- Fault-tolerant system
-
- This article contains specific implementations of fault tolerant systems. For general theory, see fault-tolerant design.
Fault-tolerance or graceful degradation is the property that enables a system (often computer-based) to continue operating properly in the event of the failure of (or one or more faults within) some of its components. A newer approach is progressive enhancement. If its operating quality decreases at all, the decrease is proportional to the severity of the failure, as compared to a naïvely-designed system in which even a small failure can cause total breakdown. Fault-tolerance is particularly sought-after in high-availability or life-critical systems.
Fault-tolerance is not just a property of individual machines; it may also characterise the rules by which they interact. For example, the Transmission Control Protocol (TCP) is designed to allow reliable two-way communication in a packet-switched network, even in the presence of communications links which are imperfect or overloaded. It does this by requiring the endpoints of the communication to expect packet loss, duplication, reordering and corruption, so that these conditions do not damage data integrity, and only reduce throughput by a proportional amount.
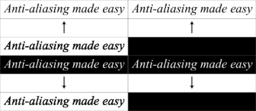 An example of graceful degradation by design in an image with transparency. The top two images are each the result of viewing the composite image in a viewer that recognises transparency. The bottom two images are the result in a viewer with no support for transparency. Because the transparency mask (centre bottom) is discarded, only the overlay (centre top) remains; the image on the left has been designed to degrade gracefully, hence is still meaningful without its transparency information.
An example of graceful degradation by design in an image with transparency. The top two images are each the result of viewing the composite image in a viewer that recognises transparency. The bottom two images are the result in a viewer with no support for transparency. Because the transparency mask (centre bottom) is discarded, only the overlay (centre top) remains; the image on the left has been designed to degrade gracefully, hence is still meaningful without its transparency information.
Data formats may also be designed to degrade gracefully. HTML for example, is designed to be forward compatible, allowing new HTML entities to be ignored by Web browsers which do not understand them without causing the document to be unusable.
Recovery from errors in fault-tolerant systems can be characterised as either roll-forward or roll-back. When the system detects that it has made an error, roll-forward recovery takes the system state at that time and corrects it, to be able to move forward. Roll-back recovery reverts the system state back to some earlier, correct version, for example using checkpointing, and moves forward from there. Roll-back recovery requires that the operations between the checkpoint and the detected erroneous state can be made idempotent. Some systems make use of both roll-forward and roll-back recovery for different errors or different parts of one error.
Within the scope of an individual system, fault-tolerance can be achieved by anticipating exceptional conditions and building the system to cope with them, and, in general, aiming for self-stabilization so that the system converges towards an error-free state. However, if the consequences of a system failure are catastrophic, or the cost of making it sufficiently reliable is very high, a better solution may be to use some form of duplication. In any case, if the consequence of a system failure is so catastrophic, the system must be able to use reversion to fall back to a safe mode. This is similar to roll-back recovery but can be a human action if humans are present in the loop.
Contents
Fault tolerance requirements
The basic characteristics of fault tolerance require:
- No single point of failure
- Fault isolation to the failing component
- Fault containment to prevent propagation of the failure
- Availability of reversion modes
In addition, fault tolerant systems are characterized in terms of both planned service outages and unplanned service outages. These are usually measured at the application level and not just at a hardware level. The figure of merit is called availability and is expressed as a percentage. For example, a five nines system would statistically provide 99.999% availability.
Fault-tolerant systems are typically based on the concept of redundancy.
Fault-tolerance by replication
Spare components addresses the first fundamental characteristic of fault-tolerance in three ways:
- Replication: Providing multiple identical instances of the same system or subsystem, directing tasks or requests to all of them in parallel, and choosing the correct result on the basis of a quorum;
- Redundancy: Providing multiple identical instances of the same system and switching to one of the remaining instances in case of a failure (failover);
- Diversity: Providing multiple different implementations of the same specification, and using them like replicated systems to cope with errors in a specific implementation.
All implementations of RAID, redundant array of independent disks, except RAID 0 are examples of a fault-tolerant storage device that uses data redundancy.
A lockstep fault-tolerant machine uses replicated elements operating in parallel. At any time, all the replications of each element should be in the same state. The same inputs are provided to each replication, and the same outputs are expected. The outputs of the replications are compared using a voting circuit. A machine with two replications of each element is termed Dual Modular Redundant (DMR). The voting circuit can then only detect a mismatch and recovery relies on other methods. A machine with three replications of each element is termed Triple Modular Redundancy (TMR). The voting circuit can determine which replication is in error when a two-to-one vote is observed. In this case, the voting circuit canghghj output the correct result, and discard the erroneous version. After this, the internal state of the erroneous replication is assumed to be different from that of the other two, and the voting circuit can switch to a DMR mode. This model can be applied to any larger number of replications.
Lockstep fault tolerant machines are most easily made fully synchronous, with each gate of each replication making the same state transition on the same edge of the clock, and the clocks to the replications being exactly in phase. However, it is possible to build lockstep systems without this requirement.
Bringing the replications into synchrony requires making their internal stored states the same. They can be started from a fixed initial state, such as the reset state. Alternatively, the internal state of one replica can be copied to another replica.
One variant of DMR is pair-and-spare. Two replicated elements operate in lockstep as a pair, with a voting circuit that detects any mismatch between their operations and outputs a signal indicating that there is an error. Another pair operates exactly the same way. A final circuit selects the output of the pair that does not proclaim that it is in error. Pair-and-spare requires four replicas rather than the three of TMR, but has been used commercially.
No single point of repair
If a system experiences a failure, it must continue to operate without interruption during the repair process.
Fault isolation to the failing component
When a failure occurs, the system must be able to isolate the failure to the offending component. This requires the addition of dedicated failure detection mechanisms that exist only for the purpose of fault isolation.
Recovery from a fault condition requires classifying the fault or failing component. The National Institute of Standards and Technology (NIST) categorizes faults based on Locality, Cause, Duration and Effect.
Fault containment
Some failure mechanisms can cause a system to fail by propagating the failure to the rest of the system. An example of this kind of failure is the "Rogue transmitter" which can swamp legitimate communication in a system and cause overall system failure. Mechanisms that isolate a rogue transmitter or failing component to protect the system are required.
See also
- Byzantine fault tolerance
- Intrusion tolerance
- Capillary routing
- Cluster (computing)
- Control reconfiguration
- Defence in depth
- Data redundancy
- Elegant degradation
- Error detection and correction
- Fail-safe
- Fail soft
- Failure transparency[clarification needed]
- fall back and forward
- Fault-tolerant design
- Fault-tolerant computer systems
- Progressive Enhancement
- Separation of protection and security
- Rollback
- Resilience (ecology)
- Resilience (network)
- List of system quality attributes
Bibliography
- Brian Randell, P.A. Lee, P. C. Treleaven (June 1978). "Reliability Issues in Computing System Design". ACM Computing Surveys (CSUR) 10 (2): 123–165. doi:10.1145/356725.356729. ISSN 0360-0300. http://portal.acm.org/citation.cfm?id=356729&coll=&dl=ACM&CFID=15151515&CFTOKEN=6184618.
- P. J. Denning (December 1976). "Fault tolerant operating systems". ACM Computing Surveys (CSUR) 8 (4): 359–389. doi:10.1145/356678.356680. ISSN 0360-0300. http://portal.acm.org/citation.cfm?id=356680&dl=ACM&coll=&CFID=15151515&CFTOKEN=6184618.
- Theodore A. Linden (December 1976). "Operating System Structures to Support Security and Reliable Software". ACM Computing Surveys (CSUR) 8 (4): 409–445. doi:10.1145/356678.356682. ISSN 0360-0300. http://portal.acm.org/citation.cfm?id=356682&coll=&dl=ACM&CFID=15151515&CFTOKEN=6184618.
External links
- Article "Practical Considerations in Making CORBA Services Fault-Tolerant" by Priya Narasimhan
- Article about TMR with reference to TMR usage in avionics and industry
- Article "Experiences, Strategies and Challenges in Building Fault-Tolerant CORBA Systems" by Pascal Felber and Priya Narasimhan
- Dependability And Its Threats: A Taxonomy by Algirdas Avizienis, Jean-Claude Laprie, B. Randell
- EU funded research project HPC4U addressing development of fault tolerant technologies for Grid computing environments
- Fault Tolerance and High Availability Systems
- High Availability Software
- Graceful Degradation in the RKBExplorer
- Fault Tolerance and High Availability Systems for Check Point Firewall and VPN networks with Resilience line of FCR appliances
Categories:- Fault tolerance
- Computer systems
- Software systems
- Control engineering
- Systems engineering
- Software quality
- RAID
- Fault-tolerant computer systems
Wikimedia Foundation. 2010.