shift-or, shift-and, Baeza–Yates–Gonnet) Θ(m + |Σ|) O(mn) 1Asymptotic times are expressed using O, Ω, and Θ notation
The Boyer–Moore string search algorithm has been the standard benchmark for the practical string search literature.[1]
Algorithms using finite set of patterns
- Aho–Corasick string matching algorithm
- Commentz–Walter algorithm
- Rabin–Karp string search algorithm
Algorithms using infinite number of patterns
Naturally, the patterns can not be enumerated in this case. They are represented usually by a regular grammar or regular expression.
Other classification
Other classification approaches are possible. One of the most common uses preprocessing as main criteria.
Classes of string searching algorithms Text not preprocessed Text preprocessed Patterns not preprocessed Elementary algorithms Index methods Patterns preprocessed Constructed search engines Signature methods Naïve string search
The simplest and least efficient way to see where one string occurs inside another is to check each place it could be, one by one, to see if it's there. So first we see if there's a copy of the needle in the first character of the haystack; if not, we look to see if there's a copy of the needle starting at the second character of the haystack; if not, we look starting at the third character, and so forth. In the normal case, we only have to look at one or two characters for each wrong position to see that it is a wrong position, so in the average case, this takes O(n + m) steps, where n is the length of the haystack and m is the length of the needle; but in the worst case, searching for a string like "aaaab" in a string like "aaaaaaaaab", it takes O(nm) steps.
Finite state automaton based search
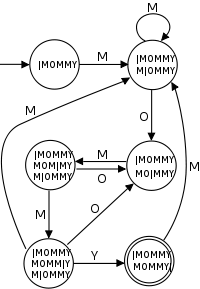
In this approach, we avoid backtracking by constructing a deterministic finite automaton (DFA) that recognizes strings containing the desired search string. These are expensive to construct—they are usually created using the powerset construction—but very quick to use. For example, the DFA shown to the right recognizes the word "MOMMY". This approach is frequently generalized in practice to search for arbitrary regular expressions.
Stubs
Knuth–Morris–Pratt computes a DFA that recognizes inputs with the string to search for as a suffix, Boyer–Moore starts searching from the end of the needle, so it can usually jump ahead a whole needle-length at each step. Baeza–Yates keeps track of whether the previous j characters were a prefix of the search string, and is therefore adaptable to fuzzy string searching. The bitap algorithm is an application of Baeza-Yates' approach.
Index methods
Faster search algorithms are based on preprocessing of the text. After building a substring index, for example a suffix tree or suffix array, the occurrences of a pattern can be found quickly. As an example, a suffix tree can be built in Θ(n) time, and all z occurrences of a pattern can be found in O(m + z) time (if the alphabet size is viewed as a constant).
Other variants
Some search methods, for instance trigram search, are intended to find a "closeness" score between the search string and the text rather than a "match/non-match". These are sometimes called "fuzzy" searches.
References
- ^ Hume and Sunday (1991) [Fast String Searching] SOFTWARE—PRACTICE AND EXPERIENCE, VOL. 21(11), 1221–1248 (NOVEMBER 1991 )
- R. S. Boyer and J. S. Moore, A fast string searching algorithm, Carom. ACM 20, (10), 262–272(1977).
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Chapter 32: String Matching, pp.906–932.
External links
- Huge (maintained) list of pattern matching links
- StringSearch – high-performance pattern matching algorithms in Java – Implementations of many String-Matching-Algorithms in Java (BNDM, Boyer-Moore-Horspool, Boyer-Moore-Horspool-Raita, Shift-Or)
- Exact String Matching Algorithms — Animation in Java, Detailed description and C implementation of many algorithms.
- Boyer-Moore-Raita-Thomas
Categories:- Algorithms on strings
- Search algorithms

Wikimedia Foundation. 2010.