- Coefficient of determination
-
In statistics, the coefficient of determination R2 is used in the context of statistical models whose main purpose is the prediction of future outcomes on the basis of other related information. It is the proportion of variability in a data set that is accounted for by the statistical model.[1] It provides a measure of how well future outcomes are likely to be predicted by the model.
There are several different definitions of R2 which are only sometimes equivalent. One class of such cases includes that of linear regression. In this case, if an intercept is included then R2 is simply the square of the sample correlation coefficient between the outcomes and their predicted values, or in the case of simple linear regression, between the outcomes and the values of the single regressor being used for prediction. In such cases, the coefficient of determination ranges from 0 to 1. Important cases where the computational definition of R2 can yield negative values, depending on the definition used, arise where the predictions which are being compared to the corresponding outcomes have not been derived from a model-fitting procedure using those data, and where linear regression is conducted without including an intercept. Additionally, negative values of R2 may occur when fitting non-linear trends to data.[2] In these instances, the mean of the data provides a fit to the data that is superior to that of the trend under this goodness of fit analysis.
Contents
Definitions
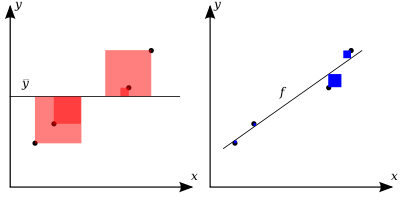


The better the linear regression (on the right) fits the data in comparison to the simple average (on the left graph), the closer the value of R2 is to one. The areas of the blue squares represent the squared residuals with respect to the linear regression. The areas of the red squares represent the squared residuals with respect to the average value.A data set has values yi, each of which has an associated modelled value fi (also sometimes referred to as ŷi). Here, the values yi are called the observed values and the modelled values fi are sometimes called the predicted values.
The "variability" of the data set is measured through different sums of squares:
 the total sum of squares (proportional to the sample variance);
the total sum of squares (proportional to the sample variance);
 the regression sum of squares, also called the explained sum of squares.
the regression sum of squares, also called the explained sum of squares.
 , the sum of squares of residuals, also called the residual sum of squares.
, the sum of squares of residuals, also called the residual sum of squares.
In the above
 is the mean of the observed data:
is the mean of the observed data:where n is the number of observations.
The notations SSR and SSE should be avoided, since in some texts their meaning is reversed to Residual sum of squares and Explained sum of squares, respectively.
The most general definition of the coefficient of determination is
Relation to unexplained variance
In a general form, R2 can be seen to be related to the unexplained variance, since the second term compares the unexplained variance (variance of the model's errors) with the total variance (of the data). See fraction of variance unexplained.
As explained variance
In some cases the total sum of squares equals the sum of the two other sums of squares defined above,
See sum of squares for a derivation of this result for one case where the relation holds. When this relation does hold, the above definition of R2 is equivalent to
In this form R2 is given directly in terms of the explained variance: it compares the explained variance (variance of the model's predictions) with the total variance (of the data).
This partition of the sum of squares holds for instance when the model values ƒi have been obtained by linear regression. A milder sufficient condition reads as follows: The model has the form
where the qi are arbitrary values that may or may not depend on i or on other free parameters (the common choice qi = xi is just one special case), and the coefficients α and β are obtained by minimizing the residual sum of squares.
This set of conditions is an important one and it has a number of implications for the properties of the fitted residuals and the modelled values. In particular, under these conditions:
As squared correlation coefficient
Similarly, after least squares regression with a constant+linear model (i.e., simple linear regression), R2 equals the square of the correlation coefficient between the observed and modeled (predicted) data values.
Under general conditions, an R2 value is sometimes calculated as the square of the correlation coefficient between the original and modeled data values. In this case, the value is not directly a measure of how good the modeled values are, but rather a measure of how good a predictor might be constructed from the modeled values (by creating a revised predictor of the form α + βƒi). According to Everitt (2002, p. 78), this usage is specifically the definition of the term "coefficient of determination": the square of the correlation between two (general) variables.
Interpretation
R2 is a statistic that will give some information about the goodness of fit of a model. In regression, the R2 coefficient of determination is a statistical measure of how well the regression line approximates the real data points. An R2 of 1.0 indicates that the regression line perfectly fits the data.
Values of R2 outside the range 0 to 1 can occur where it is used to measure the agreement between observed and modelled values and where the "modelled" values are not obtained by linear regression and depending on which formulation of R2 is used. If the first formula above is used, values can never be greater than one. If the second expression is used, there are no constraints on the values obtainable.
In many (but not all) instances where R2 is used, the predictors are calculated by ordinary least-squares regression: that is, by minimizing SSerr. In this case R-squared increases as we increase the number of variables in the model (R2 will not decrease). This illustrates a drawback to one possible use of R2, where one might try to include more variables in the model until "there is no more improvement". This leads to the alternative approach of looking at the adjusted R2. The explanation of this statistic is almost the same as R2 but it penalizes the statistic as extra variables are included in the model. For cases other than fitting by ordinary least squares, the R2 statistic can be calculated as above and may still be a useful measure. If fitting is by weighted least squares or generalized least squares, alternative versions of R2 can be calculated appropriate to those statistical frameworks, while the "raw" R2 may still be useful if it is more easily interpreted. Values for R2 can be calculated for any type of predictive model, which need not have a statistical basis.
In a linear model
Consider a linear model of the form
where, for the ith case, Yi is the response variable,
 are p regressors, and εi is a mean zero error term. The quantities
are p regressors, and εi is a mean zero error term. The quantities  are unknown coefficients, whose values are determined by least squares. The coefficient of determination R2 is a measure of the global fit of the model. Specifically, R2 is an element of [0, 1] and represents the proportion of variability in Yi that may be attributed to some linear combination of the regressors (explanatory variables) in X.
are unknown coefficients, whose values are determined by least squares. The coefficient of determination R2 is a measure of the global fit of the model. Specifically, R2 is an element of [0, 1] and represents the proportion of variability in Yi that may be attributed to some linear combination of the regressors (explanatory variables) in X.R2 is often interpreted as the proportion of response variation "explained" by the regressors in the model. Thus, R2 = 1 indicates that the fitted model explains all variability in y, while R2 = 0 indicates no 'linear' relationship (for straight line regression, this means that the straight line model is a constant line (slope=0, intercept=
) between the response variable and regressors). An interior value such as R2 = 0.7 may be interpreted as follows: "Approximately seventy percent of the variation in the response variable can be explained by the explanatory variable. The remaining thirty percent can be explained by unknown, lurking variables or inherent variability."A caution that applies to R2, as to other statistical descriptions of correlation and association is that "correlation does not imply causation." In other words, while correlations may provide valuable clues regarding causal relationships among variables, a high correlation between two variables does not represent adequate evidence that changing one variable has resulted, or may result, from changes of other variables.
In case of a single regressor, fitted by least squares, R2 is the square of the Pearson product-moment correlation coefficient relating the regressor and the response variable. More generally, R2 is the square of the correlation between the constructed predictor and the response variable.
Inflation of R2
In least squares regression, R2 is weakly increasing in the number of regressors in the model. As such, R2 alone cannot be used as a meaningful comparison of models with different numbers of independent variables. For a meaningful comparison between two models, an F-test can be performed on the residual sum of squares, similar to the F-tests in Granger causality. As a reminder of this, some authors denote R2 by R2p, where p is the number of columns in X
To demonstrate this property, first recall that the objective of least squares regression is:
The optimal value of the objective is weakly smaller as additional columns of X are added, by the fact that relatively unconstrained minimization leads to a solution which is weakly smaller than relatively constrained minimization. Given the previous conclusion and noting that SStot depends only on y, the non-decreasing property of R2 follows directly from the definition above.
The intuitive reason that using an additional explanatory variable cannot lower the R2 is this: Minimizing SSerr is equivalent to maximizing R2. When the extra variable is included, the data always have the option of giving it an estimated coefficient of zero, leaving the predicted values and the R2 unchanged. The only way that the optimization problem will give a non-zero coefficient is if doing so improves the R2.
Notes on interpreting R2
R² does not indicate whether:
- the independent variables are a true cause of the changes in the dependent variable;
- omitted-variable bias exists;
- the correct regression was used;
- the most appropriate set of independent variables has been chosen;
- there is collinearity present in the data on the explanatory variables;
- the model might be improved by using transformed versions of the existing set of independent variables.
Adjusted R2
Adjusted R2 (often written as
 and pronounced "R bar squared") is a modification due to Theil[3] of R2 that adjusts for the number of explanatory terms in a model. Unlike R2, the adjusted R2 increases only if the new term improves the model more than would be expected by chance. The adjusted R2 can be negative, and will always be less than or equal to R2. The adjusted R2 is defined as
and pronounced "R bar squared") is a modification due to Theil[3] of R2 that adjusts for the number of explanatory terms in a model. Unlike R2, the adjusted R2 increases only if the new term improves the model more than would be expected by chance. The adjusted R2 can be negative, and will always be less than or equal to R2. The adjusted R2 is defined aswhere p is the total number of regressors in the linear model (but not counting the constant term), n is the sample size, dft is the degrees of freedom n– 1 of the estimate of the population variance of the dependent variable, and dfe is the degrees of freedom n – p – 1 of the estimate of the underlying population error variance.
The principle behind the Adjusted R2 statistic can be seen by rewriting the ordinary R2 as
where VARerr = SSerr / n and VARtot = SStot / n are estimates of the variances of the errors and of the observations, respectively. These estimates are replaced by statistically unbiased versions: VARerr = SSerr / (n − p − 1) and VARtot = SStot / (n − 1).
Adjusted R2 does not have the same interpretation as R2. As such, care must be taken in interpreting and reporting this statistic. Adjusted R2 is particularly useful in the Feature selection stage of model building..
The use of an adjusted R2 is an attempt to take account of the phenomenon of statistical shrinkage.[4]
Generalized R2
Nagelkerke (1991) generalizes the definition of the coefficient of determination:
- A generalized coefficient of determination should be consistent with the classical coefficient of determination when both can be computed;
- Its value should also be maximised by the maximum likelihood estimation of a model;
- It should be, at least asymptotically, independent of the sample size;
- Its interpretation should be the proportion of the variation explained by the model;
- It should be between 0 and 1, with 0 denoting that model does not explain any variation and 1 denoting that it perfectly explains the observed variation;
- It should not have any unit.
The generalized R² has all of these properties.
where L(0) is the likelihood of the model with only the intercept,
 is the likelihood of the estimated model and n is the sample size.
is the likelihood of the estimated model and n is the sample size.However, in the case of a logistic model, where
 cannot be greater than 1, R² is between 0 and
cannot be greater than 1, R² is between 0 and  : thus, it is possible to define a scaled R² as R²/R²max.[5]
: thus, it is possible to define a scaled R² as R²/R²max.[5]See also
- Goodness of fit
- Fraction of variance unexplained
- Pearson product-moment correlation coefficient
- Nash–Sutcliffe model efficiency coefficient (hydrological applications)
- Regression model validation
- Proportional reduction in loss
- Root mean square deviation
- Multiple correlation
Notes
- ^ Steel, R. G. D. and Torrie, J. H., Principles and Procedures of Statistics, New York: McGraw-Hill, 1960, pp. 187, 287.
- ^ Cameron, A.C., Windmeijer, F.A.G., (1997)."An R-squared measure of goodness of fit for some common nonlinear regression models." Journal of Econometrics, Volume 77, Issue 2, April 1997, Pages 329-342.
- ^ Theil, Henri (1961). Economic Forecasts and Policy. Holland, Amsterdam: North.
- ^ Everitt, B.S. (2002) The Cambridge Dictionary of Statistics, CUP. ISBN 0-521-81099-x (See entries for "Shrinkage", "Shrinkage formulae")
- ^ N. Nagelkerke, "A Note on a General Definition of the Coefficient of Determination," Biometrika, vol. 78, no. 3, pp. 691–692, 1991.
References
- Draper, N.R. and Smith, H. (1998). Applied Regression Analysis. Wiley-Interscience. ISBN 0-471-17082-8
- Everitt, B.S. (2002). Cambridge Dictionary of Statistics (2nd Edition). CUP. ISBN 0-521-81099-x
- Nagelkerke, Nico J.D. (1992) Maximum Likelihood Estimation of Functional Relationships, Pays-Bas, Lecture Notes in Statistics, Volume 69, 110p ISBN 0-387-97721-X.
- Glantz, S.A. and Slinker, B.K., (1990). Primer of Applied Regression and Analysis of Variance. McGraw-Hill. ISBN 0-07-023407-8.
Categories:- Regression analysis
- Statistical ratios
- Statistical terminology
- Least squares












Wikimedia Foundation. 2010.