- Conditional entropy
-
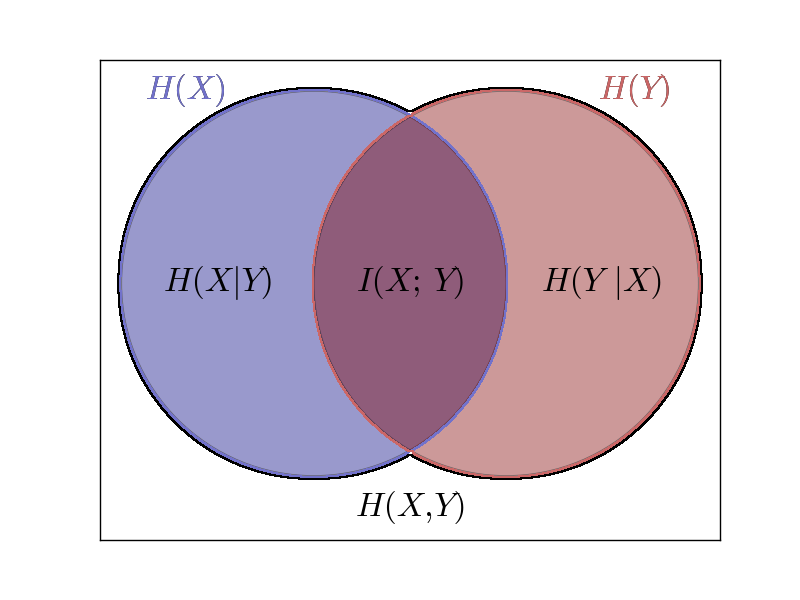
 Individual (H(X),H(Y)), joint (H(X,Y)), and conditional entropies for a pair of correlated subsystems X,Y with mutual information I(X; Y).
Individual (H(X),H(Y)), joint (H(X,Y)), and conditional entropies for a pair of correlated subsystems X,Y with mutual information I(X; Y).
In information theory, the conditional entropy (or equivocation) quantifies the remaining entropy (i.e. uncertainty) of a random variable Y given that the value of another random variable X is known. It is referred to as the entropy of Y conditional on X, and is written H(Y | X). Like other entropies, the conditional entropy is measured in bits, nats, or bans.
Contents
Definition
More precisely, if H(Y | X = x) is the entropy of the variable Y conditional on the variable X taking a certain value x, then H(Y | X) is the result of averaging H(Y | X = x) over all possible values x that X may take.
Given discrete random variable X with support
 and Y with support
and Y with support  , the conditional entropy of Y given X is defined as:
, the conditional entropy of Y given X is defined as:Note: The supports of X and Y can be replaced by their domains if it is understood that 0log0 should be treated as being equal to zero.
Chain rule
From this definition and the definition of conditional probability, the chain rule for conditional entropy is

This is true because

Intuition
Intuitively, the combined system contains H(X,Y) bits of information: we need H(X,Y) bits of information to reconstruct its exact state. If we learn the value of X, we have gained H(X) bits of information, and the system has H(Y | X) bits of uncertainty remaining.
H(Y | X) = 0 if and only if the value of Y is completely determined by the value of X. Conversely, H(Y | X) = H(Y) if and only if Y and X are independent random variables.
Generalization to quantum theory
In quantum information theory, the conditional entropy is generalized to the conditional quantum entropy.
Other properties
For any X and Y:

H(X,Y) = H(X | Y) + H(Y | X) + I(X;Y), where I(X;Y) is the mutual information between X and Y.
 , where I(X;Y) is the mutual information between X and Y.
, where I(X;Y) is the mutual information between X and Y.For independent X and Y:
H(Y | X) = H(Y) and H(X | Y) = H(X)
Although the specific-conditional entropy, H(X | Y = y), can be either lesser or greater than H(X | Y), H(X | Y = y) can never exceed H(X) when X is the uniform distribution.
References
- Theresa M. Korn; Korn, Granino Arthur. Mathematical Handbook for Scientists and Engineers: Definitions, Theorems, and Formulas for Reference and Review. New York: Dover Publications. pp. 613–614. ISBN 0-486-41147-8.
- C. Arndt (2001). Information Measures: Information and its description in Science and Engineering. Berlin: Springer. pp. 370–373. ISBN 3-540-41633-1.
See also
- Entropy (information theory)
- Mutual information
- Conditional quantum entropy
- Variation of information
Categories:- Entropy and information
- Information theory
-

Wikimedia Foundation. 2010.