- Distributed data flow
-
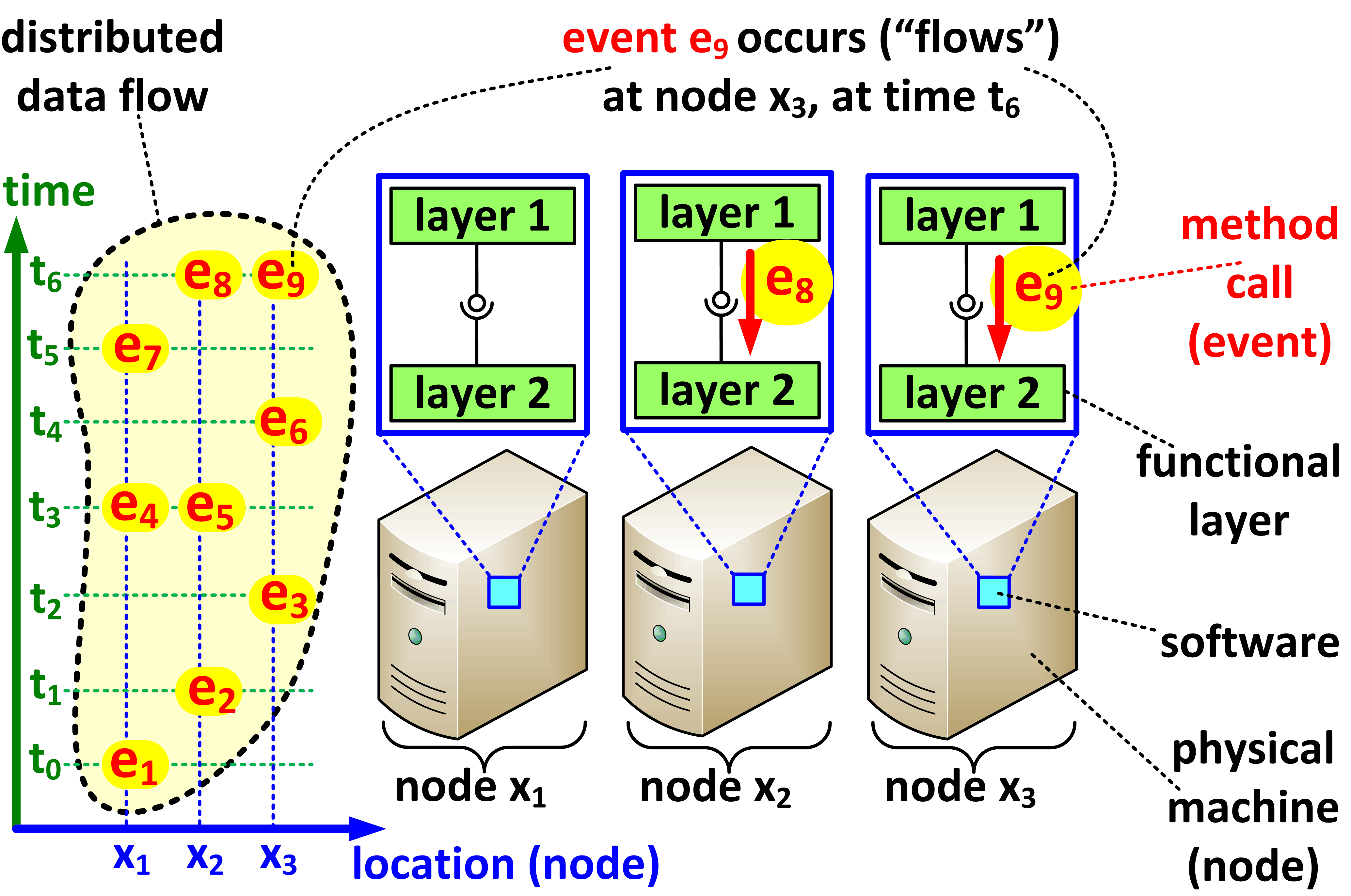
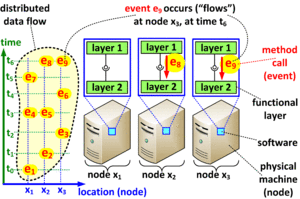 An illustration of the basic concepts involved in the definition of a distributed data flow.
An illustration of the basic concepts involved in the definition of a distributed data flow.
Distributed data flow (also abbreviated as distributed flow) refers to a set of events in a distributed application or protocol that satisfies the following informal properties:
- Asynchronous, non-blocking, and one-way. Each event represents a single instance of a non-blocking, one-way, asynchronous method invocation or other form of explicit or implicit message passing between two layers or software components. For example, each event might represent a single request to multicast a packet, issued by an application layer to an underlying multicast protocol. The requirement that events are one-way and asynchronous is important. Invocations of methods that may return results would normally be represented as two separate flows: one flow that represents the requests, and another flow that represents responses.
- Homogeneous, unidirectional, and uniform. All events in the distributed flow serve the same functional and logical purpose, and are related to one-another; generally, we require that they represent method calls or message exchanges between instances of the same functional layers, or instances of the same components, but perhaps on different nodes within a computer network. Furthermore, all events must flow in the same direction (i.e., one type of a layer or component always produces, and the other always consumes the events), and carry the same type of a payload. For example, a set of events that includes all multicast requests issued by the same application layer to the same multicast protocol is a distributed flow. On the other hand, a set of events that includes multicast requests made by different applications to different multicast protocols would not be considered a distributed flow, and neither would be a set of events that represent multicast requests as well as acknowledgments and error notifications.
- Concurrent, continuous, and distributed. The flow usually includes all events that flow between the two layers of software, simultaneously at different locations, and over a finite or infinite period of time. Thus, in general, events in a distributed flow are distributed both in space (they occur at different nodes) and in time (they occur at different times). For example, the flow of multicast requests would include all such requests made by instances of the given application on different nodes; normally, such flow would include events that occur on all nodes participating in the given multicast protocol. A flow, in which all events occur at the same node would be considered degenerate.
Formally, we represent each event in a distributed flow as a quadruple of the form (x,t,k,v), where x is the location (e.g., the network address of a physical node) at which the event occurs, t is the time at which this happens, k is a version, or a sequence number identifying the particular event, and v is a value that represents the event payload (e.g., all the arguments passed in a method call). Each distributed flow is a (possibly infinite) set of such quadruples that satisfies the following three formal properties.
- For any finite point in time t, there can be only finitely many events in the flow that occur at time t or earlier. This implies that in which flow, one can always point to the point in time at which the flow originated. The flow itself can be infinite; in such case, at any point in time, eventually a new event will appear in the flow.
- For any pair of events e_1 and e_2 that occur at the same location, if e_1 occurs at an earlier time than e_2, then the version number in e_1 must also be smaller than that of e_2.
- For any pair of events e_1 and e_2 that occur at the same location, if the two events have the same version numbers, they must also have the same values.
In addition to the above, flows can have a number of additional properties.
- Consistency. A distributed flow is said to be consistent if events with the same version always have the same value, even if they occur at different locations. Consistent flows typically represent various sorts of global decisions made by the protocol or application.
- Monotonicity. A distributed flow is said to be weakly monotonic if for any pair of events e_1 and e_2 that occur at the same location, if e_1 has a smaller version than e_2, then e_1 must carry a smaller value than e_2. A distributed flow is said to be strongly monotonic (or simply monotonic) if this is true even for pairs of events e_1 and e_2 that occur at different locations. Strongly monotonic flows are always consistent. They typically represent various sorts of irreversible decisions. Weakly monotonic flows may or may not be consistent.
Distributed data flows serve a purpose analogous to variables or method parameters in programming languages such as Java, in that they can represent state that is stored or communicated by a layer of software. Unlike variables or parameters, which represent a unit of state that resides in a single location, distributed flows are dynamic and distributed: they simultaneously appear in multiple locations within the network at the same time. As such, distributed flows are a more natural way of modeling the semantics and inner workings of certain classes of distributed systems. In particular, the distributed data flow abstraction has been used as a convenient way of expressing the high-level logical relationships between parts of distributed protocols [1] [2] .[3]
References
- ^ Ostrowski, K., Birman, K., Dolev, D., and Sakoda, C. (2009). "Implementing Reliable Event Streams in Large Systems via Distributed Data Flows and Recursive Delegation", 3rd ACM International Conference on Distributed Event-Based Systems (DEBS 2009), Nashville, TN, USA, July 6–9, 2009, http://www.cs.cornell.edu/~krzys/krzys_debs2009.pdf
- ^ Ostrowski, K., Birman, K., and Dolev, D. (2009). "Distributed Data Flow Language for Multi-Party Protocols", 5th ACM SIGOPS Workshop on Programming Languages and Operating Systems (PLOS 2009), Big Sky, MT, USA. October 11, 2009, http://www.cs.cornell.edu/~krzys/krzys_plos2009.pdf
- ^ Ostrowski, K., Birman, K., Dolev, D. (2009). "Programming Live Distributed Objects with Distributed Data Flows", Submitted to the International Conference on Object Oriented Programming, Systems, Languages and Applications (OOPSLA 2009), http://www.cs.cornell.edu/~krzys/krzys_oopsla2009.pdf
Categories:- Network protocols
- Distributed computing architecture
Wikimedia Foundation. 2010.