- Non-standard RAID levels
-
Although all RAID implementations differ from the specification to some extent, some companies have developed non-standard RAID implementations that differ substantially from the standard. Non-RAID drive architectures—configurations of multiple hard drives are not referred to by RAID acronyms.
Contents
Double parity
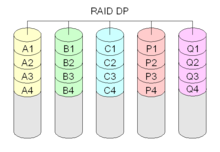 Diagram of a RAID DP (Double Parity) setup.
Diagram of a RAID DP (Double Parity) setup.
Now part of RAID 6, double parity, sometimes known as row diagonal parity,[1] like traditional RAID 6, features two sets of parity checks. Differently, the second set is not another set of points in the over-defined polynomial which characterizes the data. Rather, double parity calculates the extra parity against a different group of blocks.[2] For example, in our graph both RAID 5 and RAID 6 consider all A-labeled blocks to produce one or more parity blocks. However, it is fairly easy to calculate parity against multiple groups of blocks, one can calculate all A blocks and a permuted group of blocks.
This is more easily illustrated using RAID 4, Twin Syndrome RAID 4 (RAID 6 with a RAID 4 layout), and double parity RAID 4.
Traditional Twin Syndrome Double parity RAID 4 RAID 4 RAID 4 A1 A2 A3 Ap A1 A2 A3 Ap Aq A1 A2 A3 Ap 1n B1 B2 B3 Bp B1 B2 B3 Bp Bq B1 B2 B3 Bp 2n C1 C2 C3 Cp C1 C2 C3 Cp Cq C1 C2 C3 Cp 3n D1 D2 D3 Dp D1 D2 D3 Dp Dq D1 D2 D3 Dp 4n Note: A1, B1, et cetera each represent one data block; each column represents one disk.
The n blocks are the double parity blocks. Block 2n is A2 xor B3 xor Cp, while 3n is A3 xor Bp xor C1 and 1n would be calculated as A1 xor B2 xor C3. Because the double parity blocks are correctly distributed it is possible to reconstruct two lost disks through iterative recovery. For example, B2 could be recovered without the use of any x1 or x2 blocks as B3 xor Cp xor 2n = A2, and then A1 can be recovered by A2 xor A3 xor Ap. Finally, B2 = A1 xor C3 xor 1n.
Running in degraded mode with double parity increases risk of data loss.
RAID-DP
RAID-DP[3] implements double parity within RAID 6.[4] The performance penalty of RAID-DP is typically under 2% vs a comparable RAID 4.[5] File system requests are first written to the battery–backed NVRAM to prevent data loss should the system lose power. Blocks are not updated in place. Writes are aggregated and the storage controller tries to write only complete stripes including both parity blocks. RAID-DP provides better protection and equal or better performance than RAID 10, and in most cases doesn't suffer from traditional RAID 6 challenges of in-place block updating and spreads reads and writes over more disks when compared to a RAID 6 group of same size.
RAID 1.5
RAID 1.5 is a proprietary[6] RAID and is sometimes incorrectly called RAID 15. RAID 1.5 performs data striping and mirroring using two hard drives. Data are read from both disks simultaneously and most of the work is done in hardware instead of the driver.
Linux's and Solaris's RAID 1 implementations read from both disks simultaneously, so RAID 1.5 offers no other benefit.
RAID 5E, RAID 5EE and RAID 6E
RAID 5E, RAID 5EE and RAID 6E (with the added E standing for Enhanced) generally refer to variants of RAID 5 or RAID 6 with an integrated hot-spare drive, where the spare drive is an active part of the block rotation scheme. This spreads I/O across all drives, including the spare, thus reducing the load on each drive, increasing performance. It does, however, prevent sharing the spare drive among multiple arrays, which is occasionally desirable.[7]
These systems do not dedicate one drive as the "spare drive", just as RAID 5 or RAID 6 do not dedicate one drive as the "parity drive". Instead, spare blocks are distributed across all drives, so that in a 10-disk RAID 5E with one "spare", every disk is 80% data, 10% parity, and 10% spare. The spare blocks in RAID 5E and RAID 6E are at the end of the array, while in RAID 5EE the spare blocks are integrated into the array. RAID 5EE can sustain a single drive failure. RAID 5EE requires at least four disks and can expand to 16 disks. A drive failure in a RAID 5E/5EE array compresses the array and re-stripes it into a standard RAID 5 array. This process can be very I/O intensive and may take hours or days depending on the speed, size and number of drives. Only after compression can the system prevent data loss given a second drive failure. Replacing the failed drive after compression permits restructuring into a RAID 5E/5EE array. The length of time and intense I/O of both compression and decompression creates a practical limit of 4 to 8 drives. The performance boost diminishes after 8 drives.[citation needed]
Parity RAID
Parity RAID is EMC Corporation's proprietary striped parity RAID system used in their Symmetrix storage systems. The system places each volume on a single physical disk, and arbitrarily combines multiple volumes for parity purposes. EMC originally referred to this capability as RAID S, and then renamed it Parity RAID for the Symmetrix DMX platform. EMC now offers standard striped RAID 5 on the Symmetrix DMX as well.
Traditional EMC RAID 5 RAID S A1 A2 A3 Ap A1 B1 C1 1p B1 B2 Bp B3 A2 B2 C2 2p C1 Cp C2 C3 A3 B3 C3 3p Dp D1 D2 D3 A4 B4 C4 4p
Note: A1, B1, et cetera each represent one data block; each column represents one disk. A, B, et cetera are entire volumes.
Intel Rapid Storage Technology
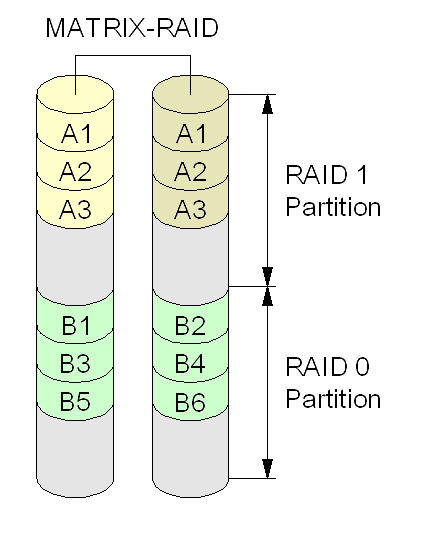
Main article: Intel Rapid Storage Technology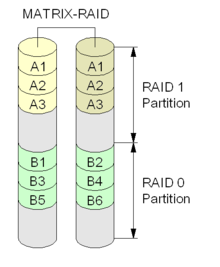 Diagram of a Matrix RAID setup.
Diagram of a Matrix RAID setup.Intel Rapid Storage Technology (formerly called Intel Matrix RAID) is a feature (not a RAID level) present in the ICH6R and subsequent Southbridge chipsets from Intel, accessible via the RAID BIOS. Matrix RAID supports as few as two physical disks or as many as the controller supports. The distinguishing feature of Matrix RAID is that it allows any assortment of RAID 0, 1, 5, and/or 10 volumes in the array, to which a controllable (and identical) portion of each disk is allocated. As such, a Matrix RAID array can improve both performance and data integrity. A practical instance of this would use a small RAID 0 (stripe) for the operating system, program and paging files; and a larger RAID 1 (mirror) to store critical data. Linux MD RAID is also capable of this.
Linux MD RAID 10
The Linux kernel software RAID driver (called md, for "multiple device") can be used to build a classic RAID 1+0 array, but also as a single level[8] with some interesting extensions.[9]
The standard "near" layout, where each chunk is repeated n times in a k-way stripe array, is equivalent to the standard RAID 10 arrangement, but it does not require that n evenly divide k. For example an n2 layout on 2, 3 and 4 drives would look like:
2 drives 3 drives 4 drives -------- ---------- -------------- A1 A1 A1 A1 A2 A1 A1 A2 A2 A2 A2 A2 A3 A3 A3 A3 A4 A4 A3 A3 A4 A4 A5 A5 A5 A6 A6 A4 A4 A5 A6 A6 A7 A7 A8 A8 .. .. .. .. .. .. .. .. ..
The 4-drive example is identical to a standard RAID-1+0 array, while the 3-drive example is a software implementation of RAID-1E. The 2-drive example is equivalent to RAID 1.
The driver also supports a "far" layout where all the drives are divided into f sections. All the chunks are repeated in each section but offset by one device. For example, f2 layouts on 2-, 3-, and 4-drive arrays would look like:
2 drives 3 drives 4 drives -------- -------------- -------------------- A1 A2 A1 A2 A3 A1 A2 A3 A4 A3 A4 A4 A5 A6 A5 A6 A7 A8 A5 A6 A7 A8 A9 A9 A10 A11 A12 .. .. .. .. .. .. .. .. .. A2 A1 A3 A1 A2 A4 A1 A2 A3 A4 A3 A6 A4 A5 A8 A5 A6 A7 A6 A5 A9 A7 A8 A12 A9 A10 A11 .. .. .. .. .. .. .. .. ..
This is designed for striping performance of a mirrored array; sequential reads can be striped, as in RAID-0, random reads are somewhat faster (maybe 10-20 % due to using the faster outer disk sectors, and smaller average seek times), and sequential and random writes offer about equal performance to other mirrored raids. The layout performs well for systems where reads are more frequent than writes, which is common. The first 1/f of each drive is a standard RAID-0 array. This offers striping performance on a mirrored set of only 2 drives.
The near and far options can be used together. The chunks in each section are offset by n device(s). For example n2 f2 layout stores 2×2 = 4 copies of each sector, so requires at least 4 drives:
A1 A1 A2 A2 A1 A1 A2 A2 A3 A3 A3 A4 A4 A3 A4 A4 A5 A5 A5 A5 A6 A6 A6 A6 A7 A7 A8 A7 A7 A8 A8 A8 A9 A9 A10 A10 .. .. .. .. .. .. .. .. .. A2 A2 A1 A1 A2 A3 A1 A1 A2 A4 A4 A3 A3 A5 A5 A3 A4 A4 A6 A6 A5 A5 A7 A8 A6 A6 A7 A8 A8 A7 A7 A10 A10 A8 A9 A9 .. .. .. .. .. .. .. .. ..
The driver also supports an offset layout where each stripe is repeated o times. For example, o2 layouts on 2-, 3-, and 4-drive arrays are laid out as:
2 drives 3 drives 4 drives -------- ------------ ----------------- A1 A2 A1 A2 A3 A1 A2 A3 A4 A2 A1 A3 A1 A2 A4 A1 A2 A3 A3 A4 A4 A5 A6 A5 A6 A7 A8 A4 A3 A6 A4 A5 A8 A5 A6 A7 A5 A6 A7 A8 A9 A9 A10 A11 A12 A6 A5 A9 A7 A8 A12 A9 A10 A11 .. .. .. .. .. .. .. .. ..
Note: k is the number of drives, n#, f# and o# are parameters in the mdadm
--layoutoption.Linux can also create 0, 1, 4, 5, 6 standard RAID configurations using md.
RAID 1E
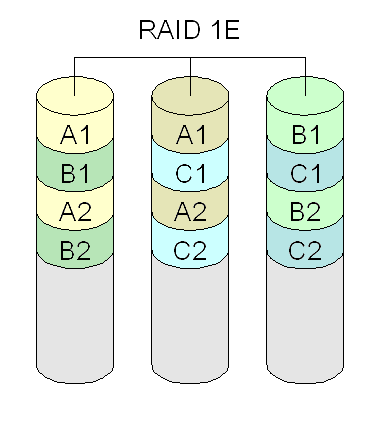
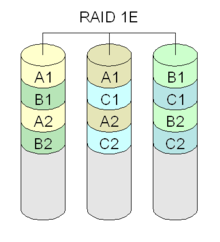 Diagram of a RAID 1E setup.
Diagram of a RAID 1E setup.RAID 1E uses 2-way mirroring on an arbitrary number of drives.[10]
For example, mirroring on 5 drives would look like
A1 A2 A3 A4 A5 A5 A1 A2 A3 A4 B1 B2 B3 B4 B5 B5 B1 B2 B3 B4
This configuration is tolerant of non-adjacent drives failing.[11]
RAID-K
RAID-K is similar to double-parity RAID 4.[12]
RAID-Z
RAID-Z is not actually a kind of RAID, but a higher-level software solution that implements an integrated redundancy scheme similar to RAID 5, using ZFS.[13] RAID-Z avoids the RAID 5 "write hole"[14] using copy-on-write: rather than overwriting data, it writes to a new location and then atomically overwrites the pointer to the old data. It avoids the need for read-modify-write operations for small writes by only ever performing full-stripe writes. Small blocks are mirrored instead of parity protected, which is possible because the file system is aware of the underlying storage structure and can allocate extra space if necessary. RAID-Z2 doubles the parity structure to achieve results similar to RAID 6: the ability to sustain up to two drive failures without losing data.[15][16][17]
Tahoe Distributed File System
Main article: Tahoe Least-Authority FilesystemThe Tahoe Least-Authority Filesystem is an open source, secure, decentralized, fault-tolerant, peer-to-peer filesystem.[18]
Drive Extender
Windows Home Server Drive Extender is a specialized case of JBOD RAID 1 implemented at the file system level.[19] When a file is to be duplicated, a pointer called a tombstone is created on the main storage drive's NTFS partition that points to data residing on other disk(s). When the system is idle, the OS re-balances the storage to provide redundancy while maximizing storage capacity. Although not as robust as true RAID, it provides many of RAID's benefits, including a single hierarchical view of the file system regardless of physical disk location, the ability to swap failed disks without losing redundant data, and seamless background data duplication on the replacement disk.
It is also possible to limit data duplication on a per-share basis. Drive Extender can store files on different disks and use tombstones to point to them, providing faster read access when the end-user requests files located on different disks, similar to RAID 0's speed benefit.
However, Microsoft has announced that Drive Extender will no longer be included as part of Windows Home Server Version 2, Windows Home Server 2011 (codename VAIL).[20] As a result there has been a third-party vendor move to fill the void left by DE. Included competitors are Division M, the developers of Drive Bender, DriveHarnony from DataCore, and StableBit's DrivePool.[21]
BeyondRAID
BeyondRAID is not a true RAID extension, but consolidates up to 10 SATA hard drives into one pool of storage.[22] It has the advantage of supporting multiple disk sizes at once, much like JBOD, while providing redundancy for all disks and allowing a hot-swap upgrade at any time. Internally it uses a mix of techniques similar to RAID 1 and RAID 5. Depending on the fraction of data in relation to capacity, it can survive up to three drive failures, if the "array" can be restored onto the remaining good disks before another drive fails. The amount of usable storage can be approximated by summing the capacities of the disks and subtracting the capacity of the largest disk. For example, if a 500, 400, 200, and 100 GB drive were installed, the approximate usable capacity would be 500+400+200+100+(-500)=700 GB of usable space. Internally the data would be distributed in two RAID 5-like arrays and one RAID 1-like set:
Drives | 100 GB | 200 GB | 400 GB | 500 GB | ---------- | x | unusable space (100 GB) ---------- ------------------- | A1 | A1 | RAID 1 set (2× 100 GB) ------------------- ------------------- | B1 | B1 | RAID 1 set (2× 100 GB) ------------------- ---------------------------- | C1 | C2 | Cp | RAID 5 array (3× 100 GB) ---------------------------- ------------------------------------- | D1 | D2 | D3 | Dp | RAID 5 array (4× 100 GB) -------------------------------------
BeyondRaid offers a RAID 6–like feature and can perform hash-based compression using 160-bit SHA1 hashes to maximize storage efficiency.[23]
UnRAID
UnRAID is best compared with RAID 3/RAID 4, without striping. Data drives are kept in normal reiserfs format, but a 'smart' parity drive emulates the function that striping plays in RAID3 and RAID4 with a specialized data structure. Pointers on the parity drive combine files on the various drives into virtual stripes which then get parity data. Read checksum are checked against the parity checksum (and reconstructed if incorrect.) Writes create new parity information. The main advantages to this approach are: data drives are readable and writeable on any system, separated from their array—the system can fail without harming the array; different-sized drives can be combined; partial recovery is possible if the number of failures exceeds the number of parity disks (usually one).
Based on distributed, unsupported[24] GPL source code, UnRAID is suited to cheap, simple, expandable archival storage, similar to the more extreme write-once, read occasionally use case.
Disadvantages include slower write performance than a single disk, filesystem overhead (additional checksums are required to avoid querying the other disks to check the data disks in use), scaling problems, bottlenecking when multiple drives are written concurrently. UnRaid allows support of a cache drive (Plus and Pro versions) which dramatically speeds up the write performance. The data is temporarily unprotected until UnRaid automatically moves it to the array based on a schedule set within the software. The parity drive must be at least as large as the largest data drive to provide protection. UnRAID is implemented as an add-on to the Linux MD layer.[25]
See also
Notes
- ^ http://www.netapp.com/library/tr/3298.pdf 3298
- ^ Standard RAID levels#RAID 6 implementation
- ^ NetApp RAID-DP enables disk firmware updates to occur in real-time without any outage.[1]
- ^ [2]
- ^ Netapp RAID 4
- ^ HighPoint
- ^ The scheme was introduced by IBM ServeRAID around 2001. xSeries Architecture X-Architecture
- ^ http://neil.brown.name/blog/20040827225440 RAID 10 driver
- ^ Main Page - Linux-raid
- ^ ServeRAID
- ^ Other storage systems including Sun's StorEdge T3 support this mode as well.
- ^ Kaleidescape's KSERVER-5000 and KSERVER-1500 use a proprietary RAID-K in their media storage units.
- ^ Sun's ZFS
- ^ RAID-Z : Jeff Bonwick's Blog
- ^ Adam Leventhal's Weblog
- ^ In July 2009, triple-parity RAID was added to OpenSolaris. Leventhal, Adam. "Bug ID: 6854612 triple-parity RAID-Z". Sun Microsystems. http://bugs.opensolaris.org/bugdatabase/view_bug.do?bug_id=6854612. Retrieved 2009-07-17.
- ^ Leventhal, Adam (2009-07-16). "6854612 triple-parity RAID-Z". zfs-discuss mailing list. http://mail.opensolaris.org/pipermail/onnv-notify/2009-July/009872.html. Retrieved 2009-07-17.
- ^ [3]
- ^ Separate from Windows' Logical Disk Manager
- ^ http://www.theregister.co.uk/2010/11/25/vail_drive_extender_ditched/
- ^ http://www.wegotserved.com/2011/10/10/drive-bender-public-release-arriving-week/
- ^ Data Robotics, Inc. implements BeyondRaid in their Drobostorage device.
- ^ Detailed technical information about BeyondRaid, including how it handles adding and removing drives, is: US US20070266037
- ^ Enthusiasts frequent AVS Forums and a wiki
- ^ LimeTech
Categories:
Wikimedia Foundation. 2010.