- Neighbor joining
-
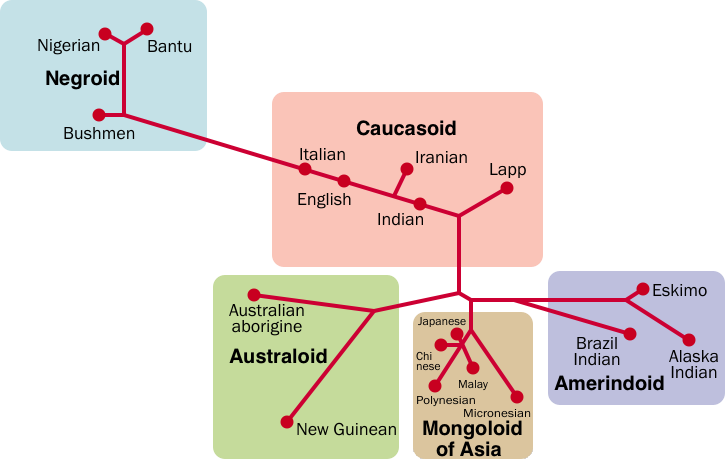
 This genetic distance map made in 2002 is an estimate of 18 world human groups by a neighbour-joining method based on 23 kinds of genetic information. It was made by Saitou Naruya (斎藤成也) professor at the (Japanese) National Institute for Genetics,[1]
This genetic distance map made in 2002 is an estimate of 18 world human groups by a neighbour-joining method based on 23 kinds of genetic information. It was made by Saitou Naruya (斎藤成也) professor at the (Japanese) National Institute for Genetics,[1]
In bioinformatics, neighbor joining is a bottom-up clustering method for the creation of phenetic trees (phenograms), created by Naruya Saitou and Masatoshi Nei.[2] Usually used for trees based on DNA or protein sequence data, the algorithm requires knowledge of the distance between each pair of taxa (e.g., species or sequences) to form the tree.[3]
Contents
The algorithm
Neighbor joining starts with a completely unresolved tree, whose topology corresponds to that of a star network, and iterates over the following steps until the tree is completely resolved and all branch lengths are known:
- Based on the current distance matrix calculate the matrix Q (defined below).
- Find the pair of taxa in Q with the lowest value. Create a node on the tree that joins these two taxa (i.e., join the closest neighbors, as the algorithm name implies).
- Calculate the distance of each of the taxa in the pair to this new node.
- Calculate the distance of all taxa outside of this pair to the new node.
- Start the algorithm again, considering the pair of joined neighbors as a single taxon and using the distances calculated in the previous step.
The Q-matrix
Based on a distance matrix relating the r taxa, calculate Q as follows:
where d(i,j) is the distance between taxa i and j.
Distance of the pair members to the new node
For each neighbor in the pair just joined, use the following formula to calculate the distance to the new node. (Taxa f and g are the paired taxa and u is the newly generated node.):
and, by reflection:
Distance of the other taxa to the new node
For each taxon not considered in the previous step, we calculate the distance to the new node as follows:
where u is the new node, k is the node for which we want to calculate the distance and f and g are the members of the pair just joined.
Complexity
Since neighbor joining on a set of r taxa takes requires r − 3 iterations, and since at each step one has to build and search
 matrices, the algorithm can be implemented so as to obtain a time complexity of O(r3).
matrices, the algorithm can be implemented so as to obtain a time complexity of O(r3).Example
Let us assume that we have four taxa (A, B, C, D) and the following distance matrix:
A B C D A 0 7 11 14 B 7 0 6 9 C 11 6 0 7 D 14 9 7 0 We obtain the following values for the Q matrix:
A B C D A 0 −40 −34 −34 B −40 0 −34 −34 C −34 −34 0 −40 D −34 −34 −40 0 In the example above, two pairs of taxa have the lowest value, namely −40. We can select either of them for the second step of the algorithm. We follow the example assuming that we joined taxa A and B together. If u denotes the new node, then the branch lengths of edges {A,u} and {B,u} are respectively 6 and 1, by the above formula.
We then proceed to updating the distance matrix, by computing d(u,k) according to the above formula for every node k. In this case, we obtain d(u,C) = 5 and d(u,D) = 8. The resulting distance matrix is:
AB C D AB 0 5 8 C 5 0 7 D 8 7 0 We can start the procedure anew taking this matrix as the original distance matrix. In our example, it suffices to do one more step of the recursion to obtain the complete tree.
Advantages and disadvantages
Neighbor joining is based on the minimum-evolution criterion, i.e. the topology that gives the least total branch length is preferred at each step of the algorithm. However, neighbor joining may not find the true tree topology with least total branch length because it is a greedy algorithm that constructs the tree in a step-wise fashion. Even though it is sub-optimal in this sense, it has been extensively tested and usually finds a tree that is quite close to the optimal tree. Nevertheless, it has been largely superseded by phylogenetic methods that do not rely on distance measures and offer superior accuracy under most conditions.
The main virtue of neighbor joining relative to these other methods is its computational efficiency. That is, neighbor joining is a polynomial-time algorithm. It can be used on very large data sets for which other means of analysis (e.g. minimum evolution, maximum parsimony, maximum likelihood) are computationally prohibitive. Unlike the UPGMA algorithm for tree reconstruction, neighbor joining does not assume that all lineages evolve at the same rate (molecular clock hypothesis) and produces an unrooted tree. Rooted trees can be created by using an outgroup and the root can then effectively be placed on the point in the tree where the edge from the outgroup connects.
Furthermore, neighbor joining is statistically consistent under many models of evolution. Hence, given data of sufficient length, neighbor joining will reconstruct the true tree with high probability.
Atteson[4] proved that if each entry in the distance matrix differs from the true distance by less than half of the shortest branch length in the tree, then neighbor joining will construct the correct tree.
RapidNJ and NINJA are fast implementations of the neighbor joining algorithm.
Although neighbor joining relies on a matrix whose entries are natural, some branch lengths in the resulting topology may be real numbers[5].
See also
- UPGMA
- Human genetic clustering
References
- ^ Saitou. Kyushu Museum. 2002. February 2, 2007
- ^ Saitou N, Nei M. "The neighbor-joining method: a new method for reconstructing phylogenetic trees." Molecular Biology and Evolution, volume 4, issue 4, pp. 406-425, July 1987.
- ^ Xavier Didelot (2010). "Sequence-Based Analysis of Bacterial Population Structures". In D. Ashley Robinson, Daniel Falush, Edward J. Feil. Bacterial Population Genetics in Infectious Disease. John Wiley and Sons. p. 46–47. ISBN 9780470424742. http://books.google.com/books?id=gPVjfsWnGCcC&pg=PA46.
- ^ Atteson K (1997). "The performance of neighbor-joining algorithms of phylogeny reconstruction", pp. 101–110. In Jiang, T., and Lee, D., eds., Lecture Notes in Computer Science, 1276, Springer-Verlag, Berlin. COCOON '97.
- ^ Felsenstein, Joseph (2004). Inferring Phylogenies. Sinauer Associates, Inc.. pp. 168.
- Notes
- Gascuel O, Steel M (2006). "Neighbor-joining revealed". Mol Biol Evol 23 (11): 1997–2000. doi:10.1093/molbev/msl072. PMID 16877499.
- Mihaescu R, Levy D, Pachter L (2006). "Why neighbor-joining works".
- Studier JA, Keppler KJ (1988). "A note on the Neighbor-Joining algorithm of Saitou and Nei". Mol Biol Evol 5 (6): 729–731. PMID 3221794. http://mbe.oxfordjournals.org/cgi/reprint/5/6/729.pdf.
- Martin Simonsen, Thomas Mailund, Christian N. S. Pedersen (2008). "Rapid Neighbour Joining". Proceedings of WABI 5251: 113–122. doi:10.1007/978-3-540-87361-7_10. http://birc.au.dk/fileadmin/uploaded/rapidNJ.pdf.
External links
- The Neighbor-Joining Method — a tutorial
Topics in phylogenetics Relevant fields Basic concepts Inference methods Maximum parsimony · Maximum likelihood · Neighbor-joining · UPGMA · Bayesian inference · Least squares · Three-taxon analysisCurrent topics -morphy -phyly List of evolutionary biology topicsCategories:- Bioinformatics algorithms
- Phylogenetics
- Computational phylogenetics
- Data clustering algorithms

![d(f,u)=\frac{1}{2}d(f,g)+\frac{1}{2(r-2)} \left [ \sum_{k=1}^r d(f,k) - \sum_{k=1}^r d(g,k) \right ] \quad](8/a781c3d7e537fb3856ddc1f36d74bd3b.png)

![d(u,k)=\frac{1}{2} [d(f,k)+d(g,k)-d(f,g)]](0/f602a7a6d76764fa6bb3f021466d1997.png)
Wikimedia Foundation. 2010.