- Persistent data structure
-
In computing, a persistent data structure is a data structure which always preserves the previous version of itself when it is modified; such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead always yield a new updated structure. (A persistent data structure is not a data structure committed to persistent storage, such as a disk; this is a different and unrelated sense of the word "persistent.")
A data structure is partially persistent if all versions can be accessed but only the newest version can be modified. The data structure is fully persistent if every version can be both accessed and modified. If there is also a meld or merge operation that can create a new version from two previous versions, the data structure is called confluently persistent. Structures that are not persistent are called ephemeral.[1]
These types of data structures are particularly common in logical and functional programming, and in a purely functional program all data is immutable, so all data structures are automatically fully persistent.[1] Persistent data structures can also be created using in-place updating of data and these may, in general, use less time or storage space than their purely functional counterparts.
While persistence can be achieved by simple copying, this is inefficient in time and space, because most operations make only small changes to a data structure. A better method is to exploit the similarity between the new and old versions to share structure between them, such as using the same subtree in a number of tree structures. However, because it rapidly becomes infeasible to determine how many previous versions share which parts of the structure, and because it is often desirable to discard old versions, this necessitates an environment with garbage collection.
Contents
Examples of persistent data structures
Perhaps the simplest persistent data structure is the singly linked list or cons-based list, a simple list of objects formed by each carrying a reference to the next in the list. This is persistent because we can take a tail of the list, meaning the last k items for some k, and add new nodes on to the front of it. The tail will not be duplicated, instead becoming shared between both the old list and the new list. So long as the contents of the tail are immutable, this sharing will be invisible to the program.
Many common reference-based data structures, such as red-black trees,[2] and queues,[3] can easily be adapted to create a persistent version. Some other like Stack, Double-ended queues (dequeue), Min-Dequeue (which have additional operation min returning minimal element in constant time without incurring additional complexity on standard operations of queuing and dequeuing on both ends), Random access list (with constant cons/head as single linked list, but with additional operation of random access with sub-linear, most often logarithmic, complexity), Random access queue, Random access double-ended queue and Random access stack (as well Random access Min-List, Min-Queue, Min-Dequeue, Min-Stack) needs slightly more effort.
There exists also persistent data structures which uses destructible operations (thus impossible to implement efficiently in the purely functional languages like Haskell, however possible in languages like C, Java), they are however not needed, as most data structures are currently available in pure versions which are often simpler to implement, and often behaves better in multi-threaded environments.
Linked lists
This example is taken from Okasaki. See the bibliography.
Singly linked lists are the bread-and-butter data structure in functional languages. In ML-derived languages and Haskell, they are purely functional because once a node in the list has been allocated, it cannot be modified, only copied or destroyed. Note that ML itself is not purely functional.
Consider the two lists:
xs = [0, 1, 2] ys = [3, 4, 5]
These would be represented in memory by:
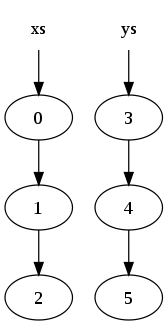
where a circle indicates a node in the list (the arrow out showing the second element of the node which is a pointer to another node).
Now concatenating the two lists:
zs = xs ++ ys
results in the following memory structure:
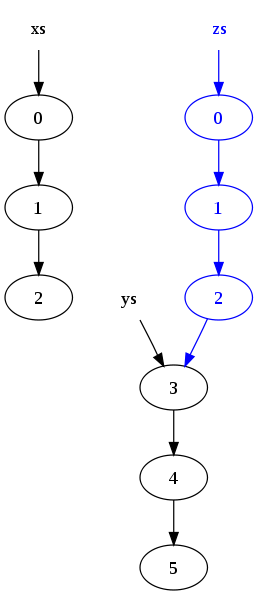
Notice that the nodes in list
xshave been copied, but the nodes inysare shared. As a result, the original lists (xsandys) persist and have not been modified.The reason for the copy is that the last node in
xs(the node containing the original value2) cannot be modified to point to the start ofys, because that would change the value ofxs.Trees
This example is taken from Okasaki. See the bibliography.
Consider a binary tree used for fast searching, where every node has the recursive invariant that subnodes on the left are less than the node, and subnodes on the right are greater than the node.
For instance, the set of data
xs = [a, b, c, d, f, g, h]
might be represented by the following binary search tree:
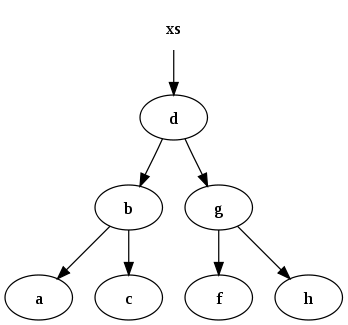
A function which inserts data into the binary tree and maintains the invariant is:
fun insert (x, E) = T (E, x, E) | insert (x, s as T (a, y, b)) = if x < y then T (insert (x, a), y, b) else if x > y then T (a, y, insert (x, b)) else sAfter executing
ys = insert ("e", xs)we end up with the following:
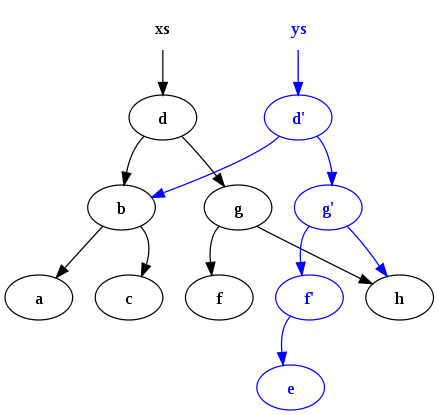
Notice two points: Firstly the original tree (
xs) persists. Secondly many common nodes are shared between the old tree and the new tree. Such persistence and sharing is difficult to manage without some form of garbage collection (GC) to automatically free up nodes which have no live references, and this is why GC is a feature commonly found in functional programming languages.Reference cycles
Since every value in a purely functional computation is built up out of existing values, it would seem that it is impossible to create a cycle of references. In that case, the reference graph (the graph of the references from object to object) could only be a directed acyclic graph. However, in most functional languages, functions can be defined recursively; this capability allows recursive structures using functional suspensions. In lazy languages, such as Haskell, all data structures are represented as implicitly suspended thunks; in these languages any data structure can be recursive because a value can be defined in terms of itself. Some other languages, such as Objective Caml, allow the explicit definition of recursive values.
See also
References
- ^ a b Kaplan, Haim (2001). "Persistent data structures". Handbook on Data Structures and Applications (CRC Press). http://www.math.tau.ac.il/~haimk/papers/persistent-survey.ps.
- ^ Neil Sarnak, Robert E. Tarjan (1986). "Planar Point Location Using Persistent Search Trees". Communications of the ACM 29 (7): 669–679. doi:10.1145/6138.6151. http://www.link.cs.cmu.edu/15859-f07/papers/point-location.pdf.
- ^ Chris Okasaki. Purely Functional Data Structures (thesis). http://www.cs.cmu.edu/~rwh/theses/okasaki.pdf.
Further reading
- Persistent Data Structures and Managed References - video presentation by Rich Hickey on Clojure's use of persistent data structures and how they support concurrency
- Making Data Structures Persistent by James R. Driscoll, Neil Sarnak, Daniel D. Sleator, Robert E. Tarjan
- Fully persistent arrays for efficient incremental updates and voluminous reads
- Real-Time Deques, Multihead Turing Machines, and Purely Functional Programming
- Purely functional data structures by Chris Okasaki, Cambridge University Press, 1998, ISBN 0-521-66350-4.
- Purely Functional Data Structures thesis by Chris Okasaki (PDF format)
- Fully Persistent Lists with Catenation by James R. Driscoll, Daniel D. Sleator, Robert E. Tarjan (PDF)
- Persistent Data Structures from MIT open course Advanced Algorithms
External links
Categories:- Data structures
- Functional data structures
- Persistence




Wikimedia Foundation. 2010.