- Minimum Information Required in the Annotation of Models
-

MIRIAM (Minimum Information Required in the Annotation of Models[1]), is an effort to standardize the annotation and curation process of quantitative models of biological systems [2]. The project produced a set of guidelines suitable for use with any structured format for computational models, as well as the software and services infrastructure, in order to allow different groups to collaborate on annotating and curating computational models in biology.
The idea of "a set of good practice rules" with "some metadata obligatory" was first proposed by Nicolas Le Novère in October 2004 as part of a reflection to develop a common database of models in Systems Biology (that led to the creation of BioModels Database). It was further discussed at a meeting in Heidelberg during ICSB 2004 with representatives of many groups involved in effort to exchange computational models.
MIRIAM is a registered project of the MIBBI (Minimum Information for Biological and Biomedical Investigations)[3].
Contents
Standard
MIRIAM Standard is composed of three parts: reference correspondence, attribution annotation, and external resource annotation.
Reference correspondence
The first part specifies that a model must be encoded in a public standardized machine-readable format, clearly related to a single reference description, and must reflect the biological processes listed in the reference description. All quantitative attributes have to be defined, including initial conditions, and the model must be able to reproduce reasonably well the results given in the reference description.
- The model must be encoded in a public, standardized, machine-readable format (SBML, CellML, GENESIS, ...).
- The model must comply with the standard in which it is encoded.
- The model must be clearly related to a single reference description. If a model is composed from different parts, there should still be a description of the derived/combined model.
- The encoded model structure must reflect the biological processes listed in the reference description.
- The model must be instantiated in a simulation: all quantitative attributes have to be defined, including initial conditions.
- When instantiated, the model must be able to reproduce all results given in the reference description within an epsilon (algorithms, round-up errors).
Attribution annotation
The second part of the standard deals with the annotation of the model. A model has to provide the citation of the reference description, lists its creators, and be attached to some terms of distribution.
- The model has to be named.
- A citation of the reference description must be joined (complete citation, unique identifier, unambiguous URL). The citation should permit to identify the authors of the model.
- The name and contact of model creators must be joined.
- The date and time of creation and last modification should be specified. An history is useful but not required.
- The model should be linked to a precise statement about the terms of distribution. MIRIAM does not require "freedom of use" or "no cost".
External resource annotation
Finally, each component of a model must be annotated to allow its unambiguous identification. This annotation is based on a set of standard Unique Resource Identifiers that describe a specific piece of knowledge.
- The annotation must permit to unambiguously relate a piece of knowledge to a model constituent.
- The referenced information should be described using a triplet
{data type, identifier, qualifier}:- The data type should be written as a Unique Resource Identifier (URI).
- The identifier is analysed within the framework of the data type.
- Data type and identifier can be combined in a single URI:
urn:miriam:obo.go:GO%3A0006915,urn:miriam:uniprot:P62158, ... - Qualifiers (optional) should refine the link between the model components and the piece of knowledge: "has a", "is version of", "is homolog to", etc.
In order to resolve this annotation, the community has to agree on a set of valid URIs and possesses ways of automating their treatment. MIRIAM Resources have been developed for this purpose: allowing the storage of the URIs of the data types and the resolution between them and the physical locations of the pieces of knowledge.
Uniform Resource Identifiers
An important part of the standard consists in the controlled annotation of model components, based on Uniform Resource Identifiers. For more information on the use of those URIs to annotate models, see the specification of SBML Level 2 Version 2 (and above). In order to enable interoperability of this annotation, the community has to agree on a set of recognised data resources. MIRIAM Database (using MySQL) is an online resource created to catalogue the data resources, their URIs and the corresponding physical URLs, whether these are controlled vocabularies or databases.
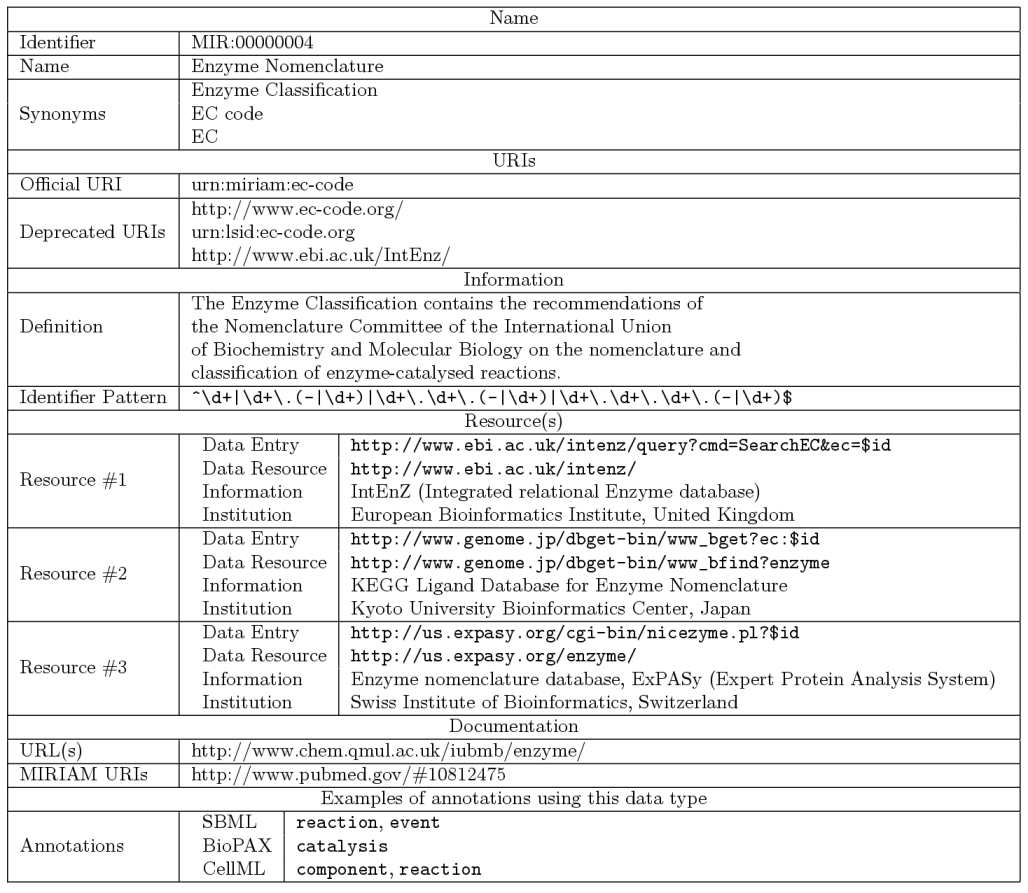
 Example of an entry stored in MIRIAM Resources
Example of an entry stored in MIRIAM Resources
Each entry contains a diverse set of details about the resource: official name and synonyms, root URIs (URL and URN forms), patterns of identifiers, documentation, etc. Each data resource can be associated with several physical locations. For instance:
- name: Gene Ontology
- synonym: GO
- pattern: GO:\d{7}$
- URI:
urn:miriam:obo.go - Locations
- location home: http://www.ebi.ac.uk/ego/
- root URL: http://www.ebi.ac.uk/ego/DisplayGoTerm?selected=$1
- location home: http://www.godatabase.org/cgi-bin/amigo/go.cgi
- root URL: http://www.godatabase.org/cgi-bin/amigo/go.cgi?query=$1
- [...]
Note that MIRIAM URIs take a URN form. For instance the URI representing the enzyme classification is:
urn:miriam:ec-code.Resources
A set of resources have been developed[4]. They are freely available online from the European Bioinformatics Institute Website[5], as well as the whole source code of the project on SourceForge.net[6].
The Website uses an Apache Tomcat server to provide an interface for the database. Users are able to perform queries such as retrieving valid physical locations (URLs) corresponding to a given URI (whether a generic data type or a precise piece of knowledge), retrieving all the information stored about a data type (such as its name, its synonyms, links to some documentation, etc.) and immediately get the results in a dynamic way, using AJAX.
Moreover, a programmatic access through Web Services (based on Apache Axis and SOAP messages) is available[7]. This API permits not only to resolved model annotations, but also to generate the correct URIs based on resource name and accession numbers. For an easier use of these services, a Java library is also available.
MIRIAM Resources is used by several worldwide projects, like BioModels Database[8][9], SABIO-RK[10], Virtual Cell[11], COPASI[12], SBMLeditor[13], ...
Of course, everybody can contribute to the resources by adding new data types, via the online form provided.
MIRIAM Resources are developed in the Computational Neurobiology Group at the European Bioinformatics Institute.
See also
References
- ^ Although the initial article used the verb "requested", the community now switched to "required", to be in line with other MI. MIRIAM is registered in MIBBI with "required"
- ^ Le Novère N, Finney A, Hucka M, Bhalla US, Campagne F, Collado-Vides J, Crampin E, Halstead M, Klipp E, Mendes P, Nielsen P, Sauro H, Shapiro B, Snoep JL, Spence HD, Wanner BL. (2005). "Minimum information requested in the annotation of biochemical models (MIRIAM).". Nat Biotechnol 23 (12): 1509–15. doi:10.1038/nbt1156. PMID 16333295. http://www.ncbi.nlm.nih.gov/entrez/eutils/elink.fcgi?dbfrom=pubmed&tool=clinical.uthscsa.edu/cite&email=badgett@uthscdsa.edu&retmode=ref&cmd=prlinks&id=16333295.
- ^ http://www.mibbi.org/ Minimum Information for Biological and Biomedical Investigations
- ^ Laibe C, Le Novère N (2007). "MIRIAM Resources: tools to generate and resolve robust cross-references in Systems Biology.". BMC Syst Biol 1: 58. doi:10.1186/1752-0509-1-58. PMC 2259379. PMID 18078503. http://www.ncbi.nlm.nih.gov/entrez/eutils/elink.fcgi?dbfrom=pubmed&tool=clinical.uthscsa.edu/cite&email=badgett@uthscdsa.edu&retmode=ref&cmd=prlinks&id=18078503.
- ^ http://www.ebi.ac.uk/miriam/ MIRIAM Resources Website
- ^ http://sourceforge.net/projects/miriam/ MIRIAM project on SourceForge.net
- ^ Li C, Courtot M, Le Novère N, Laibe C (2009). "BioModels.net Web Services, a free and integrated toolkit for computational modelling software.". Brief Bioinform 11 (3): 270–277. doi:10.1093/bib/bbp056. PMC 2913671. PMID 19939940. http://www.ncbi.nlm.nih.gov/entrez/eutils/elink.fcgi?dbfrom=pubmed&tool=clinical.uthscsa.edu/cite&email=badgett@uthscdsa.edu&retmode=ref&cmd=prlinks&id=19939940.
- ^ Le Novère N, Bornstein B, Broicher A, Courtot M, Donizelli M, Dharuri H et al. (2006). "BioModels Database: a free, centralized database of curated, published, quantitative kinetic models of biochemical and cellular systems". Nucleic Acids Res 34 (Database issue): D689–91. doi:10.1093/nar/gkj092. PMC 1347454. PMID 16381960. http://www.ncbi.nlm.nih.gov/entrez/eutils/elink.fcgi?dbfrom=pubmed&tool=clinical.uthscsa.edu/cite&email=badgett@uthscdsa.edu&retmode=ref&cmd=prlinks&id=16381960.
- ^ http://www.ebi.ac.uk/biomodels/ BioModels Database Website
- ^ http://sabio.villa-bosch.de/ SABIO-Reaction Kinetics Database
- ^ http://www.nrcam.uchc.edu/login/login.html Virtual Cell modelling environment
- ^ http://www.copasi.org/ Complex Pathway Simulator
- ^ http://www.ebi.ac.uk/compneur-srv/SBMLeditor.html SBMLeditor
Wikimedia Foundation. 2010.