- OpenXL
-
OpenXL Original author(s) Originates from a thesis by D. Markus at Royal Institute of Technology and Tokyo Institute of Technology Developer(s) Currently developed at Karolinska Institutet Operating system Cross-platform Type API Website www.openxl.org OpenXL is a programming standard facilitating the utilization of multiple processing elements in a computer system. It is a standard free to use and it is managed with a non-profit intent.
Contents
Background
In 1996 the company SRC Computers, Inc. was established in Colorado Springs, Colorado by Seymour Cray; also known as the founder of the supercomputing company Cray Inc. At that time SRC Computers, Inc. was one of the first companies focusing on reconfigurable computing integrating reconfigurable processing elements into classical CPU computers. The intention was to speed up specific calculations orders of magnitudes compared to what the CPU could perform and at the same time still offer the ease of programming that CPUs give. In 2004 Cray Inc. released their XD1 system with reconfigurable computing, and in 2005 Silicon Graphics, Inc. unveiled their new technology Reconfigurable Application-Specific Computing[1] (RASC) which was based on the same idea. Also graphics card manufacturers have started to offer solutions to run calculations on their hardware, as for instance NVidia marketed their product Tesla[2] as General Purpose computing on GPUs (GPGPU).
A number of hardware manufacturers have seen the potential of application-specific hardware and the challenge has been to create programming tools to facilitate the use of these technologies. OpenXL evolved as one such tool to offer users with multiple processing elements be able to utilize all available hardware in the system. Instead of forcing the user to choose only one particular solution, the philosophy was to allow inclusion of whatever hardware was desired and let the system's scheduler utilize that best possible.
Introduction
In high-performance computing there is often several ways to solve a task. There may be different computing hardware available and there may be a couple of alternative algorithms to solve the problem in question. To be able to solve a scientific problem, a number of competences are involved. A suggestion of such competences are, but not limited to, following.
- Principal investigator / Scientist
- Mathematician
- Algorithm designer
- Parallel computing designer
- Hardware designer (when using reconfigurable computing)
It is impossible for one person to possess all these competences. Therefore, the normal way for a scientist to solve a problem is to use already optimized tools as, for instance, mathematical libraries like BLAS or LAPACK. The major problem is that even though these libraries are highly optimized they may not be compatible with new hardware solutions. Another troublesome scenario using ordinary libraries is when someone has discovered a better algorithm for one particular function dealing with input data of a certain form (an example is Shell sort). In such situation it is not trivial to transparently substitute the original function in the library. These situations form a many-to-many relationship where the scientist has to make qualified decisions and choose between different hardware and different algorithms, when in fact, the only thing sought is to run a certain function as fast as possible.
OpenXL was designed to facilitate this situation with many-to-many relations, allowing multiple hardware and multiple algorithms for one same function.
Design
The OpenXL standard is a design pattern with commonalities with the strategy pattern, and it focuses on the semantics of functions. The main intent is to relief the programmer from knowing how the function is performed, as this may not be in the programmer's field of knowledge. This idea of abstraction is nothing new and is practiced in programming by means of, for instance, APIs. However, the API specifications are seldom the same between different libraries implementing the same function, so the programmer still has to make a decision what API to use. Even though the APIs would be the same, when the programmer links the application to a final executable program, decisions must be made of which libraries shall be used. These link-time decisions mean that only one implementation may serve a particular function during run-time.
Standards and Operations
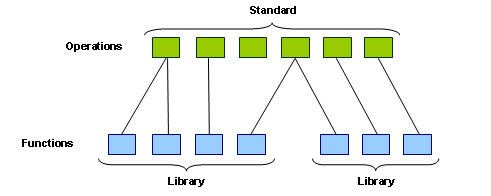
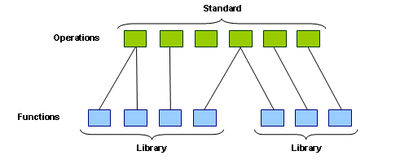 Figure 1. Decoupling layer between functions and operations.
Figure 1. Decoupling layer between functions and operations.
In OpenXL the idea of libraries with functions has been extended to a construction of standards with operations as illustrated in Figure 1. The user's interface has moved from the function declaration to the operation declaration, and the implementer's interface stays by the function declaration. Now the user uses standards instead of libraries, and operations instead of functions. Anyone can create a standard and share it. To create a standard the only thing needed is a world unique text string identifier. The suggested naming convention is similar to the naming convention of Java packages. An example of a standard identifier could be "org.ifff.mathStandard".
Operations are related to the standard. The operations are also defined with just a label, and this label must be unique too, but only within the standard. In C/C++ the operation label could look like this.
#define MATRIX_MULT 4711For the operations the emphasis is on the semantics. The input- and output data to the operation must be clearly defined since anyone is allowed to implement one or more operations in the standard. An organization focusing on semantics is The Numerical Mathematics Consortium[3]
Multiple Operation Definitions
The idea of multiple operation definitions explains the whole concept of OpenXL. Figure 1 also illustrates how the operations are decoupled from the functions. The reconnection allows for multiple functions to be connected to a single operation. During link-time it is allowed to have one and only one definition (object code) for each function, but with the decoupling layer in Figure 1 it is allowed to have multiple definitions for each operation. Now there is no need for a scientist to choose what particular brand of library to use, she can use all libraries available conforming to the standard she has chosen.
Engine
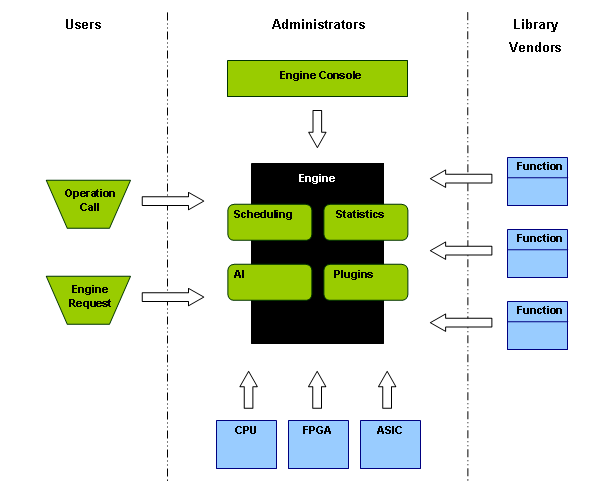
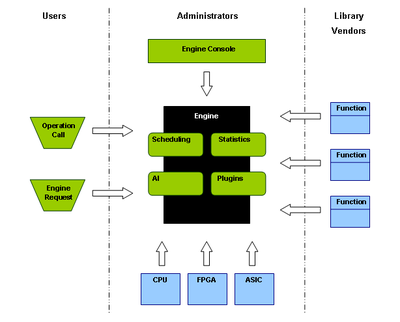 Figure 2. Engine supervising the utilization of hardware and efficient algorithms.
Figure 2. Engine supervising the utilization of hardware and efficient algorithms.The engine is the central part. Here is where the run-time decision is made what function to run when an operation is called, but it also serves a number of other purposes. Figure 2 illustrates the engine and its components. At the top of the figure there are three different groups involved in processing calculations. The Users are developers using various libraries to create programming code that will solve a particular problem. The Library Vendors are the various vendors or organizations creating helping libraries, e.g. mathematical libraries. These two groups are the common groups today solving problems numerically. The third group; Administrators, is a group supervising the engine and its services.
In this figure all the arrows have slightly different meanings. The arrow from Engine Console shows that a control- and monitor system can be connected to supervise the engine. The arrow from Operation Call is the operation call as explained earlier under Standards and Operations. The Engine Request shows that it is possible also for the user application to interact with the engine. The arrows from Functions simply say that several implementations can be registered with the engine as described previously. The arrows in the bottom show that different kinds of hardware can be connected and utilized by the engine. Within the engine there are green rounded rectangles representing examples of various services that the engine could provide.
Example
The C/C++ syntax for calling operations is simple and inspired from Bjarne Stroustrup's union example[4] and SGI's OpenML[5].
#define MATRIX_MULT 4711 int main( int argc, char* argv[] ) { XLstdid mathStd; XLlibid myLib; XLversion stdVersion; XLversion myLibVersion; if( xlOpen( NULL ) != XL_STATUS_NO_ERROR ) { fprintf( stderr, "Failed to open engine\n" ); return 1; } stdVersion.release = 2; stdVersion.revision = 7; if( xlGetStd( "org.ifff.mathStd", &stdVersion, &mathStd ) != XL_STATUS_NO_ERROR ) { fprintf( stderr, "Couldn’t find standard\n" ); return 1; } myLibVersion.release = 1; myLibVersion.revision = 0; if( xlCreateLib( "com.my.lib", &myLibVersion, &myLib ) != XL_STATUS_NO_ERROR ) { fprintf( stderr, "Couldn’t create library\n" ); return 1; } if( xlRegDef( myLib, mathStd, MATRIX_MULT, "My Matrix Mult", enhancedMatrixMult ) != XL_STATUS_NO_ERROR ) { fprintf( stderr, "Couldn’t register\n" ); return 1; } runCalculation( mathStd ); if( xlClose() != XL_STATUS_NO_ERROR ) { fprintf( stderr, "Failed to close engine\n" ); return 1; } return 0; } XLstatus enhancedMatrixMult( XLpd* args, XLpd* results ) { /* Implementation not shown */ /* If successful... */ return XL_STATUS_NO_ERROR; } void runCalculation( XLstdid mathStd ) { XLpd matrixes[7]; XLpd result[4]; XLint32 A[3] = { 4, 7, 11 }; XLint32 B[5] = { 14, 21, 8, 45, 10 }; XLint32 C[15]; matrixes[0].parameter = MATRIX_A_DATA; matrixes[0].data.pInt32 = A; matrixes[0].size = 3; matrixes[1].parameter = MATRIX_A_COLUMNS; matrixes[1].data.int32 = 1; matrixes[2].parameter = MATRIX_A_ROWS; matrixes[2].data.int32 = 3; matrixes[3].parameter = MATRIX_B_DATA; matrixes[3].data.pInt32 = B; matrixes[3].size = 5; matrixes[4].parameter = MATRIX_B_COLUMNS; matrixes[4].data.int32 = 5; matrixes[5].parameter = MATRIX_B_ROWS; matrixes[5].data.int32 = 1; matrixes[6].parameter = XL_END; result[0].parameter = MATRIX_C_DATA; result[0].data.pInt32 = C; result[0].maxSize = 15; result[1].parameter = MATRIX_C_COLUMNS; result[2].parameter = MATRIX_C_ROWS; result[3].parameter = XL_END; if( xlOp( mathStd, MATRIX_MULT, matrixes, result ) != XL_STATUS_NO_ERROR ) { fprintf( stderr, "Failed to run operation\n" ); return; } for( int i = 0; i < result[2].data.int32; i++ ) { for( int j = 0; j < result[1].data.int32; j++ ) printf( "%d ", C[ i*result[1].data.int32 + j ] ); printf( "\n" ); } }
References
- ^ "SGI — Reconfigurable Application-Specific Computing". http://www.sgi.com/company_info/newsroom/press_releases/2005/september/rasc.html. Retrieved 2005-09-30.
- ^ "NVidia — Tesla". http://www.nvidia.com/object/tesla_computing_solutions.html.
- ^ "The Numerical Mathematics Consortium". http://www.nmconsortium.org.
- ^ Stroustrup, Bjarne (2000). The C++ Programming Language (3rd ed.). Addison-Wesley. p. 841. ISBN 0-201-88954-4.
- ^ "SGI — OpenML". http://www.khronos.org/openml/.
External links
Categories:- Computer programming tools
Wikimedia Foundation. 2010.