- Data-centric programming language
-
Data-centric programming language Data-Centric Programming Language defines a category of programming languages where the primary function is the management and manipulation of data. A data-centric programming language includes built-in processing primitives for accessing data stored in sets, tables, lists, and other data structures and databases, and for specific manipulation and transformation of data required by a programming application. Data-centric programming languages are typically declarative and often dataflow-oriented, and define the processing result desired; the specific processing steps required to perform the processing are left to the language compiler. The SQL relational database language is an example of a declarative, data-centric language. Declarative, data-centric programming languages are ideal for data intensive computing applications.
Contents
Background
The rapid growth of the Internet and World Wide Web has led to huge amounts of information available online and the need for Big Data processing capabilities. Business and government organizations create large amounts of both structured and unstructured information which needs to be processed, analyzed, and linked.[1] The storing, managing, accessing, and processing of this vast amount of data represents a fundamental need and an immense challenge in order to satisfy needs to search, analyze, mine, and visualize this data as information.[2] Declarative, data-centric languages are increasingly addressing these problems, because focusing on the data makes these problems much simpler to express.[3]
Computer system architectures such as Hadoop and HPCC which can support data-parallel applications are a potential solution to the terabyte and petabyte scale data processing requirements of data-intensive computing.[4][5] Clusters of commodity hardware are commonly being used to address Big Data problems.[6] The fundamental challenges for Big Data applications and data-intensive computing[7] are managing and processing exponentially growing data volumes, significantly reducing associated data analysis cycles to support practical, timely applications, and developing new algorithms which can scale to search and process massive amounts of data. The National Science Foundation has identified key issues related to data-intensive computing problems such as the programming abstractions including models, languages, and algorithms which allow a natural expression of parallel processing of data.[8] Declarative, data-centric programming languages are well-suited to this class of problems.
Data-centric programming languages provide a processing approach in which applications are expressed in terms of high-level operations on data, and the runtime system transparently controls the scheduling, execution, load balancing, communications, and movement of programs and data across the computing cluster.[9] The programming abstraction and language tools allow the processing to be expressed in terms of data flows and transformations incorporating shared libraries of common data manipulation algorithms such as sorting.
Declarative Data-centric programming languages are inherently adaptable to various forms of distributed computing including clusters and data grids and cloud computing.[10] Using declarative, data-centric programming languages suggest more than just adapting to a new computing capability, it also suggests changes to the thought process of data analysis and design of applications.[11]
Data-centric language examples
SQL is the best known declarative, data-centric programming language and has been in use since the 1980’s and became a de-facto standard for use with relational databases. However, a variety of new system architectures and associated programming languages have been implemented for data-intensive computing, Big Data applications, and large-scale data analysis applications. Most data growth is with data in unstructured form[12] and new processing paradigms with more flexible data models were needed. Several solutions have emerged including the MapReduce architecture pioneered by Google and now available in an open-source implementation called Hadoop used by Yahoo, Facebook, and others and the HPCC system architecture offered by LexisNexis Risk Solutions.
Hadoop Pig
 Figure 1: Sample Pig Latin program [13]
Figure 1: Sample Pig Latin program [13]
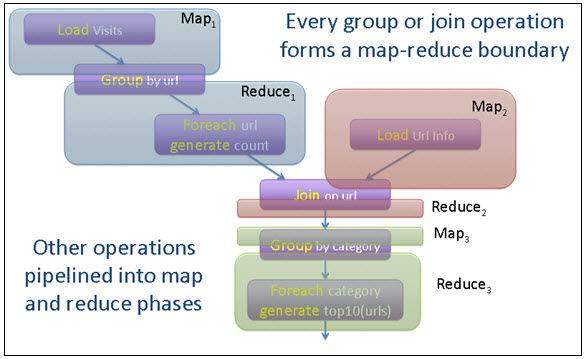
 Figure 2: Pig program translation to MapReduce[13]
Figure 2: Pig program translation to MapReduce[13]Hadoop is an open source software project sponsored by The Apache Software Foundation (http://www.apache.org) which implements the MapReduce architecture. The Hadoop execution environment supports additional distributed data processing capabilities which are designed to run using the Hadoop MapReduce architecture. These include Pig – a high-level data-flow programming language and execution framework for data-intensive computing. Pig was developed at Yahoo! to provide a specific data-centric language notation for data analysis applications and to improve programmer productivity and reduce development cycles when using the Hadoop MapReduce environment. Pig programs are automatically translated into sequences of MapReduce programs if needed in the execution environment. Pig provides capabilities in the language for loading, storing, filtering, grouping, de-duplication, ordering, sorting, aggregation, and joining operations on the data.[13] Figure 1 shows a sample Pig program and Figure 2 shows how this is translated into a series of MapReduce operations.
HPCC ECL
 Figure 3: ECL sample syntax for JOIN operation
Figure 3: ECL sample syntax for JOIN operationThe HPCC data-intensive computing platform from LexisNexis Risk Solutions includes a new high-level declarative, data-centric programming language called ECL. ECL allows the programmer to define what the data processing result should be and the dataflows and transformations that are necessary to achieve the result. The ECL language includes extensive capabilities for data definition, filtering, data management, and data transformation, and provides an extensive set of built-in functions to operate on records in datasets which can include user-defined transformation functions. ECL programs are compiled into optimized C++ source code, which is subsequently compiled into executable code and distributed to the nodes of a processing cluster. ECL combines data representation with algorithm implementation, and is the fusion of both a query language and a parallel data processing language.
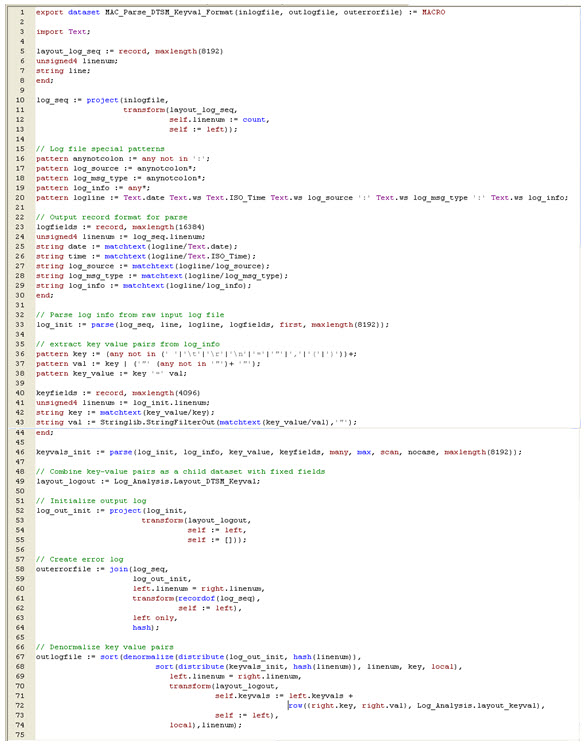
 Figure 5: ECL code example for NLP
Figure 5: ECL code example for NLP Figure 4: ECL code example
Figure 4: ECL code exampleECL includes built-in data transform operations which process through entire datasets including PROJECT, ITERATE, ROLLUP, JOIN, COMBINE, FETCH, NORMALIZE, DENORMALIZE, and PROCESS. For example, the transform function defined for a JOIN operation receives two records, one from each dataset being joined, and can perform any operations on the fields in the pair of records, and returns an output record which can be completely different from either of the input records. Example syntax for the JOIN operation from the ECL Language Reference Manual is shown in Figure 3. Figure 4 shows an example of the equivalent ECL code for the Pig example program shown in Figure 1.
The ECL programming language also provides built-in primitives for Natural language processing (NLP) with PATTERN statements and the built-in PARSE operation. PATTERN statements allow matching patterns including regular expressions to be defined and used to parse information from unstructured data such as raw text. PATTERN statements can be combined to implement complex parsing operations or complete grammars from Backus-Naur Form (BNF) definitions. The PARSE operation operates across a dataset of records on a specific field within a record, this field could be an entire line in a text file for example. Using this capability of the ECL language is possible to implement parallel processing form information extraction applications across document files and all types of unstructured and semi-structured data including XML-based documents or Web pages. Figure 5 shows an example of ECL code used in a log analysis application which incorporates NLP.See Also
- Declarative language
- Big Data
References
- ^ Handbook of Cloud Computing, "Data-Intensive Technologies for Cloud Computing," by A.M. Middleton. Handbook of Cloud Computing. Springer, 2010.
- ^ "Got Data? A Guide to Data Preservation in the Information Age," by F. Berman. Communications of the ACM, Vol. 51, No. 12, 2008, pp. 50-66.
- ^ The Data Centric Gambit, by J. Hellerstein, 2008.
- ^ "A Design Methodology for Data-Parallel Applications," by L.S. Nyland, J.F. Prins, A. Goldberg, and P.H. Mills. Handbook of Cloud Computing. Springer, 2010.
- ^ "The terascale challenge," by D. Ravichandran, P. Pantel, and E. Hovy. Proceedings of the KDD Workshop on Mining for and from the Semantic Web, 2004.
- ^ "BOOM: Data-Centric Programming in the Datacenter," by P. Alvaro, T. Condie, N. Conway, K. Elmeleegy, J. Hellerstein, and R. Sears. Electrical Engineering and Computer Sciences Department, University of California at Berkeley, Technical Report, 2009
- ^ "Data-Intensive Computing in the 21st Century," by I. Gorton, P. Greenfield, A. Szalay, and R. Williams. IEEE Computer, Vol. 41, No. 4, 2008, pp. 30-32
- ^ Data-Intensive Computing, NSF, 2009
- ^ Data Intensive Scalable Computing, by R.E. Bryant, 2008
- ^ Bamboo: A Data-Centric, Object-Oriented Approach to Many-core Software, by J. Zhou, and B. Demsky. Programming Language Design and Implementation, 2010
- ^ "Data-Centric Computing with the Netezza Architecture," by G.S. Davison, K.W. Boyack, R.A. Zacharski, S.C. Helmreich, and J.R. Cowie. Sandia National Laboratories, Technical Report, 2006
- ^ "The Expanding Digital Universe," by J.F. Gantz, D. Reinsel, C. Chute, W. Schlichting, J. McArthur, S. Minton, J. Xheneti, A. Toncheva, and A. Manfrediz. IDC, White Paper, 2007
- ^ a b c Pig latin: A Not-So-Foreign Language for Data Processing, by C. Olston, B. Reed, U. Srivastava, R. Kumar, and A. Tomkins. Stanford University, 2008
Categories:



Wikimedia Foundation. 2010.