- 2 Base Encoding
The dream of human genome re-sequencing within a reasonable time and cost (less than $1000) is becoming realized with recently developed next-generation sequencing technologies. These technologies generate hundreds of thousands of small sequence reads at one time. Well-known examples of such
DNA sequencing methods include 454pyrosequencing (introduced in 2005), the Solexa system (introduced in 2006) and the SOLiD(TM) System(introduced in 2007). These methods have reduced the cost from $0.01/base in 2004 to nearly $0.0001/base in 2006 and increased the sequencing capacity from 1,000,000 bases/machine/day in 2004 to more than 100,000,000 bases/machine/day in 2006.General features
The general steps common to all of these next-generation sequencing techniques include:
# Random fragmentation of genomic DNA
# Immobilization of single DNA fragments on a solid support like a bead or a planar solid surface
# Amplification of DNA fragments on the solid surface using PCR and making polymerase colonies
# Sequencing and subsequent in situ interrogation after each cycle using fluorescence scanning or chemiluminescence [MATTHEW E. HUDSON (2008) Sequencing breakthroughs for genomic ecology and evolutionary biology. Molecular Ecology Resources 8 (1) , 3–17] .In 2005, Shendure "et al." performed a sequencing procedure using multiple cycles of ligation of fluorescent labeled 9-mer probes which distinguished the central base. In each cycle, the sequence of every fifth base was recognized. This process was repeated using different primers to sequence the remaining four bases in each gap [Jay Shendure et al. (2005) Accurate Multiplex Polony Sequencing of an Evolved Bacterial Genome. Sciene 309(5741) , 1728 - 1732] . The most recent next-generation sequencing technology, which is called 2-base encoding or SOLiD (Sequencing by Oligonucleotide Ligation and Detection), has been developed by Applied Biosystem and will be commercially available in 2008. Similar to Shendure "et al.", 2-base encoding is based on ligation sequencing rather than sequencing by synthesis. However, instead of using fluorescent labeled 9-mer probes that distinguish the central base, 2-base encoding takes advantage of fluorescent labeled 8-mer probes that distinguish the 2 central bases. The technique is described by McKernan, Blanchard, Kotler and Costa. [ [http://www.wipo.int/pctdb/en/wo.jsp?wo=2006084132 Article: Reagents,Methods and Libraries for Bead-Based Sequencing] ] and Valouev et al [ [http://www.genome.org/cgi/reprint/gr.076463.108v1.pdf Article: A high-resolution, nucleosome position map of C. elegans reveals a lack of universal...] ] and Cloonan et al [ [http://www.nature.com/nmeth/journal/v5/n7/abs/nmeth.1223.html Article: Stem cell transcriptome profiling via massive-scale mRNA sequencing] ]
How it works

thumb|200px|right|Figure 1- Schematic feature of four different probes used in 2 base encoding.The SOLiD Sequencing System uses probes with dual base encoding.The underlying chemistry is summarized in the following steps [ [http://marketing.appliedbiosystems.com Applied Biosystems ] ] :
- Step 1, Preparing a Library: This step begins with shearing the genomic DNA into small fragments. Then, two different adapters are added (for example A1 and A2). The resulting library contains template DNA fragments, which are tagged with one adapter at each end (A1-template-A2).
- Step 2, Emulsion PCR: In this step, the emulsion (droplets of water suspended in oil) PCR reaction is performed using DNA fragments from library, two primers (P1 and P2) that complement to the previously used adapters (P1 with A1 and P2 with A2), other PCR reaction components and 1μm beads coupled with one of the primers (e.g. P1). The aim is locating one DNA template and one bead into a single emulsion droplet.
In each droplet, DNA template anneals to the P1-coupled bead from its A1 side. Then DNA polymerase will extend from P1 to make the complementary sequence, which eventually results in a bead enriched with PCR products from a single template. After PCR reaction, templates are denatured and disassociate from the beads.
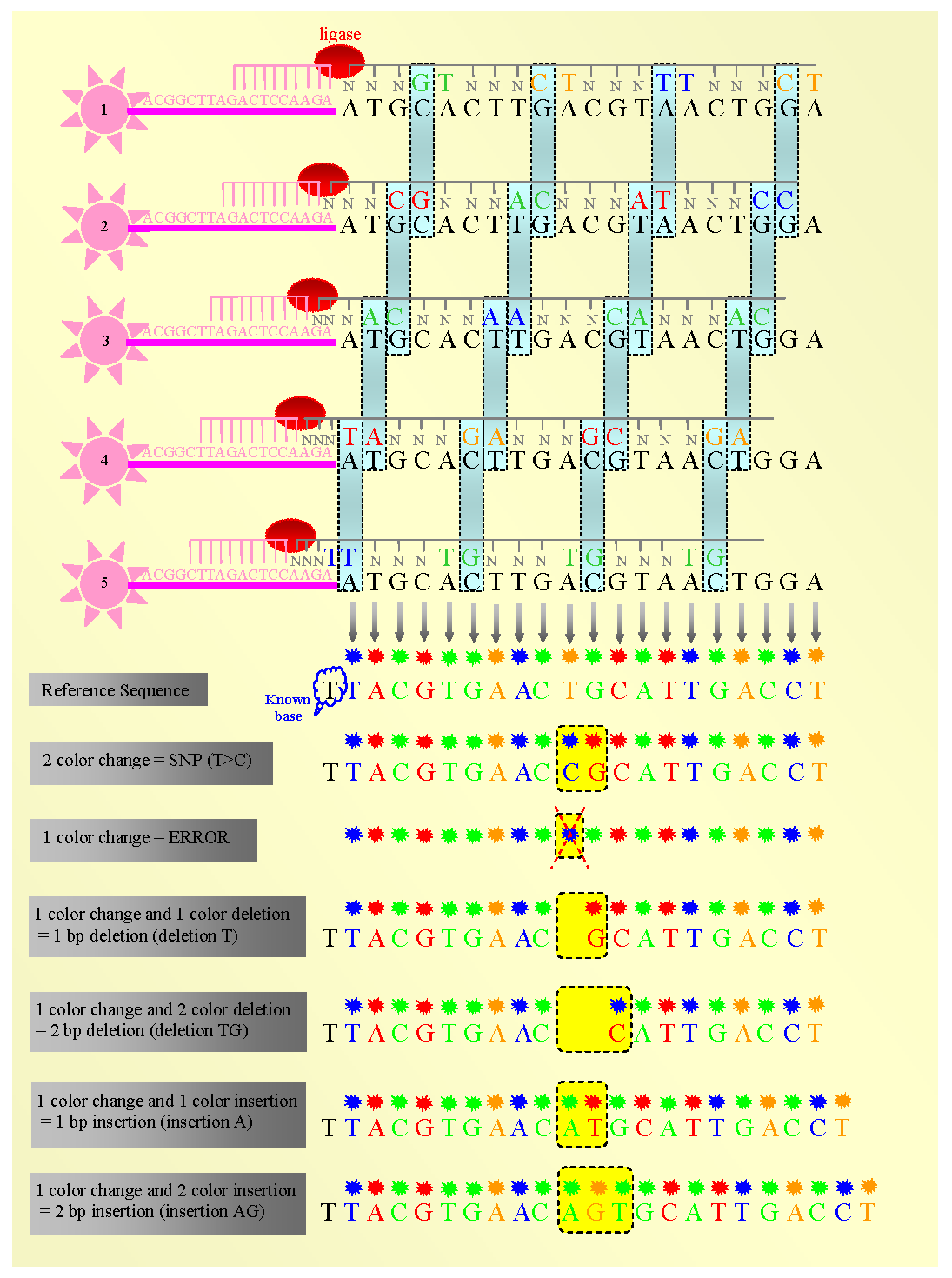
thumb|200px|right|Figure 2- Schematic feature of how the 2-base encoding system works. Each base pair in the sequence is read twice and enables this system to minimize the rate of errors.- Step 3, Bead Enrichment: In practice, only 30% of beads have target DNA. To increase the number of beads that have target DNA, large polystyrene beads coated with A2 are added to the solution. Thus, any bead containing the extended products will bind polystyrene bead through its P2 end. The resulting complex will be separated from untargeted beads, and melt off to dissociate the targeted beads from polystyrene. This step can increase the throughput of this system from 30% before enrichment to 80% after enrichment.After enrichment, the 3’-end of products (P2 end) will be modified which makes them capable of covalent bonding in the next step. Therefore, the products of this step are DNA-coupled beads with 3’-modification of each DNA strand.
- Step 4, Bead Deposition: In this step, products of the last step are deposited onto a glass slide. Beads attach to the glass surface randomly through covalent bonds of the 3’-modified beads and the glass.
- Step 5, Sequencing Reaction: As mentioned earlier, unlike other next-generation methods which perform sequencing through synthesis, 2-base encoding is based on sequencing by ligation. The ligation is performed using specific 8-mer probes:
These probes consist of eight bases (Figure 1) with a ligation site at the 3’ end, a fluorescent dye at the 5’ end and a cleavage site between the fifth and sixth nucleotide; the first three nucleotides are degenerate bases (N) which can be any of the four nucleotide bases (i.e., A,C,T, or G). The last three nucleotides (Z) are universal bases which can pair with any of the four nucleotide bases. The remaining two bases, the fourth and fifth, are the basis of 2-base encoding. The combination of these adjacent dinucleotides will make sixteen different probes which according to limitations of fluorescent dyes are classified into four groups (Figure 1). Therefore, each fluorescent dye represents a class of four different probes. In general, calculating all the possibilities, there will be 1024 octamer probes, 4 dyes each representing 4 dinucleotides, and 256 probes per dye.
The sequencing step is basically composed of five rounds and each round consists of about 5-7 cycles (Figure 2). Each round begins with the addition of a P1-complementary universal primer. This primer has, for example, n nucleotides and its 5’-end matches exactly with the 3’-end of the P1. In each cycle, 8-mer probes (1024 probes) are added and ligated according to their fourth and fifth bases. Then, the remaining unbound probes are washed out, the fluorescent signal from the bound probe is measured, and the bound probe is cleaved between its fifth and sixth nucleotide. Finally the primer and probes are all reset for the next round.
In the next round a new universal primer anneals the position n-1 (its 5’-end matches to the base exactly before the 3’-end of the P1) and the subsequent cycles are repeated similar to the first round. The remaining three rounds will be performed with new universal primers annealing positions n-2, n-3 and n-4 relative to the 3'-end of P1. A complete reaction of five rounds allows the sequencing of about 25 base pairs of the template from P1.
- Step 6, Decoding Data: For decoding the data, which are represented as colors, we must first know two important factors. First, we must know that each color indicates two bases. Second, we need to know one of the bases in the sequence: this base is incorporated in the sequence in the last (fifth) round of step5. This known base is the last nucleotide of the 3’-end of the known P1. Therefore, since each color represents two nucleotides in which the second base of each dinucleotide unit constitutes the first base of the following dinucleotide, knowing just one base in the sequence will lead us to interpret the whole sequence(Figure 2). [ [http://seqanswers.com/forums/showthread.php?t=10 Tech Summary: ABI's SOLiD (Seq. by Oligo Ligation/Detection) - SEQanswers ] ]
Advantages
Each base in this sequencing method is read twice. This changes the color of two adjacent color space calls, therefore in order to miscall a SNP, two adjacent colors must be miscalled. Because of this the SNP miscall rate is on the order of e^2, where e is the device error rate.
Disadvantages
When base calling single color miscalls cause errors on the remaining portion of the read. In SNP calling this can be corrected, which results in a lower SNP calling error rate. However for de novo assembly you are left with the raw device error rate which will significantly higher than the 99.94% reported for SNP calling.
ee also
*
DNA sequencing
*Sequencing by ligation
*Single Molecule Real Time Sequencing References
External links
*http://www.454.com
*http://www.solexa.com
*http://www.appliedbiosystems.com
Wikimedia Foundation. 2010.